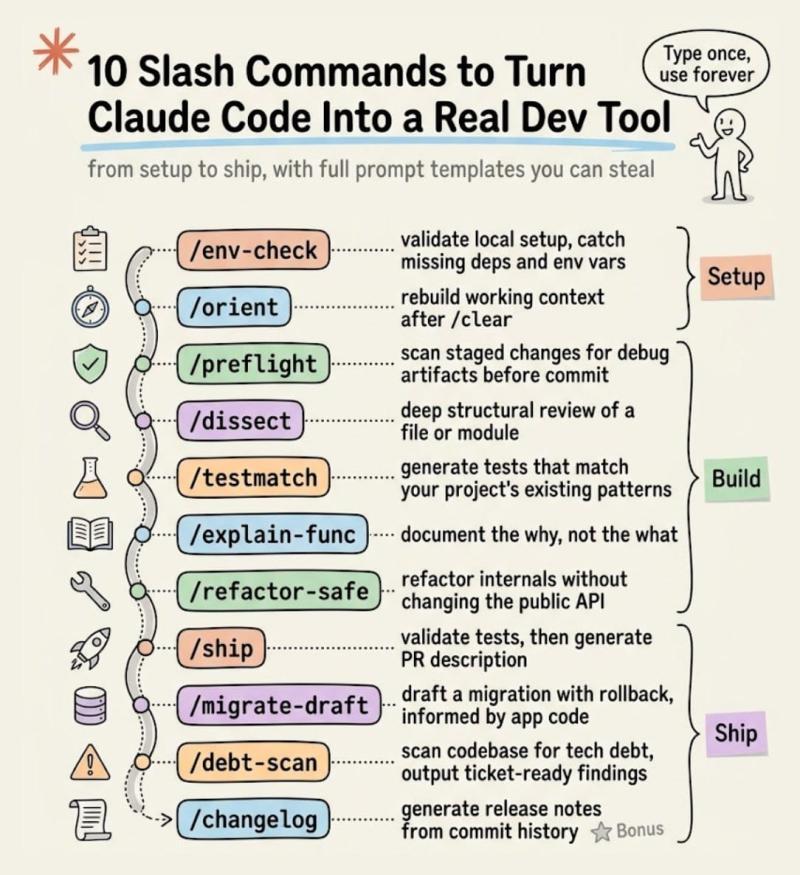
这篇文章给你一套“两层系统”,能让你运行的每一个 AI 智能体都变得更聪明。搭建只要 20 分钟,之后会每天自动进化,而且完全开源。
Karpathy 最近提到,他已经把大部分 token 花费,从“写代码”转移到了“知识管理”上。
这篇帖子之所以引发共鸣,是因为它点中了一个所有人都在感受的问题:
你的 AI 智能体根本不了解你。
每次对话都从零开始。你一遍遍解释自己的业务、语气、目标和上下文,最后得到的输出当然很通用——因为输入没有记忆。
我照着他的思路,花了两周测试了多种方案,最后简化出一套真正好用的版本,并把自己的数据全部喂进去:笔记、想法、推文、文章、书签……
AI 智能体从这些原始材料里,编译出了 230+ 篇结构化 wiki 页面,按概念、实体、来源交叉链接,我可以随时查询。
(此处原文为推文截图与图片,略)
这篇文章会讲清楚:
- 什么是“AI 知识层”(knowledge layer)
- 如何为内容创作、公司运营和个人生活各搭一套
- 开源框架怎么用,20 分钟完成初始搭建
什么是 AI 知识层
AI 知识层,是你和所有 AI 智能体之间的“基础设施”。
它是智能体在做任何事之前,必须先读的东西。
没有它,智能体只能猜。有了它,智能体才“知道”。
这个知识层由两部分组成:
-
知识库层(KBL, Knowledge Base Layer)
这是动态的。你把各种原始资料丢进一个文件夹:推文、文章、书签、PDF、笔记、语音备忘录……AI 智能体会:
- 读完所有内容
- 按类型分类每个来源
- 生成结构化的 wiki 页面,并加上交叉引用
- 维护一个带一行摘要的总索引,方便快速扫一眼
你问的每一个问题,都会被存成一篇新页面,反过来喂给知识库。Wiki 会随时间不断变厚。
-
品牌基石(BF, Brand Foundation)
这是静态的,只由你亲自编辑。包括:- 你的语气规则
- 视觉风格
- 品牌定位
- 目标受众
- 永远不用的词和表达
智能体在产出任何内容前,都会先读它,但永远不会改写它。它是锚点,保证即便是 AI 在干活,输出依然像你本人写的。
这两层在系统中的位置,大致是这样:
+-------------------------------------------------------+
| YOUR AGENTS |
| (writer, researcher, strategist, analyst) |
+---------------------------+---------------------------+
| reads from | reads from
v v
+------------------+ +-------------------+
| KNOWLEDGE BASE | | BRAND FOUNDATION |
| LAYER (KBL) | | (BF) |
| | | |
| dynamic | | static |
| agent-maintained| | human-edited |
| grows over time | | your voice, your |
| wiki pages, | | rules, your |
| sources, index | | positioning |
+--------+---------+ +-------------------+
|
compiles from
|
+--------+---------+
| raw/ inbox |
| tweets, articles|
| bookmarks, PDFs |
| notes, ideas |
+------------------+
为什么不是传统 RAG?
传统 RAG(检索增强生成)是在查询时临时把文档切块、向量检索,再现算答案。
知识层的思路是:
- 先由智能体离线编译一次
- 建好交叉引用和结构
- 持续增量更新
Karpathy 的经验是:当规模到 100 篇左右文章时,这种“编译式”知识库,在问答效果上开始明显优于 RAG。
Graphify 的测试数据也显示:
相比直接在原始文件上检索,每次查询 token 消耗减少 71.5 倍。
整个演进大致经历了三阶段:
- 2020–2023:一次性 RAG
- 2023–2024:多跳检索的 Agentic RAG
- 2025+:上下文工程(context engineering)——智能体自己从多源构建上下文,知识层就是这第三阶段的基础设施。
为什么大多数人不会去搭
原因和“周日备菜”一样:
- 你花 1 小时提前准备,可以省掉一整周 10 小时的麻烦
- 但大多数人宁愿抱怨 AI 输出很烂,也不愿花 20 分钟搭一个能根本改善质量的系统
现在 90% 的 AI 使用方式都是:
随便一问 → 接受结果 → 直接发出
没有审美,没有判断。
知识层,是你离开这 90% 的方法。
它把你的审美、数据和模式编码进去,让智能体产出的东西:
- 听起来像你写的
- 而不是任何一个“AI 汤文”账号都能发出来的东西
当然,门槛也是真实存在的:你必须筛选输入。
如果某个内容对你当前关注的方向,相关度不到 80%,就别往里丢。
高信号输入,才会有高质量输出。你喂进去的是噪音,出来的也只会是噪音。
对内容创作者和个人品牌的价值
我最先在内容这块落地这套系统。
我运营一个 AI 营销内容账号和一家代理机构,需要智能体:
- 知道我写过什么
- 知道什么内容表现好
- 知道我的语气和观点
于是我做了一个框架叫 LLM Wikid,并开源了(后面会讲怎么用)。把自己的数据灌进去之后,发生了这些事:
-
先花一段时间,把脑子里的东西全部写出来:
- 正在做的项目
- 半成品产品想法
- 细分领域里正在起效的玩法
- 对 AI 营销未来的判断
不管结构,只管“把脑子倒出来”。
-
然后把 X 的推文归档(6 周 87 条)、3 篇已发文章、所有书签一起丢进去。
智能体处理完后,生成了:- 15 个主题化的来源页面
- 14 个概念页面
- 11 个实体页面
- 100+ 条交叉链接
-
接着通过 X API 拉了 197 条书签,智能体:
- 下载了 81 张图片
- 转写了 49 个视频
- 分析了视觉内容
- 把这些全部织进 wiki
最后效果是:
我的笔记、想法、推文、书签、文章,全都被连接起来,统一可检索。
(此处原文为 Obsidian 图谱截图说明,略)
两层系统在实际中的分工
1. KBL:承载一切“会增长的东西”
知识库层里存放的是:
- 所有来源,按类型分类(转录、文章、推文、论文……)
- 通过 wiki 链接交叉引用
- 每页都有 TL;DR 摘要,方便快速扫
当我要写某个主题时,我会运行 /wiki-query:
- 得到一个带引用来源的回答
- 这份回答会被存成一篇新页面
- 下次再问相关问题,答案会更丰富
一个典型的目录结构大概是这样:
my-wiki/
raw/
clippings/ # Obsidian Web Clipper 丢进来的网页剪藏
ideas/ # 笔记、头脑风暴、半成品想法
bookmarks/ # 收藏的推文、长帖、工具
articles/ # 你自己发布过的内容
papers/ # PDF、研究论文
x-archive/ # X/Twitter 导出的归档
assets/images/ # 从来源下载的媒体
wiki/
index.md # 总索引 + TL;DR
log.md # 只追加的变更日志
concepts/ # 概念、框架、主题
ai-marketing.md
distribution-moat.md
entities/ # 人物、公司、工具
karpathy.md
claude-superpowers.md
sources/ # 每个原始来源一页摘要
graphify-2026.md
outputs/ # 对查询的回答归档
sops/ # 可复用流程
syntheses/ # 跨主题综合分析
templates/ # 各类页面模板
CLAUDE.md # 控制一切的 schema 说明
注意 raw/ 下面的 clippings/:这是 Obsidian Web Clipper 的落地点。
你装好浏览器扩展后,在 X、文章、GitHub、Reddit 上看到有价值的内容,一键剪藏:
- 自动保存到
raw/clippings/ - 在 frontmatter 里带上原始 URL
下一次你运行 /wiki-ingest 时,智能体会:
- 读取 URL
- 判断来源类型(推文、文章、PDF、视频……)
- 移动到对应子文件夹
- 抓取完整内容
- 下载图片
- 编译进 wiki
白天你只管剪藏,晚上跑一遍 ingest,第二天醒来,知识库就更厚了一层。
2. BF:承载一切“不会变的东西”
品牌基石里放的是那些相对稳定的规则:
- 一份“AI 味检测清单”:所有一看就像 AI 写的禁用词、句式、结构
- 视觉内容风格指南:比如“终端截图 + 漂亮背景”“颜色编码的流程图”等
- 你的语气画像:用词、节奏、态度
每一个智能体在输出前,都会先读这些文件。
智能体如何接入这套系统
-
写作智能体:
- 先读品牌基石,锁定语气
- 再查询 wiki 做主题研究
- 结合内容表现数据,选择合适的内容形式
-
研究智能体:
- 监控 X、Reddit、YouTube 等渠道
- 把新信号源丢进 raw 文件夹
- 扩展已有 wiki 主题
-
内容策略智能体:
- 对比细分领域里表现好的内容
- 和现有覆盖做差距分析
- 找出内容空白和机会点
每个智能体的上限,都由它读的知识层决定。
同一个智能体:
- 读一个“很薄”的知识库,只能产出平庸内容
- 读 200+ 篇结构化 wiki,里面全是你的语气、数据和历史表现,就能写出“像你本人写的东西”
我做过直接对比:
Helena 是一个 AI 营销工具,只给它一个网站 URL,它就能:
- 把品牌读得很准
- 生成一整套品牌语气画像
但基于这些分析生成的内容,在我看来就是:
“一分钟生成一个月的营销废文”。
光有品牌分析还不够,你还需要上面这层知识层。
(此处原文有多条推文与头像图片)

和“5 个层级的 AI 营销”怎么对应
这套知识层,正好对应我之前写过的“AI 营销 5 个层级”:
- Level 1:只会写自定义提示词(没有知识层)
- Level 2:手动堆技能(很薄的知识层)
- Level 3:技能 + 品牌基石(加上 BF)
- Level 4:有技能的智能体,读编译好的知识(KBL + BF 一起工作)
- Level 5:多智能体自治团队,共享一个可复利的知识层
现在大多数人停在 1、2 层。
而知识层,是你迈向 4、5 层的关键。
(此处原文有推文与头像图片)
分发视角:知识层是“分发护城河”
“vibe coding” 已经把“做产品”这件事变得很简单:
几乎任何人都能在 48 小时内做出一个 app。
真正难的,还是分发。
知识层,是你积累“分发智能”的方式:
- 每一条内容洞察
- 每一个认真分析过的书签
- 每一项表现数据
都会让下一篇内容:
- 目标更精准
- 形式更合适
你可以设一个定时任务,每天早上跑一次 ingest:
昨天你剪藏的东西,今天一早就变成了结构化情报,你的分发系统在你睡觉时变聪明。
这背后还有一个服务机会:
- 帮别人搭一套知识层系统,是一个 $1,500–3,000 的一次性项目
- 再加 $300–500 / 月的维护费
10 个客户,一年就是大约 $56,800。
如果你是内容创作者或代理机构,这完全可以产品化。
公司和项目怎么用同一套架构
同样的架构,可以直接放大到公司级别。
区别在于:
- 不再是一个人的智能体
- 而是多个人的智能体,共同读写同一个知识层
- 知识层里存的,也不只是内容,而是运营知识
我们在 EspressioAI 和 Lunar Strategy 都在跑类似的系统:
-
在 Espressio:
- 知识库里有客户交付模式
- 智能体架构模板
- 内部 SOP
-
在 Lunar Strategy:
- 存的是活动打法手册
- 客户研究
- 内容框架
新成员入职,只要把自己的智能体指向这套知识库:
第一天就能产出,而不是花几周摸索“公司里真正的做事方式”。
Eric Osiu 在整家公司也做了类似的事:
- 每个员工都有一个按角色调优的 AI 智能体
- 所有智能体共享一个“中央大脑”
他的总结是:
“一个个人助理有天花板。真正的解锁,是按角色调优的智能体,通过一个中央大脑共享上下文。”
- 销售一旦签单,客户成功的智能体已经拿到完整交接
- 某条内容表现很好,销售智能体会自动调整外联话术
没有信息会“掉地上”,因为知识层会接住一切。
(此处原文有多条推文与文章封面截图,略)
如何随组织一起扩展
从一个人,到小团队(5–10 人共享一个知识库),再到组织(50+ 人,每人一个角色智能体,统一读编译好的情报),底层模式其实完全一样:
- 原始资料不断流入 raw/
- 智能体把它们编译成结构化页面
- 交叉引用自动生成
- 人类通过“探索关卡”做验证:
- 每个页面初始状态都是
explored: false - 只有人类看过、确认后,才标记为已验证
- 每个页面初始状态都是
- 用 Git 同步所有内容:
- 知识有版本控制
- 出错可以回滚
Cody Schneider 为本地服务型企业,搭了一套 10 能力的 GTM 智能体集群:
- 底座是一个数据仓库,装着所有业务数据
- 他的话是:
“没有这个底座,智能体做不出好决策。”
他叫它 data warehouse。
Eric 叫它 shared brain。
Karpathy 叫它 LLM wiki。
名字不重要,重要的是:智能体需要编译好的结构化知识,才能做有用的工作。
最极端的版本,是 Greg Isenberg 说的“ambient businesses”:
主要由智能体驱动的公司,老板几天看一次就行。
Medvi 就是现实案例:
- 年化营收 18 亿美金
- 2 名员工
- 0 风投
AI 负责:
- 代码
- 创意
- 语音
- 客服
前提依然是:
有一层扎实的知识层。
没有它,智能体就要人类不断下指令;有了它,智能体可以在“组织智慧”上自主运转。
(此处原文有 Medvi 相关推文与 NYT 链接,略)
个人生活:最被低估的用法
同一套系统,也可以用来追踪你的思考和生活:
- 日记
- 读书笔记
- 播客摘录
- 健康指标
- 目标复盘
- 凌晨两点的随机灵感
全部丢进 raw/,让智能体编译成结构化页面。
然后你可以问:
- “我最近精力水平有什么模式?”
- “上个季度我在生产力上学到了什么?”
得到的都是:
- 基于你自己数据的回答
- 带引用来源
- 回答本身也会被存回 wiki,让下一次提问更聪明
这是一个复利回路:
你问的每一个问题,都会让系统更丰富;
你加的每一个来源,都会创造新的连接。
因此,质量控制在这里尤其重要:
-
偏见检查:
- 每页都要强制写反方观点和数据缺口
- 如果你只丢了 10 篇观点一致的文章进去,wiki 会记录这一点,并标出“缺失的视角”
-
验证关卡:
- 每个 AI 生成的页面初始都是
explored: false - 只有你看过、确认后,才标记为已审阅
- 你始终知道哪些内容是“人类确认过的”,哪些还没有
- 每个 AI 生成的页面初始都是
-
置信度标签:
- 每页都会被标记为高 / 中 / 低 / 不确定
- 智能体必须诚实地标出自己“有多确定”
我在“三重护城河”那篇文章里提过一个 80/20 原则,这里完全适用:
让 AI 做 80% 的整理、编译和交叉引用;
把你自己的品味,投入到最后 20% 的筛选、验证和“只有你看得见的连接”上。
知识层,就是你把这种“品味”编码进去的地方,让那 80% 的自动化工作,随着时间越做越好。
20 分钟搭建指南
这不是概念,而是一套已经开源、可以直接跑的框架。
第 1 步:克隆仓库(约 2 分钟)
git clone https://github.com/shannhk/llm-wikid.git my-wiki
cd my-wiki
然后把这个文件夹作为一个 Obsidian Vault 打开。
第 2 步:启动你的智能体(约 3 分钟)
在这个文件夹里打开 Claude Code(或任何能读 markdown、能跑 bash 的智能体)。
它会先读 CLAUDE.md,这里定义了整个系统的 schema:
# CLAUDE.md (简化版)
## 目录结构
- raw/ → 杂乱收件箱,什么都往这里丢
- wiki/ → 编译好的页面,结构化
- wiki/index.md → 总索引 + TL;DR
## 操作命令
- /wiki-ingest → 把 raw/ 里的内容处理成 wiki 页面
- /wiki-query → 提问,得到带引用的回答
- /wiki-explore → 浏览和验证页面
- /wiki-lint → 查找矛盾、过期内容
智能体读完这个文件后,就知道:
- 目录怎么组织
- 页面长什么样
- 每个命令要做什么
并会自动搭好基础结构。
第 3 步:填充内容(约 10 分钟)
可以从这几件事开始:
- 在 X 设置里申请你的推文归档
- 安装 Obsidian Web Clipper,开始剪藏:
- 值得保留的推文
- 长帖 / 文章
- 工具页面
- 坐下来写 10 分钟,把脑子里当前最重要的东西全部倒出来
- 把浏览器书签导出,筛一遍,凡是相关度 80% 以上的,都丢进 raw/
第 4 步:运行 ingest(约 5 分钟)
> /wiki-ingest
智能体会自动:
- 整理剪藏
- 从 URL 抓取完整内容
- 下载并分析图片
- 按类型分类每个来源
- 生成带交叉引用的 wiki 页面
- 在每页上写反方观点和数据缺口
- 更新总索引
然后你就可以开始 /wiki-query 了。比如:
> /wiki-query what content formats get the most bookmarks?
Reading wiki/index.md... scanning 47 TLDRs
Reading wiki/content-performance.md
Reading wiki/bookmark-analysis-march.md
Reading wiki/thread-vs-single-tweet.md
Answer:
Threads with numbered lists get 3.2x more bookmarks than
single tweets in your data. visual breakdowns (terminal
screenshots, flowcharts) averaged 847 bookmarks vs 312 for
text-only. the top 5 bookmarked posts were all either
step-by-step guides or tool comparisons.
Sources: [[content-performance]], [[bookmark-analysis-march]],
[[thread-vs-single-tweet]]
→ Filed as wiki/bookmark-formats-query.md
每一个回答,都会被存成新页面。
下次再问“内容表现”相关的问题,这一页也会被一起读进去。
第 5 步:打开图谱视图
在 Obsidian 里打开 Graph View:
你关心的概念、关注的人、用的工具、写过的内容,现在都被连成了一张图。
接下来就可以开始用 /wiki-query 探索了。
(此处原文有 Obsidian 图谱截图,略)
初始搭建后,可以试试这些问题
当第一轮 ingest 跑完,你可以先问这几类问题:
“过去一个月,我收藏最多的内容主题是什么?”
→ 看清自己的“信号模式”。
“有哪些反对我主张 X 的论点?”
→ 强迫自己用 wiki 里已有的材料,给自己的观点做压力测试。
“总结一下我目前关于 [竞争对手 / 工具 / 话题] 的所有认知。”
→ 从所有提到它的来源里,综合出一份简报。
“哪些概念在 wiki 里被引用最少?”
→ 找出知识薄弱区,决定下一步该研究什么。
每一个回答,都会被存回 wiki,形成复利。
接下来可以做什么
-
设一个定时任务(Claude Dispatch 或 cron),每天早上自动跑
/wiki-ingest- 白天你只管剪藏
- 晚上自动处理
- 早上醒来,知识库又厚了一层
-
每 1–2 周跑一次
/wiki-lint:- 找出页面之间的矛盾
- 标记过期内容
- 发现没人链接的“孤儿页面”
- 合并重复概念
智能体会自动修正能修的部分,剩下的会标记出来,等你决策。
当页面数量超过 300+ 时,可以装一下 Tobi Lutke 做的 qmd:
- 本地混合检索(BM25 + 向量 + LLM 重排)
- 自带 MCP server,智能体可以把它当原生工具来搜 wiki
然后,把知识层接到更多智能体上:
- 一个写作智能体,专门读它
- 一个研究智能体,专门往里喂东西
- 一个内容策略智能体,专门问它问题
知识层,就是让所有智能体“共享大脑”的那一层。
现在的窗口期
Karpathy 那篇帖子已经 99,000+ 书签。
Graphify 在 48 小时内上线,又拿了 27,000+ 书签。
同一周内,多种实现方案都在疯传,需求已经非常明确。
但大多数人会:
- 把这篇文章也收藏一下
- 心里想一句“挺酷的”
- 然后再也不会打开
而那一小撮愿意现在就花 20 分钟的人:
- 到下个月就会有一套开始复利的知识库
- 任何搜索引擎和通用 AI 提示词都无法复制
- 它会懂你的语气、数据、模式和审美
你每多等一周,都是一周的复利白白流失。
仓库地址:
- GitHub:
github.com/shannhk/llm-wikid
现在就可以克隆、打开、跑第一遍 ingest,让你的所有 AI,从今天开始真正“认识你”。