由美国Intel和AMD组成的The x86 Ecosystem Advisory Group(EAG)于4月27日发布了关于x86架构的AI计算扩展(ACE)的白皮书。此次发布的仍是白皮书阶段,具体指令规格尚未公开,但通过示例代码(Instinct形式)已足以让人理解其大致内容。本文将介绍这次白皮书的核心内容。
EAG的成立背景已在2024年10月的报道中介绍过,这里不再赘述。值得一提的是,成员企业新增了美国Adobe和Nutanix,目前共有12家公司和2位顾问参与。
EAG成立后发布的指令标准回顾
EAG成立一年后的2025年10月13日,发布了首个标准化提案“Standardizing x86 features”,确定了未来x86将支持的四类标准指令:FRED、AVX10、ChkTag和ACE(高级矩阵扩展)。
其中,FRED已在2023年12月的报道中详细介绍。AVX10则是为了解决AVX512指令种类繁多、支持情况复杂的问题,将其统一整理为AVX10标准。AVX512本身是512位指令,但部分指令如AVX512_VNNI后来被回溯支持为256位版本AVX2_VNNI,导致指令支持不一。AVX10旨在统一这些指令,现阶段定义了10.1和10.2两个版本。
AVX10.1基本是AVX512的整合版本,AVX10.2则新增了多项指令,包括:
- 新数据类型E5M2/E4M3 FP8(符合OCP 8-bit浮点规范)
- 新媒体指令VMPSADBW(512位扩展)及16位VNNI的符号支持扩展
- 支持IEEE754-2019 NaN行为的min/max指令
- 饱和转换指令
- 零扩展向量复制指令
- 浮点标量比较指令
ChkTag是Intel于2025年10月13日公开的内存标签机制,类似于Arm的MTE(内存标签扩展),具体规格预计2025年下半年公布,目前尚未公开详细信息。
新增的ACE(AI计算扩展)详解
此前FRED、AVX10和ChkTag已有较多细节披露,唯独ACE细节不明。官方仅表示ACE标准化了矩阵乘法能力,支持从笔记本到数据中心服务器的无缝开发体验。
ACE主要利用ZMM寄存器(AVX512扩展的512位寄存器)进行矩阵运算,具体是计算外积(Outer Product)。一般矩阵运算单元多支持乘加运算(GEMM),因其广泛应用于卷积神经网络等,且硬件实现紧凑。NVIDIA的Tensor Core、Intel的AMX、Arm的SME/SME2均采用乘加运算单元。
不过,IBM POWER10的MMA(矩阵数学辅助)是少数支持外积计算的加速器,能更高效地完成外积和卷积运算,避免乘加运算单元的额外计算步骤。ACE在这方面实现了更进一步的加速。
ACE中,ZMM寄存器以16×4的形式存储64个8位数值,或8×4存储32个16位数值,计算两个输入的外积(内部以32位计算),结果大概率以16位存储。
例如8位数据时,ZMM寄存器可存储16组数据,共256个外积运算。每个外积包含4次乘法和1次加法,理论运算次数为256×5=1280次,但白皮书中未计加法,标注为1024次。
ACE新增了子瓦片寄存器(Sub Tile Register)用于存储外积结果,规格为512位×16行,共16个寄存器(每个结果占2个512位寄存器)。
示例代码显示,外积输出寄存器类型为“__tile1024i”,即程序视为1024位整数寄存器,实际由两个512位寄存器组成,不能单独操作。
ACE提供8组子瓦片寄存器,支持虚拟处理更大矩阵(如64×32),虽然需要8个周期,但减少了数据加载次数,提高了实际性能。
ACE单元的实现方式
ACE矩阵计算单元有两种实现方式:
-
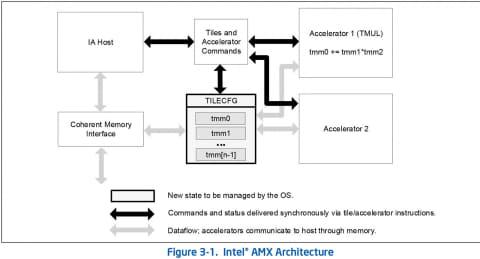
与CPU核心完全分离,作为加速器存在,拥有独立寄存器和计算单元。Intel AMX即采用此方案,CPU核心通过Tiles and Accelerator Commands模块与AMX通信,指令如TILELOADD、TILESTORED和TDPBUSD用于数据传输和计算,计算过程脱离CPU指令流水线。
-
将矩阵计算单元集成到CPU核心内部。IBM POWER10采用此方案,Matrix SIMD单元集成于核心,支持4×4矩阵外积,每周期256次运算,4个单元合计1024次,性能与ACE峰值相当。
考虑到核心面积和功耗,桌面及移动CPU更适合第一种方案,服务器CPU则可能采用第二种。Intel可能在P核集群或E核集群中配置ACE单元,AMD则可能在CCX中配置1-2个。
ACE与AMX的区别包括:
- ACE可直接使用ZMM寄存器作为输入,AMX需先复制到瓦片寄存器
- ACE单元数量不一定与核心数一一对应
- ACE支持OCP标准的MX格式(微缩浮点格式)
OCP MX格式介绍
浮点数通常由符号、指数和尾数组成。对于8位甚至更低位宽的数据,指数和尾数位数不足,难以保证精度。
OCP定义的MX(Microscaling)格式将指数和尾数分开存储,多个数共享一个指数,尾数单独存储。例如:
A: 123.4
B: 154.3
C: 90.7
转换为MX格式后:
A: 1.234
B: 1.543
C: 0.97
共同指数: 2 (10^2)
这样即使数据位宽小,也能保持较好精度。ACE支持BF16和INT8运算,也能使用MXFP8、MXFP6、MXFP4格式。
MX格式使用Block Scale Register管理,虽然ACE暂未支持4位精度运算,但能直接处理MXFP4格式,提升灵活性。
性能与展望
白皮书称ACE每周期运算性能可提升16倍,但实际性能取决于ACE单元数量。若每核心配备1个ACE,性能提升16倍;若1个ACE服务8核心,则提升约2倍。
ACE性能虽不及GPU或NPU,但相较传统x86矩阵运算已有显著提升。考虑到ACE仅支持INT8和BF16,科学计算和音频处理等领域受限,推测ACE定位明确为AI计算加速。
结语
值得一提的是,白皮书作者中包括AMD的8位架构师Michael Clark和Intel资深架构师Pradeep Dubey等业界重量级人物,显示该项目的技术深度和行业影响力。
这份白皮书不仅展现了x86生态系统在AI计算领域的最新进展,也体现了半导体行业跨公司合作的力量。