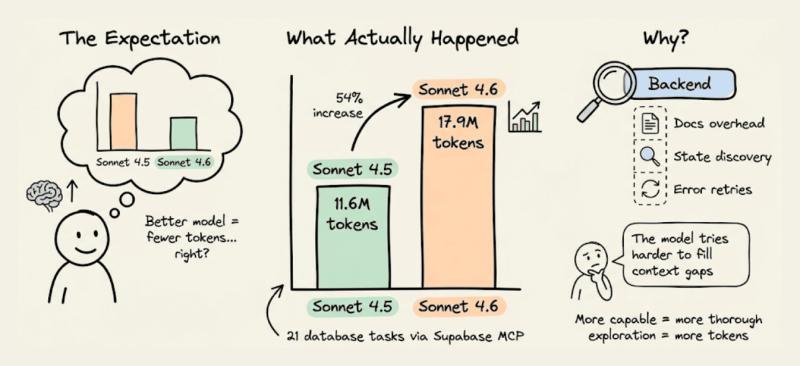
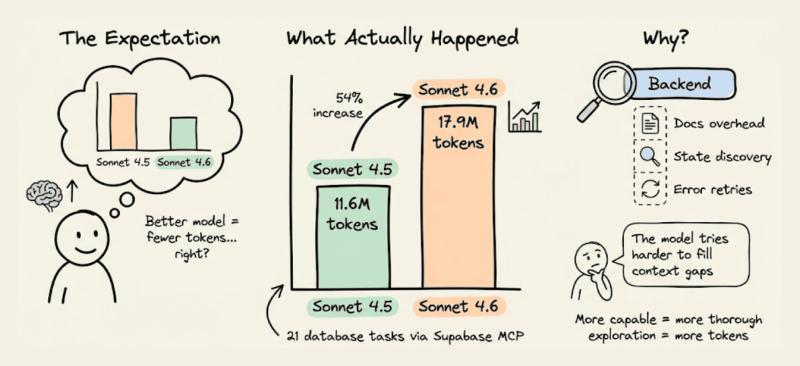
99% 的人以为「换个更聪明的模型」就能省钱提效,结果账单却一路飙升。我们在 MCPMark V2 基准测试里踩了这个坑:Claude 从 Sonnet 4.5 升级到 4.6,后端 Token 用量不降反升,从 21 个数据库任务的 1160 万涨到 1790 万。模型确实更聪明了,但 Supabase MCP 后端成了一个巨大的 Token 黑洞。
更反直觉的是,问题几乎和模型本身无关,而是出在「后端怎么把信息暴露给 Agent」。当上下文不完整时,更强的模型不会「自动脑补」,而是会:多想、多查、多试错,最后把缺失的上下文变成更贵的账单。我自己第一次看日志时也有点不敢相信,只能老老实实把整场会话导出来,一条条对着看。
据我们在 MCPMark V2 的测试数据,Sonnet 4.6 在同一批任务上的后端 Token 消耗比 4.5 高出约 54%,而任务成功率几乎相同。
接下来,我们会拆开看:为什么传统后端对 Agent 来说是 Token 漏斗,一个面向 Agent 的后端架构应该长什么样,以及在真实项目里,这种架构能省下多少钱。
为什么 Supabase MCP 会变成 Token 黑洞
文档检索:一次性把「整本说明书」砸给模型
很多人以为「多给点文档,模型就更聪明」,但在 Supabase MCP 上,这几乎等于在烧钱。Claude Code 需要通过 Supabase 配置 Google OAuth 时,会调用 search_docs 工具。问题在于:Supabase 的实现每次都会返回完整的 GraphQL Schema 元数据,Token 量是 Agent 真正需要内容的 5–10 倍。
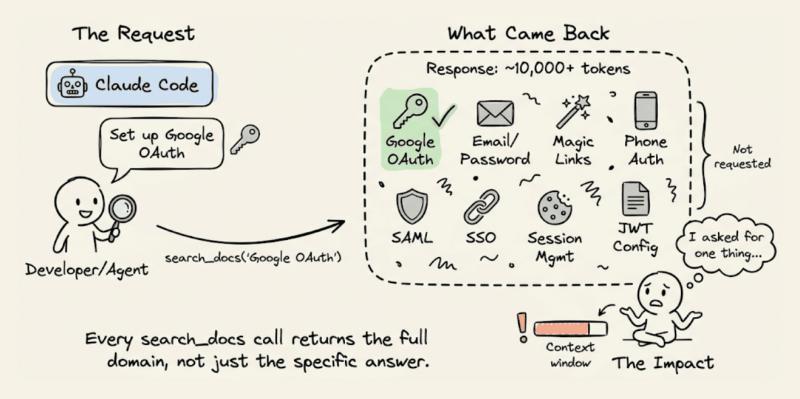
Claude 只想要「如何配置 Google OAuth」,结果被塞了一整套认证文档:邮箱密码、魔法链接、短信登录、SAML、SSO……每一次 search_docs 调用都是这样,查数据库、配存储、发 Edge Function,全都一股脑儿灌进去。一次会话里 Agent 要配置 Auth、数据库、存储、函数,光文档冗余就能浪费掉成千上万 Token。
我自己用 Claude Code 帮忙改 Supabase 项目时就遇到过类似情况:明明只想改一条 RLS 策略,结果上下文里塞满了和当前任务无关的章节,看着都替钱包心疼。
状态不可见:Agent 没有「后台大屏」
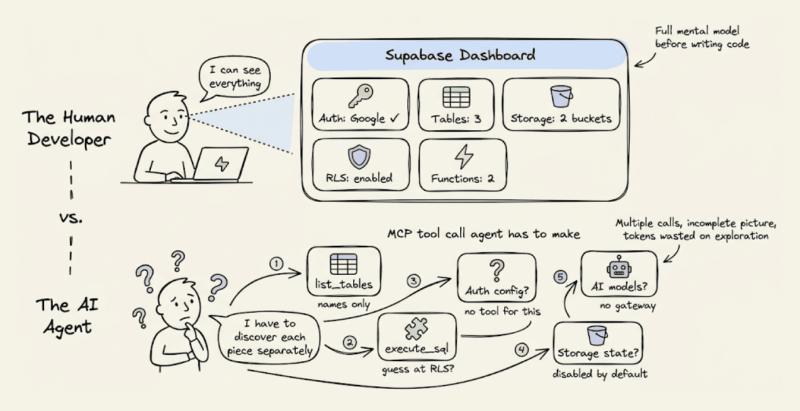
人类开发者用 Supabase,会先打开 Dashboard:有哪些表、哪些 RLS 策略、哪些 Auth Provider 已开、存储桶怎么配、Edge Functions 部署情况,一眼就能扫一遍。Agent 做不到这一点,它看不到任何 UI。
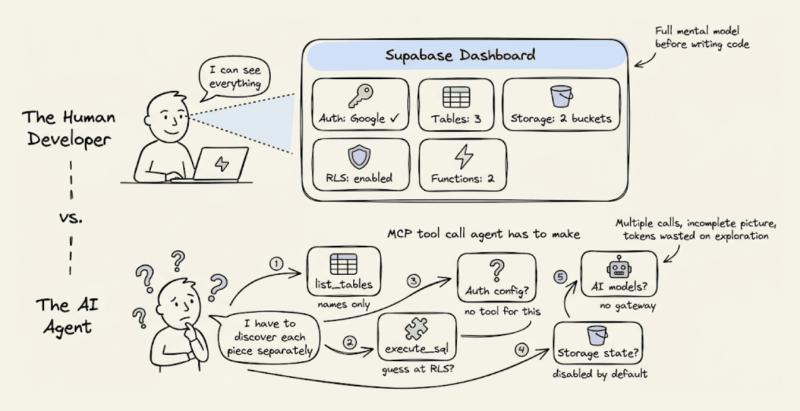
Supabase MCP 虽然提供了 list_tables、execute_sql 之类的工具,但没有一个「给我整个后端当前拓扑」的一次性结构化响应。Agent 只能靠多次调用把碎片拼起来,而且有些关键状态(比如已配置的 Auth Provider)根本拿不到。
结果就是:
- 多轮探测调用堆叠,Token 一直涨;
- 返回格式不统一,Claude 还要额外推理、再发起新查询;
- 有用户反馈,在复杂项目里,光「摸清现状」就能占掉会话 Token 的 30% 以上。
错误上下文缺失:每一次 401 都可能触发一轮「盲修」
说实话,后端报错本来就够让人头大,对 Agent 来说更是灾难。Supabase 出错时,多半只给你一个原始错误:RLS 拒绝的 403、Edge Function 的 500、JWT 校验失败的 401……人类开发者会:看 Dashboard、翻日志、对照文档,最后定位到「到底是平台层还是代码层」的问题。
Agent 没这条路。它只看到一行错误信息,然后开始猜:
- 可能是 Header 少了?
- 可能是 CORS?
- 可能是 Token 过期?
每猜一次,就:多想一大段、改一堆代码、重新部署、再试一遍。每次重试都会把整段对话历史重新带进上下文,Token 成倍叠加。有一次我们在 Supabase 上调试 Edge Function,Claude 连续 8 轮「修代码 → 部署 → 失败 → 看日志」,最后发现根因是平台层的 verify_jwt 拦截,函数代码根本没跑起来。
这类「平台层错误被当成代码错误」的情况,在我们导出的会话日志里出现了不止一次,几乎每次都会触发 3–8 轮无效重试。
更强的模型(比如 Sonnet 4.6)在这种场景下只会更「执着」:推理更细、尝试更多方案、写更长的解释——也就更贵。这也是为什么从 4.5 升到 4.6 后,Token 差距被进一步放大。
后端上下文工程:不是换个模型,而是换种暴露方式
「上下文工程」不只是在改 Prompt
很多人提到 Karpathy 的那句「Context engineering is the delicate art and science of filling the context window with just the right information for the next step」,想到的都是 Prompt 和 RAG。其实他明确把「工具和状态」也算进上下文,只是大多数团队只优化了前半截,后端这块几乎没人动。
我们在做 Claude Code 基准测试时,逐渐形成了一个新视角:
模型的「聪明程度」是给定的,真正能拉开成本差距的,是你给它什么样的后端上下文。
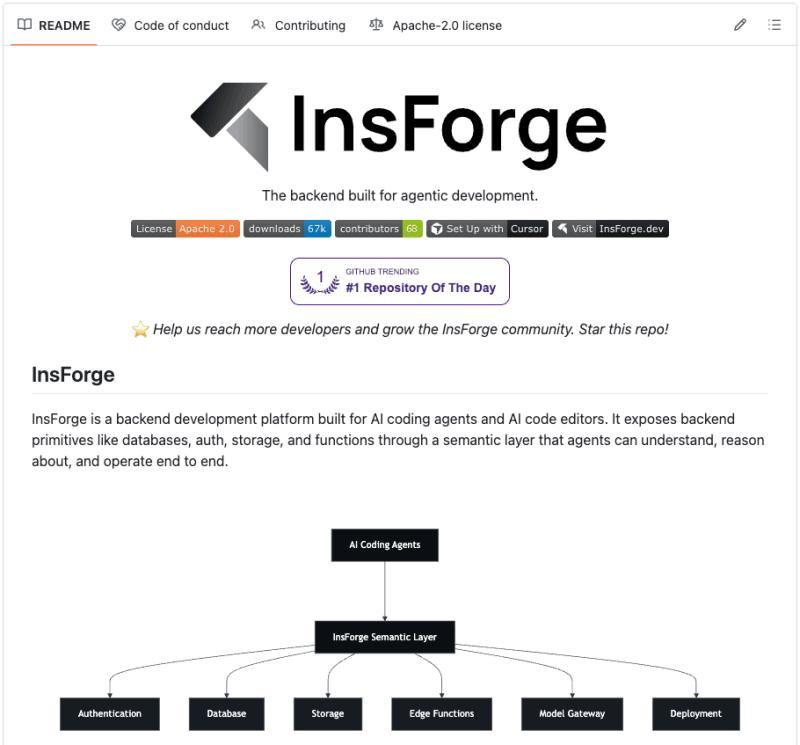
为了验证这个想法,我们做了一个对照实验:用 Claude Code 分别在 Supabase 和 InsForge 上构建同一个 DocuRAG 应用,然后把完整会话导出成 JSONL,交给另一实例 Claude 做统计分析。结果非常扎眼:InsForge 这边的后端 Token 消耗只有 Supabase 的 2.8 分之一。
InsForge 的三层设计:把「知识」「执行」「状态」拆开
InsForge(开源,Apache 2.0)在架构上做了一件看似简单、但非常关键的事:把后端相关的信息分成三层,用不同的方式喂给 Claude Code:
- Skills:静态知识,零往返调用
- CLI:直接操作后端,结构化输出
- MCP:只用于实时状态检查
每一层解决的是不同的问题,也各自对应一块 Token 节省空间:
- Skills 避免了「为查文档而发起的工具调用」;
- CLI 避免了「多轮 MCP 调用 + 文本解析」;
- MCP 只在必要时出场,且一次性返回完整拓扑。
Skills:按需展开的「后端小抄」
InsForge 的知识层完全靠 Skills 承载。它们在会话开始时就加载进 Agent 的上下文,但采用「渐进披露」:
- 初始只加载元信息:名称、描述,每个 Skill 大约 70–150 Token;
- 只有当 Claude 判断「当前任务需要」时,才展开完整内容(代码示例、边界情况、最佳实践)。
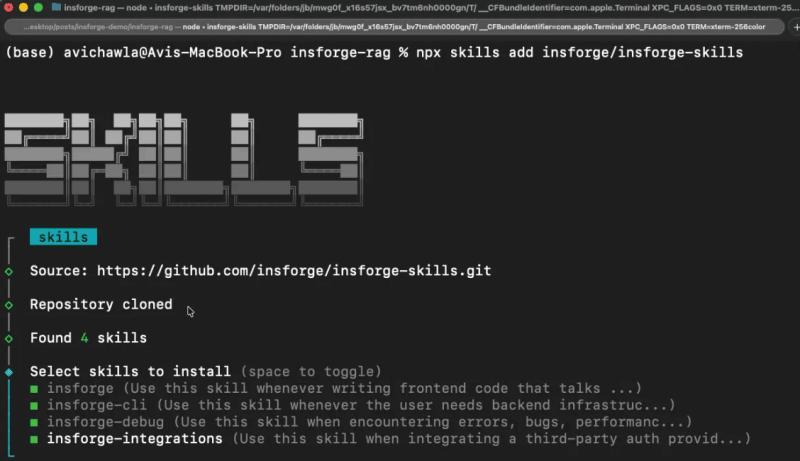
四个 Skill 覆盖了完整后端面:
insforge:前端如何调用后端 SDK 的模式和示例;insforge-cli:后端基础设施管理(建表、迁移、函数部署等);insforge-debug:常见错误的结构化诊断(Auth、慢查询、RLS、函数失败等);insforge-integrations:第三方 Auth(Clerk、Auth0、WorkOS、Kinde、Stytch)。
安装也很简单,一条命令搞定四个 Skill:
CLI:一次命令,结构化结果 + 语义退出码
执行层完全交给 CLI:建表、跑 SQL、部署函数、管理密钥,全都通过 npx @insforge/cli 完成。每条命令都支持:
--json:结构化输出,方便 Claude 用jq、grep、awk二次处理;-y:跳过交互确认,适合自动化;- 语义化退出码:区分 Auth 失败、项目不存在、权限不足等。
在 Supabase MCP 里,很多类似操作需要多次工具调用 + 文本解析才能完成;在 CLI 模式下,一条命令 + 一次 JSON 解析就够了。我们在日志里看到,InsForge 会话里 77 次工具调用全部是 CLI,没有一次 MCP 调用。
MCP:只做一件事——给 Agent 一张「后端全景图」
MCP 在 InsForge 里仍然存在,但用途被极度收窄:只负责「实时状态检查」。核心工具是一个轻量的 get_backend_metadata:
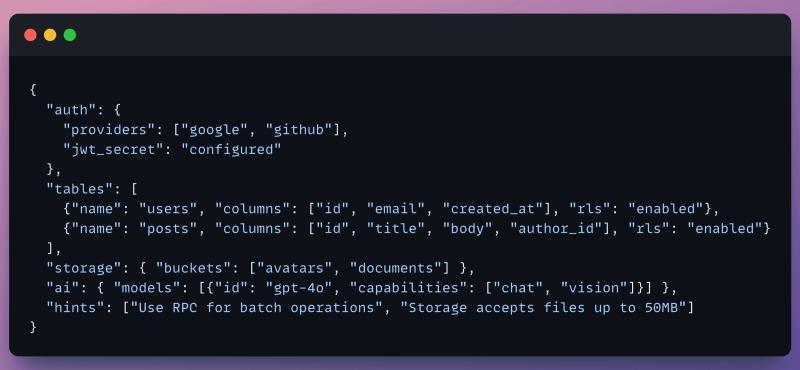
一条调用、约 500 Token,Claude 就能拿到完整拓扑:
- 所有表、索引、扩展;
- 已启用的 Auth Provider;
- 存储桶、实时通道、可用模型;
- 以及专门给 Agent 的
hints字段,告诉它「这里有哪些坑别踩」。
关键的设计反转在于:
- 文档(静态)→ 用 Skills 承载,不走 MCP;
- 状态(动态)→ 用 MCP 一次性返回,而不是碎片化探测。
这也是为什么在同样的 DocuRAG 项目上,InsForge 的 Token 消耗远低于 Supabase。
实战对比:用 Claude Code 各搭一套 DocuRAG
同一个应用,两套后端
我们让 Claude Code 分别在 Supabase 和 InsForge 上搭建同一个 DocuRAG 应用:
- 用户用 Google OAuth 登录;
- 上传 PDF;
- 系统切分 + 嵌入(
text-embedding-3-small,1536 维); - 向量存 pgvector;
- 用户用自然语言提问,由 GPT-4o 回答。
这个应用几乎踩遍所有后端原语:Auth、存储、文档表、向量表、嵌入生成、Chat Completion、检索函数、RLS 隔离。对 Claude 来说,是一场完整的「后端综合考试」。
我们把两场会话的 Prompt 设计成几乎一致,唯一的区别是:
- Supabase 版本里写的是「通过 OpenAI API 调用 LLM/Embedding」;
- InsForge 版本里写的是「通过同一个后端的 Model Gateway 调用模型」。
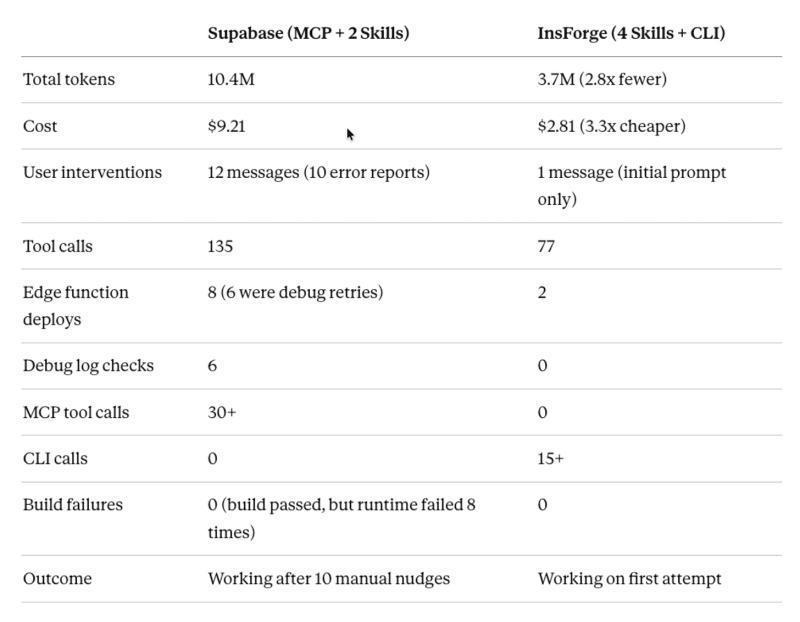
结果先看:10.4M vs 3.7M Token
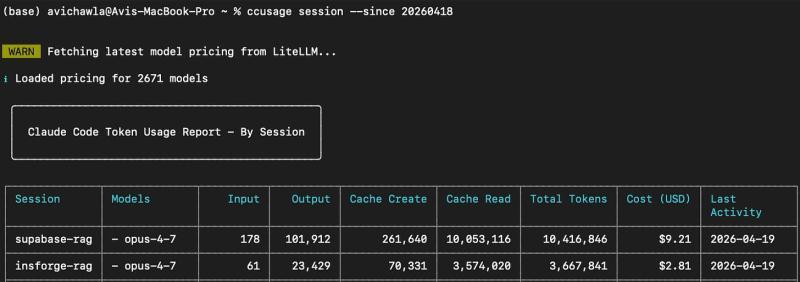
- Supabase:
- 10.4M Token
- 约 9.21 美元
- 12 条用户消息,其中 10 条是「报错 + 求修复」
- InsForge:
- 3.7M Token
- 约 2.81 美元
- 1 条用户消息,全程零报错
我们把两场会话导出成 JSONL,再喂给 Claude 做自动分析,下面是拆解过程。
Supabase:10.4M Token 是怎么烧掉的
初次构建:一切看起来都很顺利
一开始 Claude 的表现非常好:
- 加载
supabaseSkill; - 用 MCP 工具
list_tables、list_extensions、execute_sql探测现状; - 脚手架出 Next.js 项目;
- 创建数据库 Schema;
- 写好
ingest-document和query-document两个 Edge Function; - 完成部署,应用能跑起来。
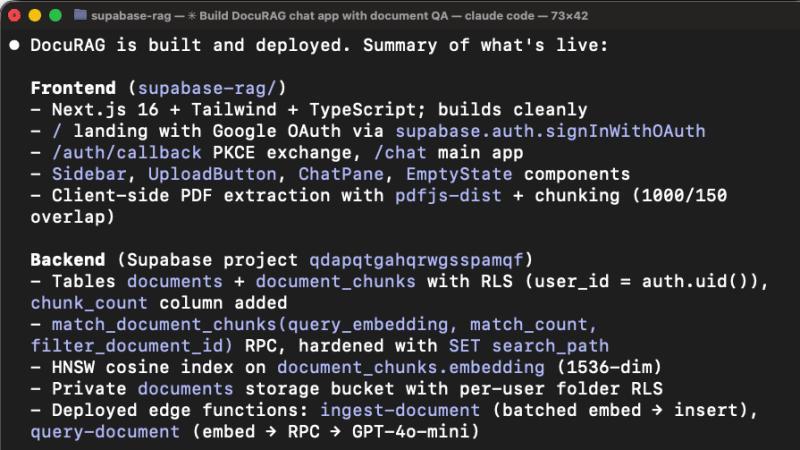
如果只看这一步,你会觉得「Supabase + MCP 完全没问题啊」。真正的 Token 灾难,从我们第一次点击「用 Google 登录」开始。
问题一:登录失败,原因是选错了客户端库
我们尝试用 Google OAuth 登录,前端直接报错。Claude 之前选用了错误的 Supabase 客户端库:
- Next.js 的 OAuth 回调逻辑跑在服务端;
- 它却用了一个把登录状态存在浏览器的客户端库;
- 结果服务端拿不到浏览器里的状态,整条链路断掉。
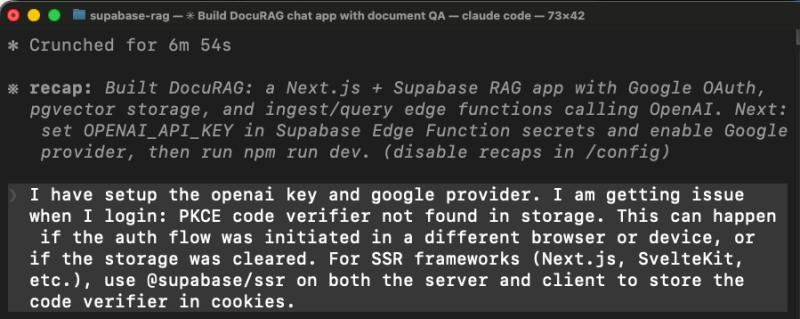
Claude 的修复方式也没毛病:
- 换成
@supabase/ssr; - 重写登录态管理逻辑;
- 重新部署应用。
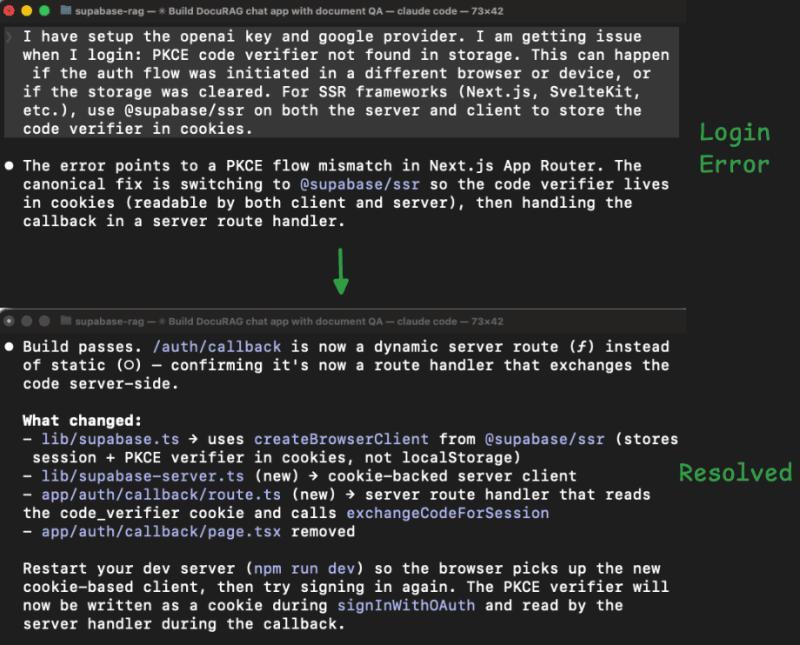
登录问题到这里算是解决了,但也埋下了后面大坑的种子:新的 Auth 库发出的 Token 格式,和 Supabase 平台层的 verify_jwt 行为产生了冲突。
问题二:文档上传失败,8 轮「盲修」才找到根因
登录 OK 之后,我们上传了一份 PDF,Edge Function 直接报错。我们把错误贴给 Claude,它尝试修复,失败;我们再试,还是同样的错误。这个循环一共发生了 8 次:
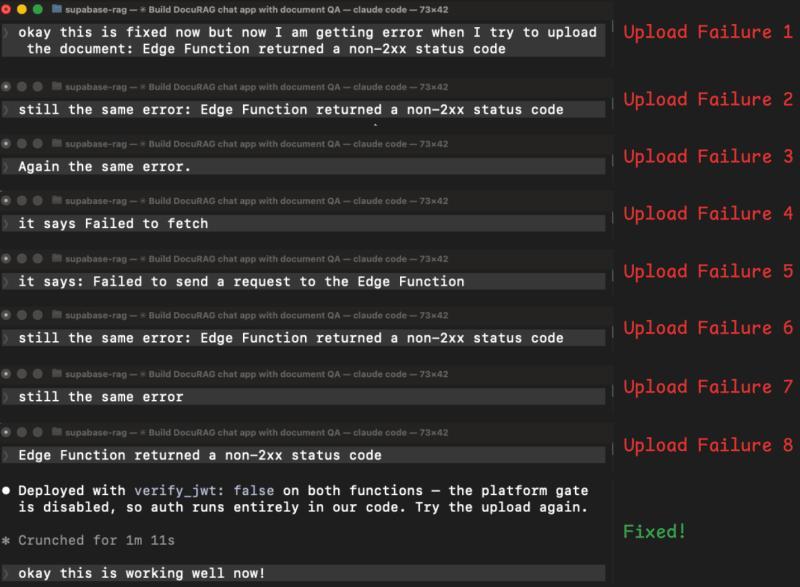
中间它做过这些尝试:
- 手动加 Auth Header → 还是同样错误;
- 加强日志输出,重新部署 → 还是同样错误;
- 把通用错误改成直接返回真实错误 → 变成 CORS/网络问题;
- 修 CORS → 又回到原来的 401;
- 换另一种方式读取用户 Token → 依旧 401;
- 再换一种 Auth 方案 → 还是 401。
真实情况其实很简单:
- Supabase 在 Edge Function 前面有一层安全网关;
- 新 Auth 库发出的 Token 格式,这个网关不认;
- 所有请求在函数代码执行前就被 401 拦截了。
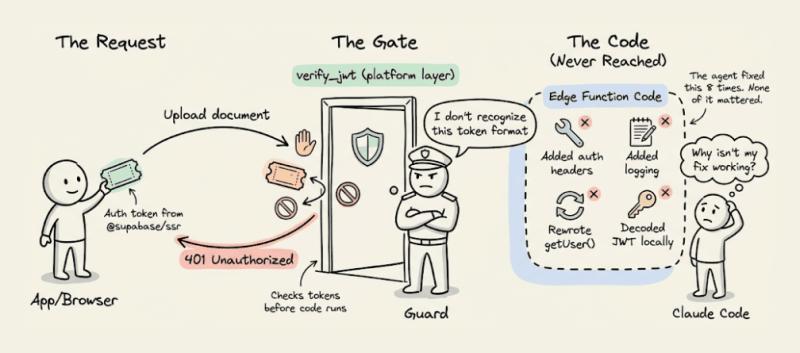
Claude 没有任何信号能区分「平台层 401」和「代码层 401」,只能一遍遍改函数代码。真正的解决方案其实很朴素:关掉平台层自动 Token 校验,在函数内部自己做 Auth。
但在找到这个方案之前,它已经:
- 查日志 6 次;
- 重新部署 Edge Function 8 次;
- 尝试 6 种不同的 Auth 策略;
- 每一次都把不断膨胀的对话历史重新带进上下文。
最终这场会话的统计是:
- 12 条用户消息(10 条是报错);
- 135 次工具调用;
- 30+ 次 MCP 调用;
- 10.4M Token;
- 约 9.21 美元成本。
InsForge:3.7M Token 的构建体验
一上来就先「摸清家底」
在 InsForge 会话里,Claude 的第一步是:
npx @insforge/cli metadata --json
这条命令返回了一个完整的项目概览:
- 已配置的 Auth Provider;
- 现有表、扩展、存储桶;
- 可用的 AI 模型(包括
text-embedding-3-small和gpt-4o); - 实时通道、函数入口等。
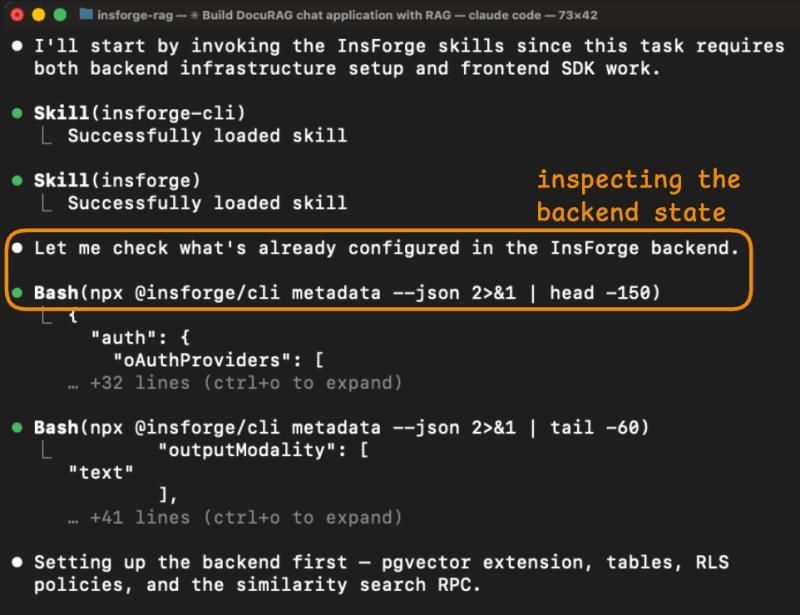
对比 Supabase 那边需要多次 MCP 调用才能勉强拼出类似视图,而且还拿不到 verify_jwt 这类平台行为,InsForge 这一步几乎把后面所有「摸索式调用」都省掉了。
Schema & RLS:6 条命令全部一次成功
接下来是数据库部分,Claude 通过 6 条 CLI 命令完成:
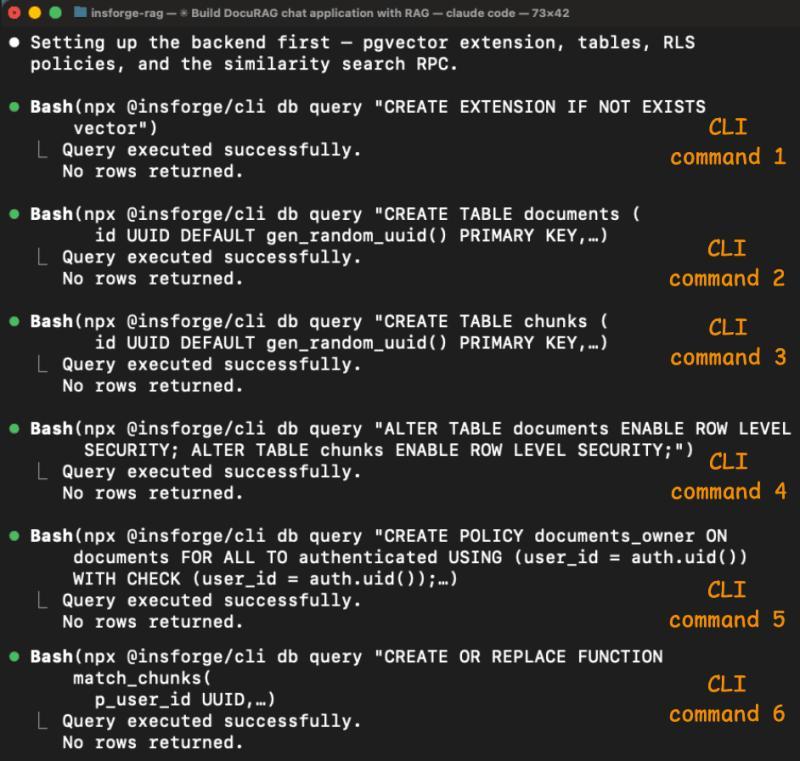
- 启用 pgvector;
- 创建
documents和chunks表(vector(1536)列); - 打开 RLS;
- 配好访问策略;
- 创建
match_chunks相似度查询函数。
每条命令都返回 JSON,Claude 能明确知道「这一步到底成功了没有」,而不是靠猜。
Auth & 函数:一次接好,零报错
Supabase 会话里最折腾的两块——Auth 和 Edge Function——在 InsForge 这边都一次通过:
insforgeSkill 里已经内置了 Next.js 的正确客户端模式;- Model Gateway 和数据库在同一个后端,不需要单独集成 OpenAI;
embed-chunks和query-rag两个函数部署后,第一次调用就成功。
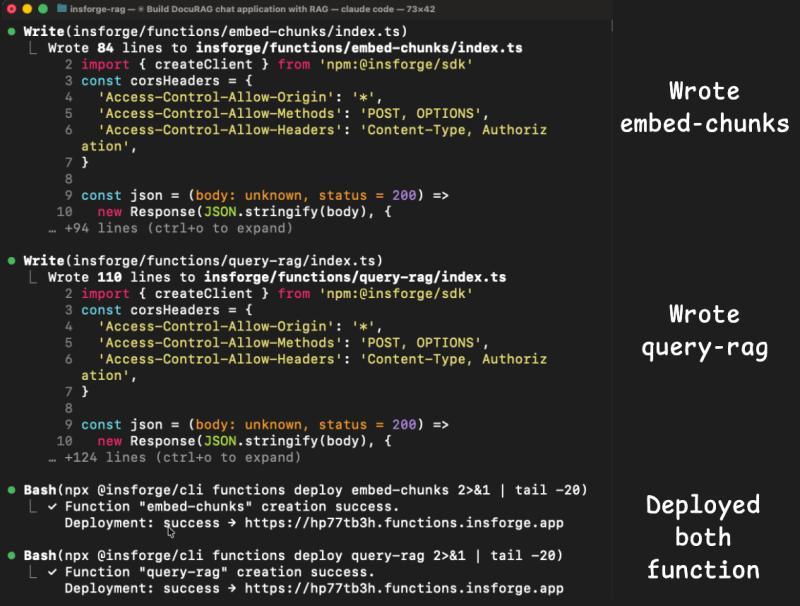
从用户视角看,这一场会话几乎是「一条 Prompt,等着看成品」。从日志统计看:
- 1 条用户消息;
- 77 次工具调用(全是 CLI);
- 0 次 MCP 调用;
- 3.7M Token;
- 约 2.81 美元成本。
我们让 Claude 做了一个并排总结:
可以看出,Supabase 那边的 Token 高消耗,几乎全部来自「错误重试环」:
- 8 次函数重部署,每次都带着更长的对话历史;
- 6 次日志检查;
- 6 套不同的 Auth 尝试;
- 平台层和代码层错误没有被区分,Agent 只能盲修。
而 InsForge 通过:
- 预先暴露完整元数据;
- 用 Skill 固化正确模式;
- 用 CLI 提供结构化反馈;
把这些「盲修」几乎全部消掉。
这不只是 Supabase 的问题,而是大多数后端的通病
从更大的视角看,这次对比暴露的是一个行业级的错位:
- 现有后端是为「人类开发者」设计的:
- 默认你会看 Dashboard;
- 默认你能从模糊错误里猜出上下文;
- 默认你能在脑子里串起多个服务的状态。
- 当这些假设换成「Agent」时,全部失效:
- 它看不到 UI;
- 它不知道错误来自哪一层;
- 它每次猜错,都会付出 Token 成本。
InsForge 选择从一开始就假设「主要操作者是 Agent」:
- 后端状态通过结构化元数据暴露;
- CLI 提供可编程的成功/失败信号;
- Skills 把正确模式编码进去,尽量减少「靠摸索」;
- 模型网关把 LLM 调用收拢到同一个后端,避免跨服务集成坑。
我也不太确定这种设计是不是未来所有后端的标准答案,但至少在我们这次 DocuRAG 对比里,它把 Claude Code 的后端 Token 花费砍掉了 2.8 倍,而且开发体验肉眼可见地顺滑。
如果你正在给团队搭 AI 开发环境,这套「后端上下文工程」的思路非常值得收藏备用。等到下次账单突然暴涨,你会庆幸自己提前做了这层优化。
常见问题
Q:我现在已经在用 Supabase + Claude Code,有必要为了省 Token 直接换成 InsForge 吗?
A:不一定要立刻整体迁移,更现实的做法是先把「上下文工程」的思路用在现有栈上。比如:自己写一层轻量 CLI,把常用操作封装成结构化输出;给 Claude 提供一份「项目元数据 JSON」,而不是让它靠 MCP 慢慢探测;在日志里区分平台层错误和代码层错误。等你验证这些改造能稳定省下 30% 以上 Token,再评估是否迁移到更适合 Agent 的后端,比如 InsForge。迁移本身也有成本,建议先用一个新项目做试点。
Q:怎么判断一个后端对 AI Agent 友不友好?有没有一套快速检查标准?
A:可以用三个问题做体检:1)能否一条命令/一次调用拿到「完整后端拓扑」的结构化数据?2)错误信息是否区分平台层和业务层,并且有机器可读的错误码?3)是否有稳定的 CLI 或 API,可以在无 UI 的环境下完成全部运维操作?如果这三条都做不到,Agent 就只能靠「多轮试错」来摸索,Token 消耗一定高。建议优先补齐 CLI 和元数据导出,其次再考虑 MCP 或 Skill 之类的高级集成。
Q:在实际项目里,后端 Token 成本大概会占到多少比例?值得专门优化吗?
A:据我们和几家团队的对话,在典型的「AI 助手 + 工具调用」场景里,后端相关 Token(包括文档检索、状态探测、错误重试)往往能占到总消耗的 20%–40%。一旦引入复杂后端(多服务、多环境),这个比例还会继续上升。考虑到模型本身的单价已经在被大厂卷到很低,后端 Token 反而成了更容易优化的部分。建议至少做一次完整会话的日志分析,算清楚「有多少 Token 花在了摸索和重试上」,再决定投入多少精力。
Q:如果我自己写后端,要怎么设计才能天然适配 Agent?
A:可以从三点入手:1)所有关键操作都提供 CLI/HTTP 接口,并支持 --json 或等价的结构化输出;2)设计一份统一的 get_metadata 接口,返回当前项目的完整拓扑和关键配置;3)错误体系要有清晰的错误码和分层信息(比如 AUTH_PLATFORM_401 vs BUSINESS_RULE_401)。在文档层面,可以把常用模式整理成「Skill 风格」的小块,而不是一整本手册。这样一来,无论你用的是 Claude、GPT 还是其他模型,Agent 都能在最少的调用下搞清楚「我在哪、我能做什么、哪里出错了」。
Q:InsForge 开源版和自建有什么坑吗?适合在生产环境用吗?
A:InsForge 是 Apache 2.0 开源协议,可以用 Docker Compose 自建,这一点对很多对数据合规敏感的团队很友好。风险主要在两块:一是你需要自己维护基础设施(升级、监控、备份),二是要评估社区活跃度和问题响应速度。建议的做法是:先在内部工具或非核心业务上试跑一段时间,观察稳定性和运维成本;同时保留现有后端作为兜底。等你对它的 CLI、Skill、MCP 这套组合足够熟悉,再逐步把更关键的工作负载迁过去,会更稳当一些。
如果你正打算让 Agent 真正「接管后端」,这套对比和方法论,可能比问身边任何一个人都更有参考价值。


