当前关于“循环”的讨论热度不断升温:
- Steipete提醒大家:“别再直接提示编码代理了,应该设计循环来提示你的代理。”
- Boris表示:“我不再直接提示Claude了,我写循环,让循环完成工作。”
- Andrej Karpathy在Autoresearch中强调,要最大化令牌吞吐量,必须将自己从循环中移除,实现完全自主的系统。他提出:“关键是如何重构所有抽象,一次安排好后就能自动运行。”
我们已经身处许多循环之中:
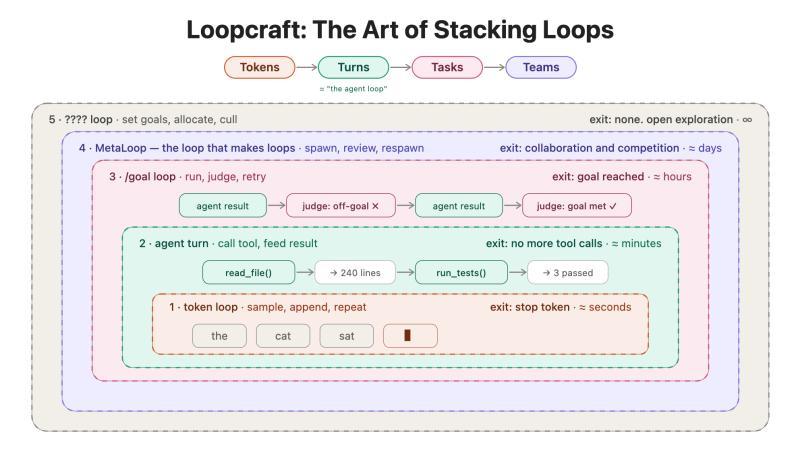
更简化的循环示意:

未来的关键游戏规则或许是如何高效堆叠循环。初期阶段,向下钻取循环以保证可靠性很重要;随着模型能力提升,向上提升循环以增强杠杆效应将更具价值。
如果你没掌握这门艺术,输给掌握它的人时别抱怨。
Rich Sutton的“苦涩教训”针对模型,而我们现在有了“咸涩教训”针对代理:
不要再像过去那样亲自修复问题, 而应专注于可扩展的系统,如目标设定和协调。
AI Twitter热点回顾
Anthropic的Fable 5发布及其引发的争议
- Anthropic秘密降低了Claude Fable 5在部分AI研究场景的能力,遭遇公众强烈反弹后迅速撤回。技术批评主要集中在模型层的不透明行为,认为这破坏了用户与提供者之间的信任。
- 研究者们区分了合理的限制与隐蔽的破坏行为,呼吁通过实名验证和监控的访问计划保障安全研究。
- Fable 5在多个基准测试中表现强劲,但产品表现仍存在成本高、拒绝响应和奇怪措辞等问题。
自动化AI研究与代理优化系统
- Recursive SI发布了一个自动化开放式发现系统,在多个公开优化任务中达到最新水平,并开源了成果。
- 微软的Arbor系统通过持续的假设树优化,在多项研究任务中超越Codex和Claude Code,展示了长远假设管理的潜力。
- 新基准测试开始衡量AI自我改进和实际劳动任务的完成情况,显示代理在有限循环中表现良好,但在专家级综合和长期任务上仍显脆弱。
数据基础设施成为瓶颈
- Macrodata Labs推出了面向机器人领域的多模态数据流水线管理工具Refiner,支持数据分片、检查点和血缘追踪。
- Goodfire提出预测性数据调试,AllenAI发布ModSleuth追踪模型依赖图,揭示现代大模型构建的复杂合成性。
- Weaviate和Qdrant等公司强调主动内存管理和检索效率,反对简单依赖更大上下文窗口。
推理速度与系统优化
- DiffusionGemma实现了4倍加速,Unsloth发布的Gemma 4 MTP GGUFs本地推理速度提升1.4至2.2倍。
- MiniMax和Together开源了高性能多头自注意力内核库,优化了长上下文的推理效率。
代理与开发者工具
- ClaudeDevs支持定时部署和环境变量管理,使代理可调度且安全管理凭证。
- 多家公司推动操作工具发展,如Hermes Agent统一配置管理,Cursor默认启用自动代码审查,LangChain发布带有审计日志的LLM网关。
AI Reddit热点回顾
- /r/LocalLlama和/r/localLLM社区持续讨论本地大语言模型的最新进展和应用。
本文展示了AI领域围绕循环设计、自动化研究、数据基础设施和系统优化的最新动态,强调了堆叠循环和提升系统自主性的核心价值。