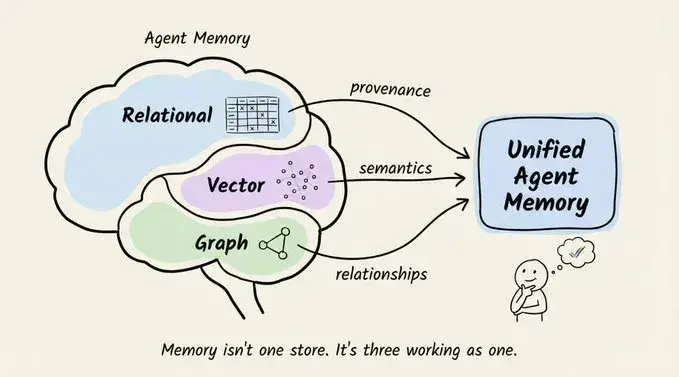
你以为 ChatGPT “记得你说过的话”,其实它每次都在失忆。LLM 本质是无状态函数,每一轮调用都像刚认识你一样,只是我们不断把历史对话重新塞给它,才营造出“记忆”的错觉。轻量聊天还能凑合,一旦要做真正的智能体——长期陪伴、复杂任务、多用户场景——这种伪记忆立刻露馅。
为什么单靠上下文窗口撑不起记忆
聊天没问题,一做成智能体就崩
LLM(大型语言模型)从设计上就是无状态的,每次 API 调用都不记得上一次发生了什么。你在 ChatGPT 里感受到的“连续对话”,只是客户端把整段对话历史一股脑重新发给模型。
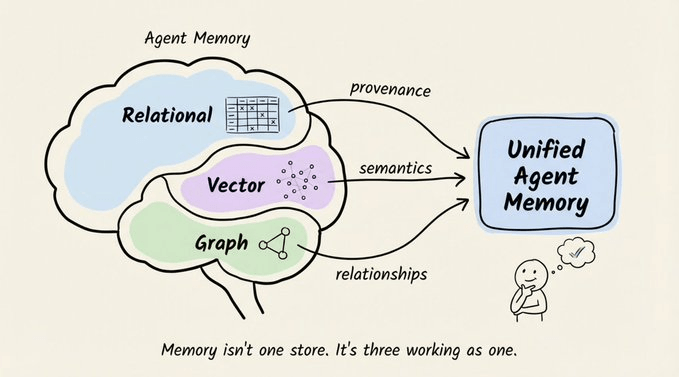
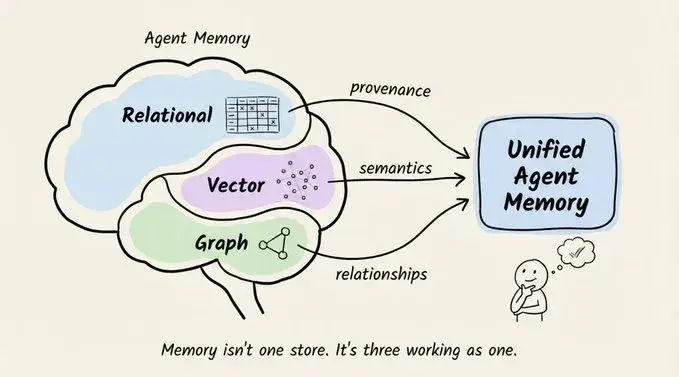
这种做法对闲聊还算够用,但一旦你尝试做“有记忆的智能体”,问题马上浮现:它会反复问你名字、忘记上一步操作、对长期偏好一无所知。很多团队一开始都忽略了记忆层,结果在真实用户面前翻车。
据一些开发者反馈,内部测试时觉得智能体“还行”,一上线到真实业务场景,用户立刻吐槽:怎么每次都要重新自我介绍?
不加记忆的七种典型翻车方式
当你完全跳过记忆设计,智能体会立刻暴露出七种常见失败模式:
- 上下文遗忘:已经说过的信息被反复询问。
- 零个性化:每次交互都像第一次见面,毫无连续感。
- 多步骤任务中途掉线:中间状态丢失,流程断裂。
- 重复犯错:没有情节记忆,之前踩过的坑还会再踩。
- 无知识积累:每次会话都从“白纸”开始。
- 上下文缺口导致幻觉:窗口溢出时,模型开始瞎编。
- 身份崩溃:无法维持稳定人格,用户难以建立信任。
有用户吐槽过一个客服智能体:“聊了三天,感觉每天都在和不同的人说话,它完全不记得我昨天刚解决过什么问题。”
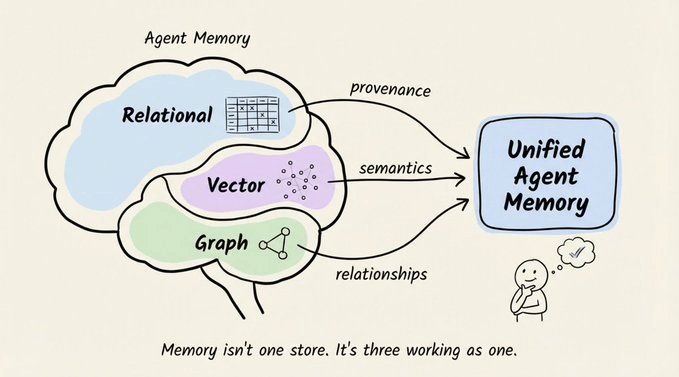
这些问题并不是“调调提示词”就能解决的,而是记忆结构本身缺位。
上下文再大,也不是记忆
很多人第一反应是:那就给模型更多上下文,128K、200K 令牌窗口听起来像是万能药。但现实有点扎心。
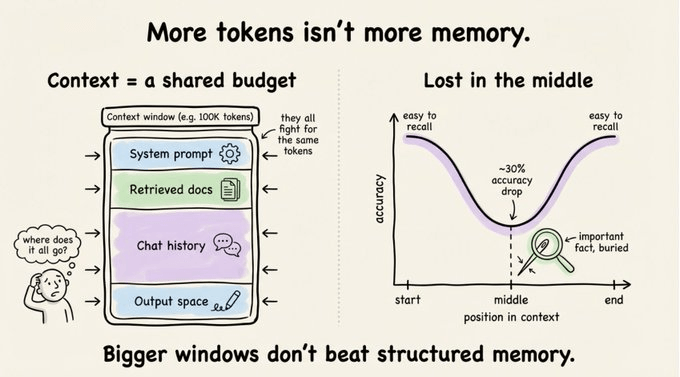
数据显示,当关键信息被埋在长上下文中间时,模型检索正确信息的准确率会下降 30% 以上。原因很简单:
- 上下文窗口是共享预算:系统提示、检索文档、对话历史、工具调用结果都在抢同一批令牌。
- 令牌再多也没有“优先级”:重要事实和无关闲聊被一视同仁地塞进去。
- 没有持久性:窗口之外的内容就像从未存在过。
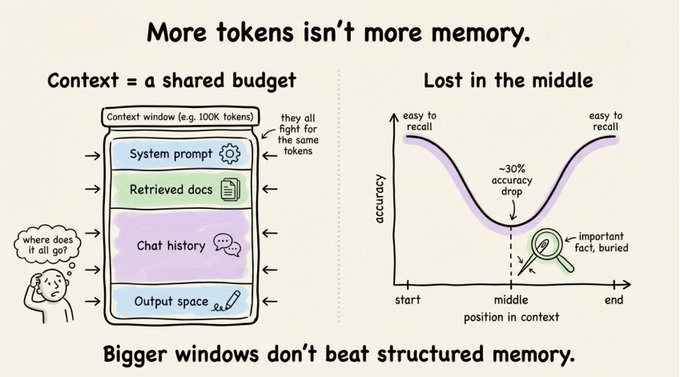
所以,记忆不是“把更多文本塞进提示”,而是要决定:什么该被长期保存、如何被结构化、在需要时怎么被精准找回。这才是记忆层真正要解决的问题。
用认知科学重构智能体记忆
人类大脑的三层记忆,刚好对应智能体架构
Lilian Weng 在 2023 年提出的智能体框架,已经成了很多人默认的参考:
智能体 = LLM + 记忆 + 规划 + 工具使用
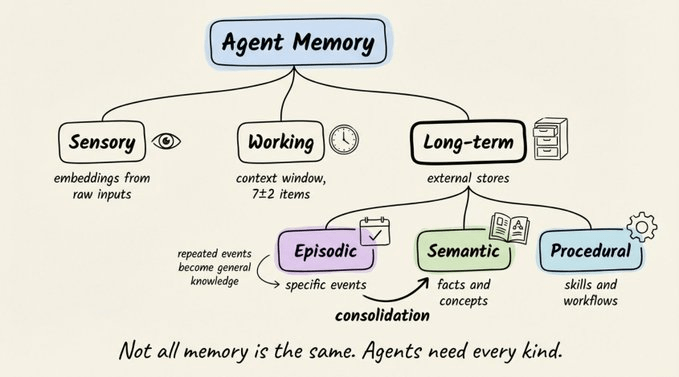
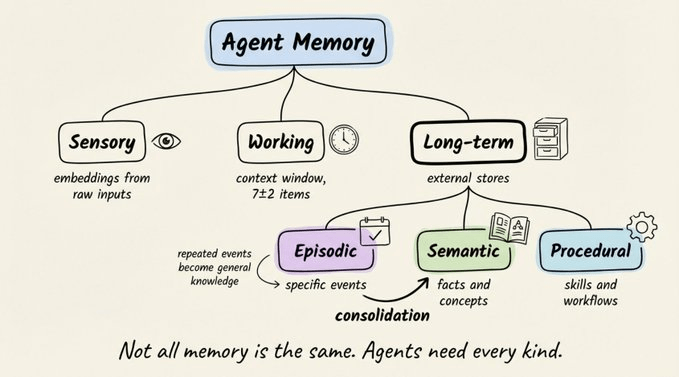
这四个部分缺一不可,而“记忆”这一块,直接借鉴了认知科学里人类记忆的三大系统:
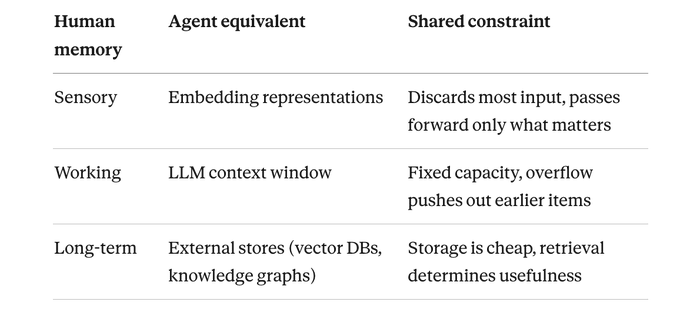
- 感官记忆:捕捉原始感知输入,只保留极短时间,只有被注意到的部分才会被传下去。
- 工作记忆:用来“正在想的事”,容量大约是 7±2 个项目(Miller 1956 年的经典结论)。注意力一散,内容就消失。
- 长期记忆:几乎无限容量的持久存储,真正的瓶颈在于检索——你可以记住成千上万件事,却在关键时刻想不起来。
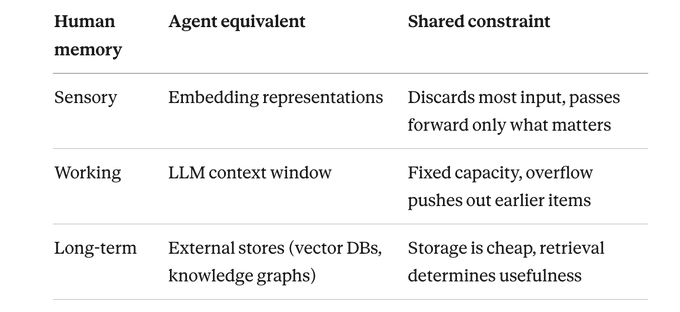
在现代智能体里,这三层可以粗略对应为:
- 感官记忆 → 输入缓冲、日志流、事件流
- 工作记忆 → 当前对话上下文、短期任务状态
- 长期记忆 → 外部知识库、用户画像、历史任务记录
长期记忆:情节、语义和程序
长期记忆内部,其实还可以拆成三种不同的“记住方式”:
- 情节记忆:具体事件,比如“周二 PostgreSQL 集群宕机”。
- 语义记忆:抽象事实和概念,比如“PostgreSQL 是关系型数据库”。
- 程序记忆:技能和流程,比如“处理退款时,先检查购买日期”。
情节记忆和语义记忆之间有个关键桥梁:记忆巩固。重复发生的具体事件,会被提炼成通用规则。
一个真正“会学”的智能体,不是只记得“某天某个用户说喜欢执行摘要”,而是能从多次类似对话中总结出规则:“这个用户普遍偏好先看执行摘要”。
我自己在做内部助手时就踩过坑:一开始只存聊天记录,结果模型每次都要我重复“先给我 TL;DR 再展开”。后来加了一层“偏好规则”抽取,体验才明显变好。
从 Python 列表到向量搜索:记忆演进的三层
最简循环:感知–思考–行动
把各种框架都剥掉,智能体的核心其实就是一个循环:感知(接收输入)、思考(调用 LLM 推理)、行动(执行工具或回复)。
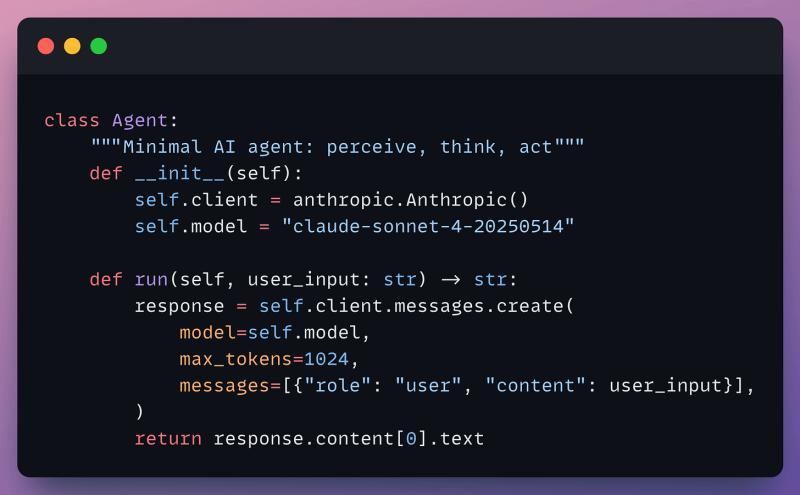
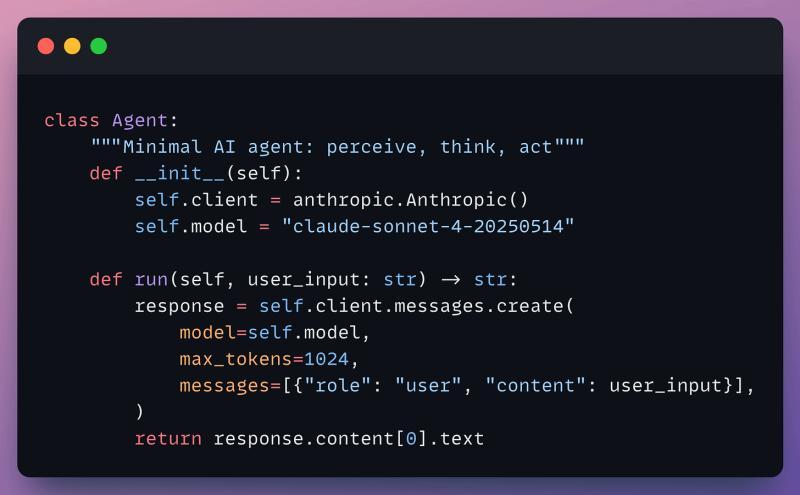
如果你对它说“我有 4 个苹果”,下一轮问“我吃了一个,还剩多少?”,在没有记忆的情况下,它甚至不知道你说的是哪 4 个苹果。每次调用都是孤立事件。
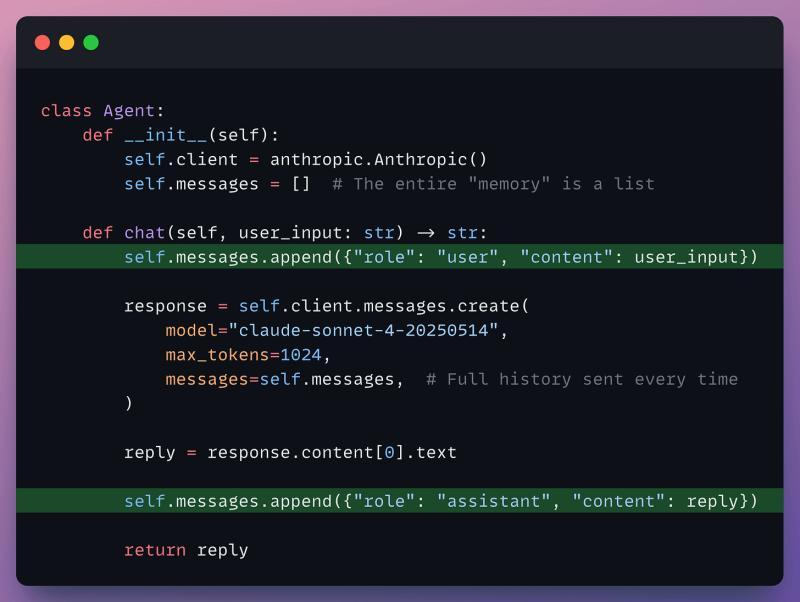
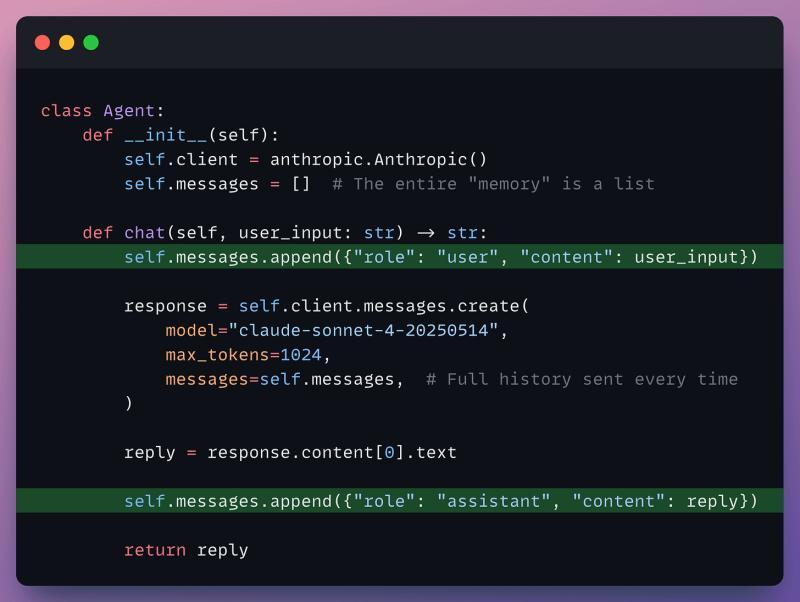
第一层:Python 列表,聊几轮没问题
最直接的补救办法,就是在代码里维护一个 messages 列表,把所有对话轮次都塞进去:
这样多轮对话就能正常运转,因为每次调用都会带上完整历史。问题是:
- 列表会无限增长,到第 200 轮左右就撞上上下文上限,最早的消息被静悄悄丢弃。
- 丢弃是按时间顺序来的,没有优先级:第一轮的用户名,可能比昨天的冷笑话更早消失。
- 所有数据都在内存里,一旦 Python 进程结束,智能体就“失忆”。
这套方案适合 demo,不适合长期陪伴型智能体。
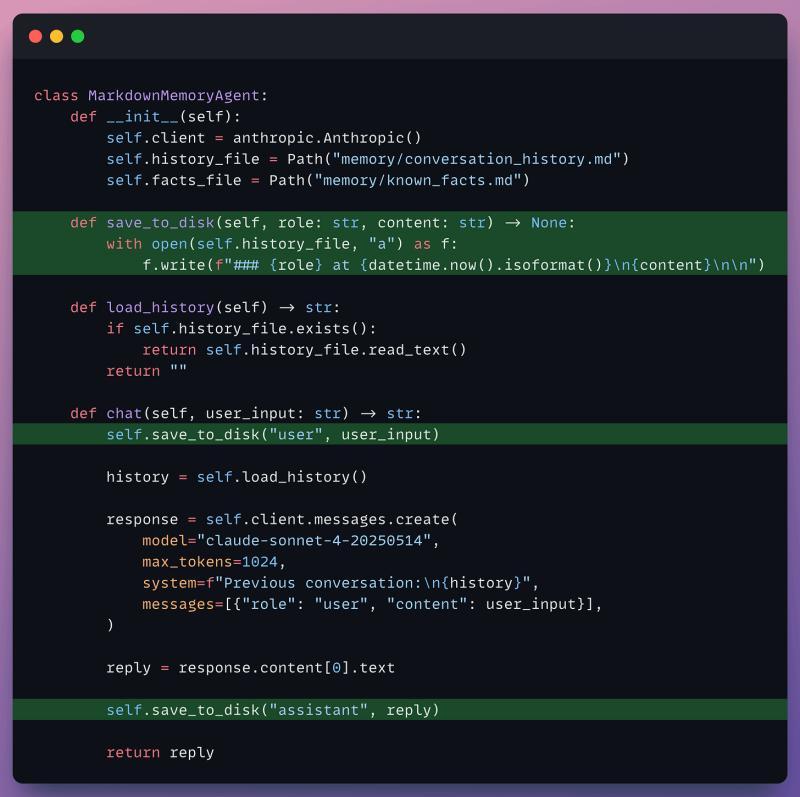
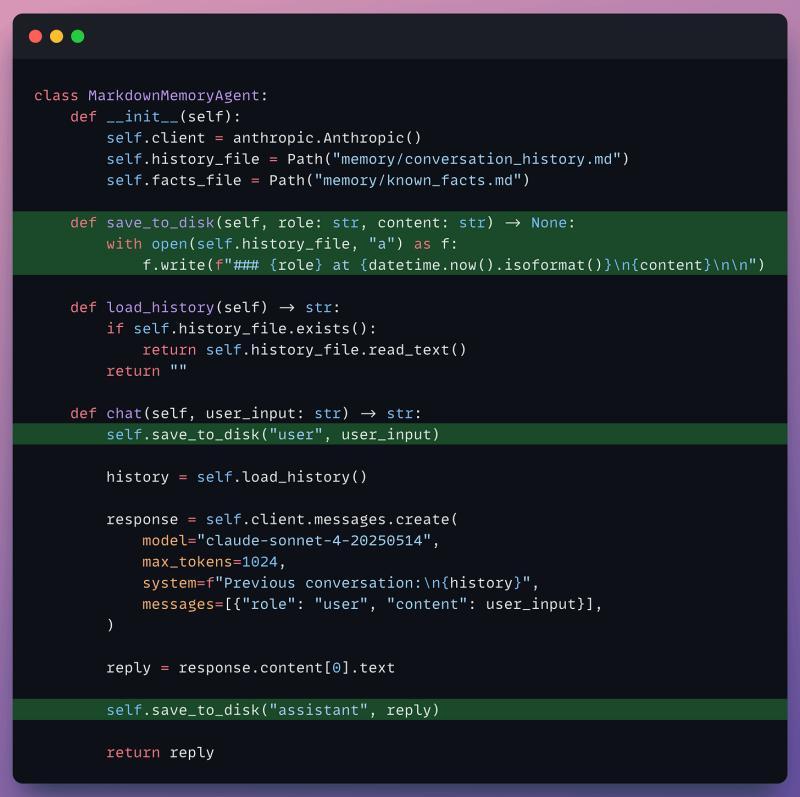
第二层:Markdown 持久化,原型期很好用
往前走一步,把记忆写到磁盘上。Markdown 是个很自然的选择:
- 人类可读,方便调试和手工修正。
- 支持 Git 版本管理,变更可追踪。
- 对 LLM 来说就是普通文本,读取无门槛。
Claude Code 的做法就是用 CLAUDE.md 和 MEMORY.md 这类文件:
你可以再维护一个“事实文件”,让智能体从对话中抽取结构化事实:

当事实只有 4 条时,这种方式几乎完美:把整个文件加载进上下文,模型就能回答关于 Sarah、她的公司和行业的各种问题。你也能随时打开文件,看清楚“它到底知道了什么”。

Markdown 的天花板:规模一大就只能靠关键词
问题出在时间维度。假设三个月后,你的智能体已经积累了:
- 2000 条抽取事实
- 200 条对话日志
- 总计超过 50 万令牌的 Markdown 内容
而你的上下文窗口只有 128K,根本不可能一次性全部加载。你被迫要“有选择地”检索相关事实。用平面文件,唯一现实的办法就是关键词搜索:
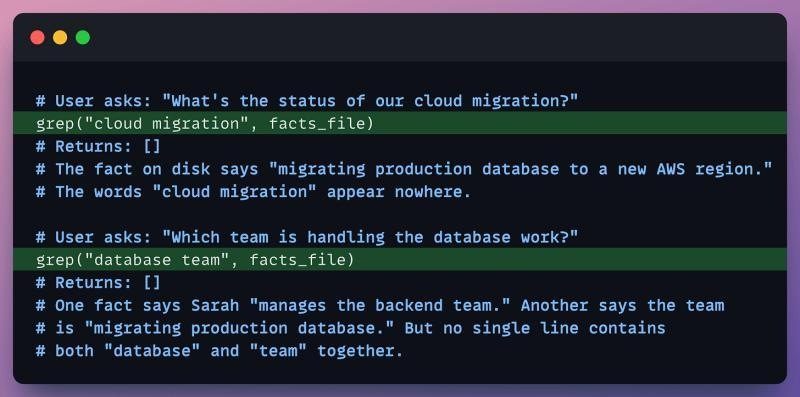
关键词检索在小规模下还能凑合,一旦内容多起来,就会暴露出几个硬伤:
- 无法处理同义词和改写(“退款”和“退钱”被当成两回事)。
- 很难跨文档建立关联,事实之间是割裂的。
- 早期重要事实会被埋没在海量文本里。
有个开源项目 OpenClaw 就是把记忆存成 Markdown 检查点文件,结果几周日常使用后,早期关键事实在上下文压缩和截断中悄然消失——存是存了,检索不到,一样等于没记住。
第三层:向量搜索,解决语义但没解决关系
为了摆脱关键词的局限,下一步通常是:
- 把 Markdown 按段落或语义块切分。
- 为每个块生成向量嵌入。
- 用余弦相似度做向量检索。
这一步能显著提升“语义匹配”能力,比如“退钱”和“退款”会被识别为相近概念。但会冒出一个新问题。
看下面这个向量数据库里的三条事实:
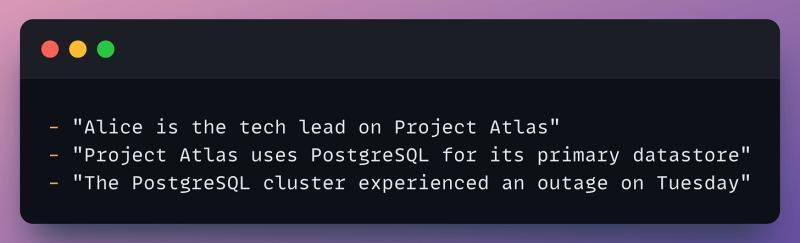
用户问:“Alice 的项目是否受到了周二宕机的影响?”
- 查询里提到了 Alice 和“周二宕机”,向量搜索会优先返回第一条和第三条事实。
- 但关键桥梁是“Project Atlas 使用 PostgreSQL”——它既没提 Alice,也没提周二,却是连接两边的唯一纽带。
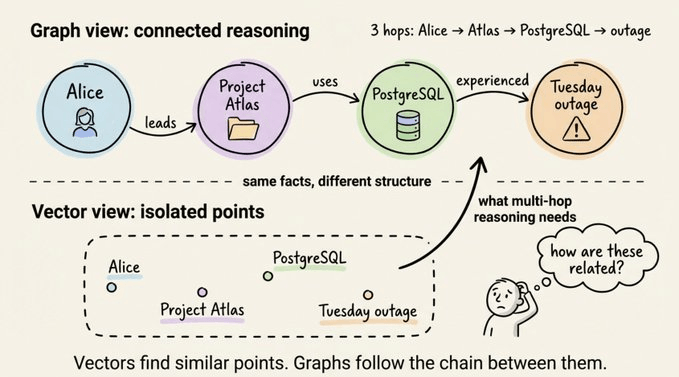
在嵌入空间里,每条事实都是一个孤立点,点与点之间的“关系”对向量来说是不可见的。任何需要跨两跳、三跳才能推理出来的问题,都会超出纯向量检索的能力范围。
现实业务里,这种多跳关系几乎无处不在:
- 客户–合同–产品–版本–漏洞
- 员工–部门–项目–预算–审批人
这也是为什么很多企业 RAG 项目上线后,用户评价是“能搜到东西,但问复杂一点就开始胡说八道”。
能力矩阵:记忆层到底要具备什么
三种能力,缺一不可
回顾这三层演进,每一层都解决了前一层的问题,却暴露出更深的痛点:
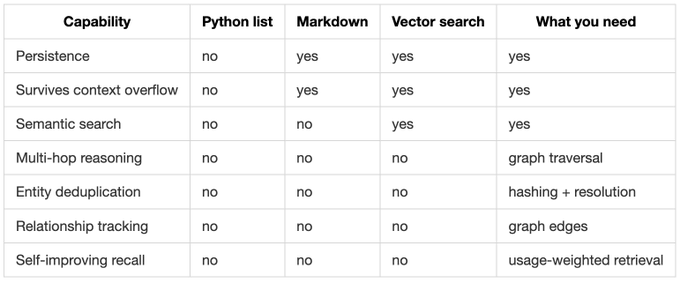
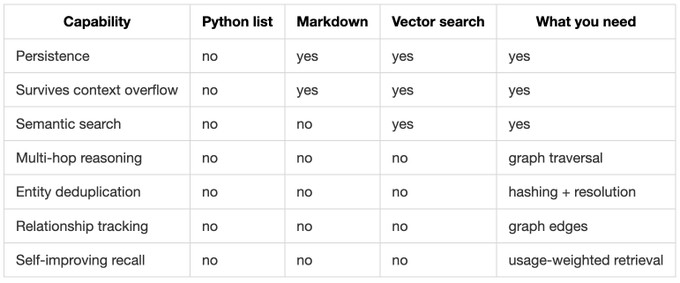
一个可用的记忆层,至少要同时具备三种能力:
- 持久性:记得住,进程重启、版本升级都不会丢。
- 语义理解:能按“意思”而不是按“字面”去匹配。
- 关系推理:能跨实体、跨多跳地回答问题。
很多团队会在这里掉进一个误区:以为“选一个最强的数据库”就够了。但关系型、向量、图这三种存储,其实各自擅长完全不同的维度,硬要用一个去替代另一个,体验会非常糟糕。
自己拼一套,为什么这么难
如果你打算自己从零搭一套记忆层,大致要做这些事:
- 选型并部署向量数据库、图数据库、关系存储。
- 设计实体抽取和关系抽取的 LLM 管道。
- 做去重、合并、版本控制和权限控制。
- 设计边权重、衰减策略和多跳检索算法。
很多团队在写出第一行“智能体逻辑”之前,就已经在基础设施上耗掉了几周时间。而且说实话,做完这一切,记忆层本身还不一定“会从使用中学习”。
Cognee:把三种存储揉成一层记忆
Cognee 是什么:为智能体记忆设计的知识引擎
Cognee 是一个专门为智能体记忆打造的开源知识引擎,它把向量搜索、知识图谱和关系溯源层整合在一起,对外只暴露非常简单的 API。
整个系统底层是一个“三存储架构”:
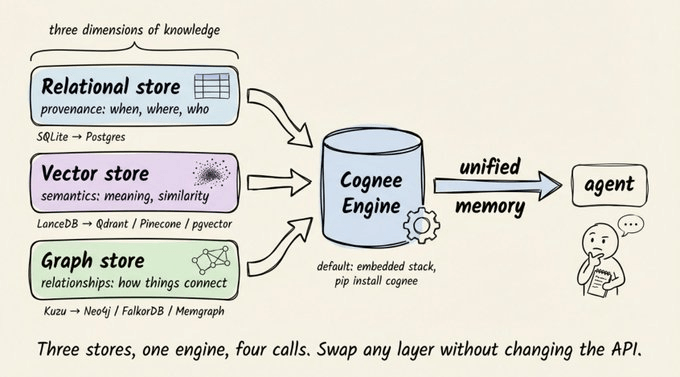
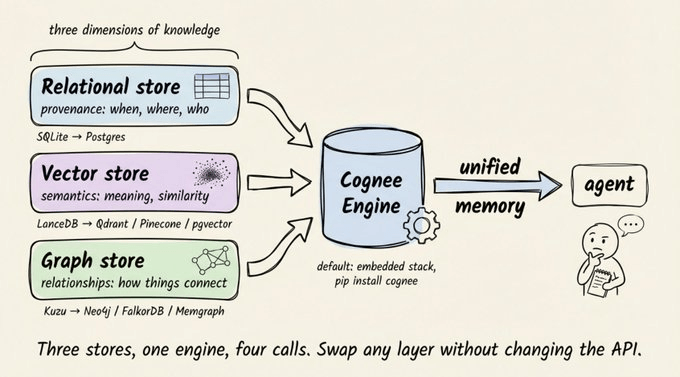
每一层负责捕捉不同维度的信息:
- 关系存储 → 溯源信息:数据来源、摄取时间、访问权限等。
- 向量存储 → 语义信息:内容含义、相似度、语义邻居。
- 图存储 → 关系信息:实体之间的连接、因果链、上下级关系。
如果把其中任意一层“扁平化”,都会丢掉对检索准确性至关重要的信号。
cognify:把原始文本变成结构化知识
cognee.cognify() 是入口函数,它会跑一条多阶段管道,把原始文本转成结构化、互联的知识:
- 按类型和领域对文档分类。
- 做多租户访问控制的权限检查。
- 按段落结构切分块,而不是机械按字数切。
- 用 LLM 抽取实体和关系,并通过内容哈希自动去重。
- 生成摘要,提升后续检索效率。
- 同时写入向量存储(嵌入)和图存储(边和节点)。
去重这一步非常关键。如果同一个实体在 50 个文档里出现,Cognee 会把它们合并成一个图节点,挂上 50 条入边。
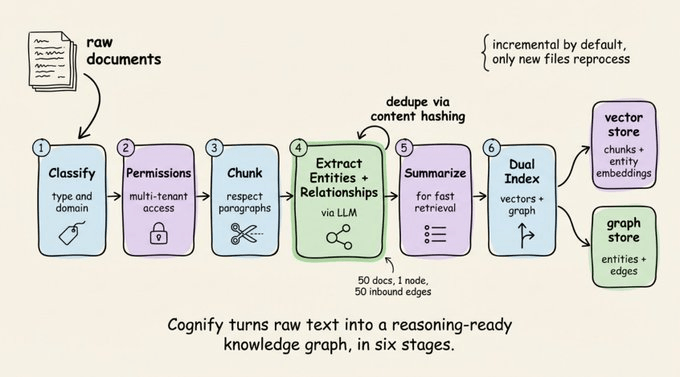
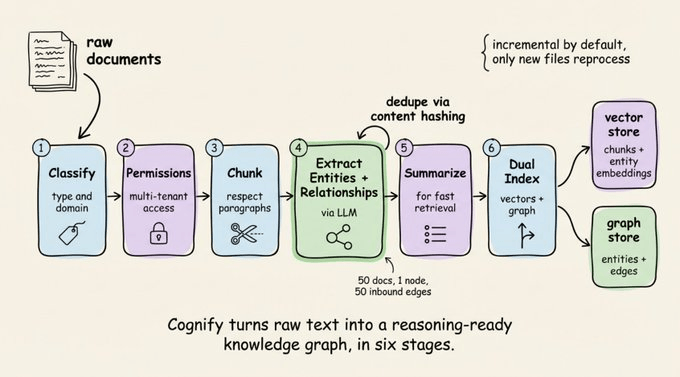
这样你的智能体不会把 “Alice” 当成 50 个人,而是一个在不同上下文中被提及的同一实体。管道默认是增量的,只会重新处理新增或更新的文件,成本也可控。
双重表示:向量入口,图出口
每个图节点都会有对应的嵌入向量,这个设计是 Cognee 的关键技巧:
- 你可以先用向量搜索找到语义上最相关的节点。
- 然后沿着图的边向外扩展,追踪相关实体和事件。
- 也可以反过来,从某个实体出发,在图上走几跳,再对结果做语义过滤。
这让多跳查询在不牺牲语义搜索能力的前提下变得可行。比如前面那个问题:“Alice 的项目是否受周二宕机影响?”——在 Cognee 里就可以通过“周二宕机 → PostgreSQL 集群 → Project Atlas → Alice”这条路径推出来。
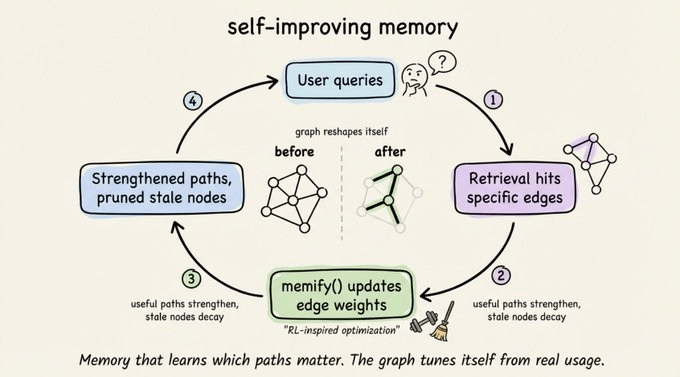
Memify:让记忆自己“长出重点”
图上的“强化学习”:用得多的路更宽
memify() 是 Cognee 里另一个有意思的工具,它会在知识图上跑一个类似强化学习的过程:
- 强化那些经常带来好检索结果的路径。
- 削弱长期没人访问的陈旧节点。
- 根据实际使用情况自动调整边权重。
- 通过识别隐含关系,生成一些派生事实。
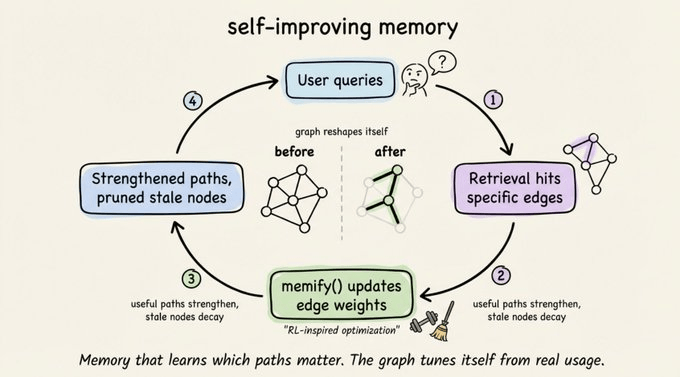
举个例子:一个客服智能体的知识图,随着时间推移,会自然强化“产品文档 → 常见问题 → 退款政策”这条路径,而把几乎没人问的人力资源相关边慢慢淡化。图谱会逐渐形成自己的“相关性直觉”。
说实话,我也不太确定这个类比是不是完全准确,但从使用反馈看,这种“用得多的路更宽”的机制,确实能让检索结果越来越贴近真实需求。
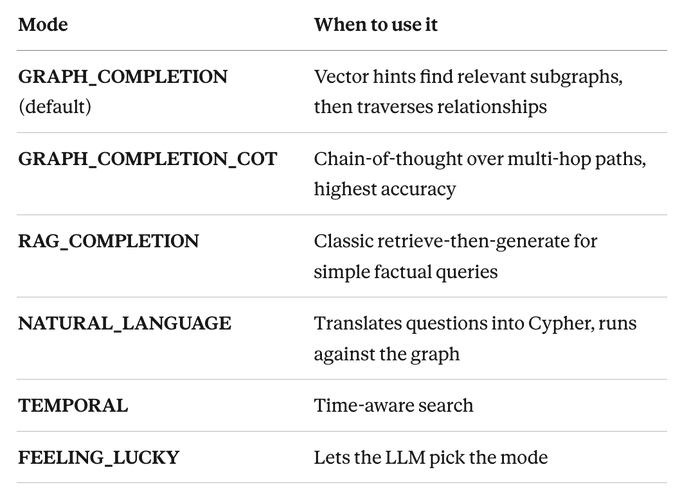
十四种检索模式:不止是“搜一段文本”
Cognee 内置了 14 种搜索模式,覆盖了从简单相似度搜索到复杂图遍历的各种场景:
常用的包括:
- 纯向量搜索:找语义相似的内容片段。
- 图邻域搜索:围绕某个实体找一度、二度关系。
- 语义 + 图混合搜索:先按语义筛,再沿图扩展。
- 溯源搜索:按来源、时间、权限过滤结果。
这类模式在企业环境里尤其重要,因为很多问题本质上是“在某个子图里做语义检索”,而不是在整个知识库里盲搜。
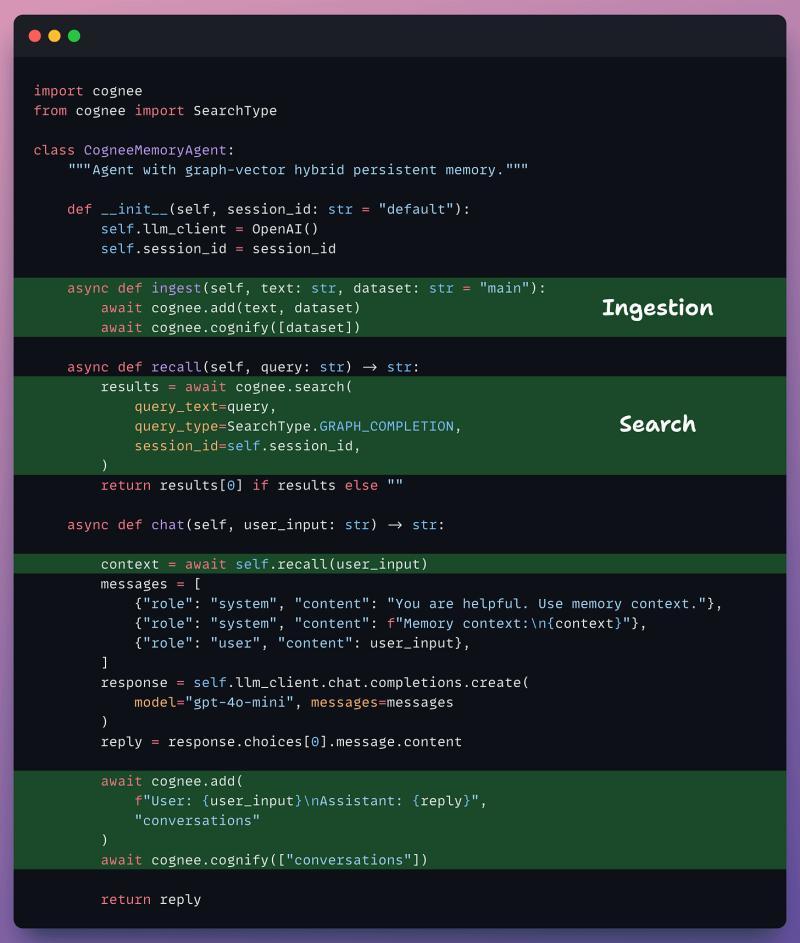
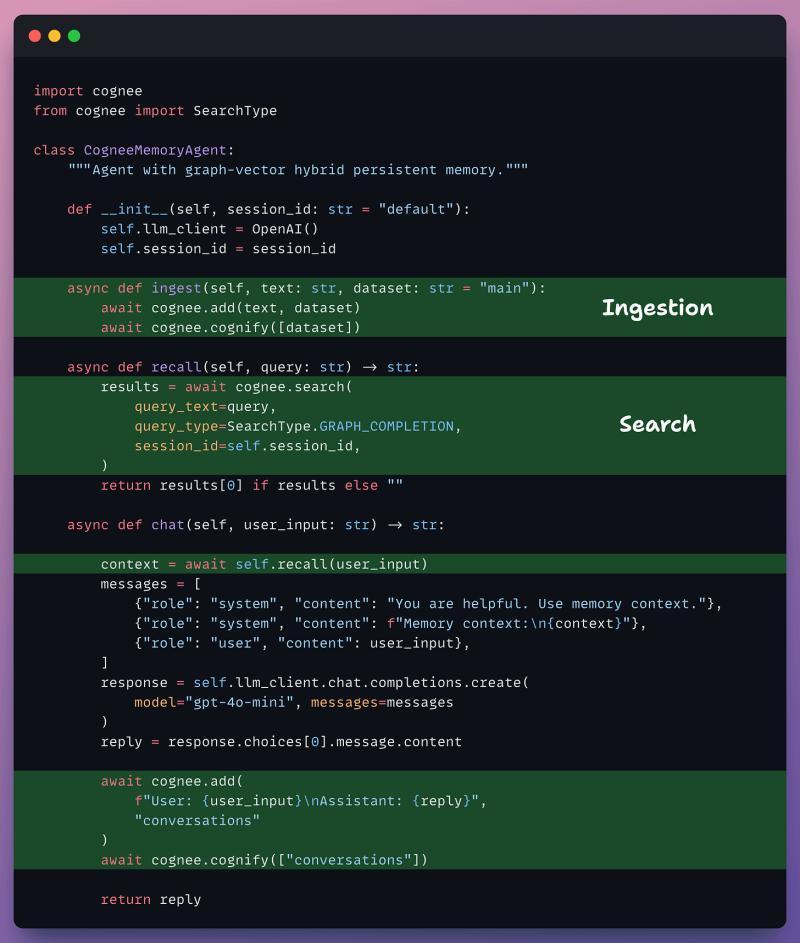
把 Cognee 接入智能体循环
记忆周期:从摄取到再次存储
当你把 Cognee 接入智能体的感知–思考–行动循环后,整体模式会变成一个“记忆周期”:
- 摄取:把对话、文档、日志等原始数据送进 cognify 管道。
- 抽取:识别实体、关系、事实和摘要。
- 存储:写入向量库、图库和关系库。
- 检索:在每轮对话前,从记忆层拉取相关上下文。
- 响应:LLM 结合检索结果生成回答或行动计划。
- 再次存储:把新产生的关键信息回写到记忆层。
每一轮对话都会丰富知识图谱,增量处理意味着你只为新增内容付索引成本,而不是每次都重建整个库。
会话记忆、代词消解和多租户权限
Cognee 的会话记忆层还能自动处理代词消解这类细节:
比如用户说“我昨天提到的那个项目”,系统能在当前会话和长期记忆里找到“那个项目”具体指什么,而不是让用户一遍遍重复。
多租户权限控制则是在图层面实现的:
- 每个节点和边都可以挂读、写、删、共享等权限。
- 检索时自动过滤掉用户无权访问的子图。
- 方便在同一套基础设施上服务多个团队或客户。
这类设计在企业落地时非常关键,也是很多“玩具级”记忆方案难以跨越的门槛。
一个实用的判断标准:你到底需要什么记忆
如果你现在正打算做一个智能体,起点问题不应该是“用哪个模型”,而是:
我的智能体需要记住什么?它要回答什么类型的问题?
可以用一个简单的判断标准:
- 如果问题只需要“找类似内容”(比如“找和这段话类似的对话”),纯向量记忆就够用。
- 如果问题经常跨实体、跨多跳(比如“Alice 的项目是否受周二宕机影响?”),就必须引入图遍历。
- 如果还涉及审计、合规、权限等要求,就需要关系存储来做溯源和访问控制。
你当然可以自己把向量、图和关系存储拼在一起,但那意味着要在基础设施上投入大量时间,而且记忆层本身未必会“越用越聪明”。
Cognee 把这些能力压缩成了四个 API 调用,内置默认配置让你几分钟内就能跑起来。底层可以切换 Postgres、Qdrant、Neo4j 等后端,迁移到生产环境时也不用改智能体逻辑。
智能的关键不在于“存了多少”,而在于“结构得怎样”。关系型、向量和图这三种存储范式,不是互相竞争的备选方案,而是同一记忆系统里互补的三层。
如果你正准备做一个“不会忘记你”的智能体,这套记忆设计思路,可能比问十个朋友要更有参考价值。等哪天你发现它真的记住了几个月前的一句细节,那一刻的惊喜挺值得被提前准备好。
常见问题
Q:只用向量数据库做记忆,能不能支撑一个企业级智能体?
A:在很多简单场景下,只用向量数据库也能跑起来,但要支撑企业级智能体通常不够。原因在于企业问题往往跨多个实体和多跳关系,比如“某客户的哪些项目会受某次变更影响”,这类问题需要沿着客户–合同–项目–配置的链路推理。纯向量检索只能按语义相似度找“看起来像”的片段,很难保证关系完整。更稳妥的做法是:用向量做语义入口,再用图存储承载实体关系,用关系型存储做溯源和权限,这样既能搜得准,也能解释得清。
Q:我的应用对话量不大,有必要上复杂的记忆系统吗?
A:对话量不大时,可以从轻量方案起步,但最好一开始就按“可演进”的思路设计。原因是:记忆问题往往不是在第 10 次对话暴露,而是在第 100 次、第 1000 次时突然变成大坑。你可以先用 Markdown 或简单数据库做持久化,同时预留一个“检索接口层”,后面再把实现换成向量+图而不改业务逻辑。建议至少提前想清楚三件事:要存多久、要不要多用户隔离、未来是否需要审计和回溯,这会决定你后面迁移的成本。
Q:如何判断一个智能体的记忆设计是不是健康的?
A:可以用三个信号快速体检。第一,看它是否会反复询问已经提供过的关键信息,如果会,说明短期记忆或检索有问题。第二,观察它是否能记住长期偏好,比如邮件风格、汇报格式,这反映长期记忆是否有结构化存储。第三,问一些跨多跳的问题,例如“上周你帮我写的那份方案里,第二部分的结论现在还适用吗”,看它能否定位到具体内容并给出有根据的判断。若三项都表现不错,说明记忆层基本健康;否则就要从存储结构和检索策略两头排查。
Q:引入图数据库会不会让系统变得很重、很难维护?
A:图数据库确实比单一向量库更复杂,但并不一定意味着“难以维护到不可用”。难点主要在两方面:一是建模,要提前想清楚哪些实体和关系值得上图;二是运维,要监控图规模、查询延迟和索引策略。可操作的建议是:从局部图开始,比如只为“用户–项目–事件”这条链路建图,其它部分仍用向量检索。等这部分跑顺了,再逐步扩展。像 Cognee 这种把图层封装在记忆引擎里的方案,可以显著降低你直接和图数据库打交道的复杂度。
Q:开源记忆引擎会不会有数据安全和隐私风险?
A:风险主要不在“开源”本身,而在你如何部署和配置。开源的好处是你可以审查代码、自己托管,避免把敏感数据交给第三方服务,但如果权限控制、加密和审计没做好,同样会有泄露隐患。比较稳妥的做法是:在内网或私有云中部署记忆引擎,开启传输和存储加密;在图和关系层面实现细粒度权限;对所有检索和写入操作做日志记录,便于事后审计。选型时也要看项目是否支持多租户隔离和访问控制,这些都是企业落地时绕不过去的硬指标。


