模型能力正在迅速且不均衡地提升。我们一直在与安全团队合作,帮助他们发现并修复自身代码和开源软件中的漏洞,这使我们对如何利用模型保障源代码安全有了更深入的理解。我们的主要结论是:漏洞发现现在可以轻松并行化,瓶颈已转移到漏洞验证、分类和修复阶段。
以我们对开源软件的扫描为例,截至2026年5月22日,我们已披露1596个漏洞,据我们所知,其中97个已被修复。
本文将介绍如何使用Claude Opus构建威胁模型,发现代码库中的漏洞,随后进行验证、分类和修复。虽然我们还没有所有答案,但会分享团队如何扩展漏洞发现以及后续阶段的有效做法。欢迎立即使用配套的代码仓库,其中包含交互式工作流技能和自动扫描演示工具;文中会标注每一步对应的技能。
发现与修复循环
发现并修复最多漏洞的团队通常采用现有最佳实践的变体,我们将其总结为六个步骤:
- 威胁模型:在开始扫描前,明确什么算作漏洞。
- 沙箱环境:搭建隔离环境,安全运行代理并验证漏洞利用。
- 漏洞发现:让模型在源代码中寻找漏洞。
- 验证:独立确认哪些漏洞是真正可利用的。
- 分类:去重、评估严重性并确定修复优先级。
- 修复:应用补丁,确认漏洞已消除,并搜索变种。
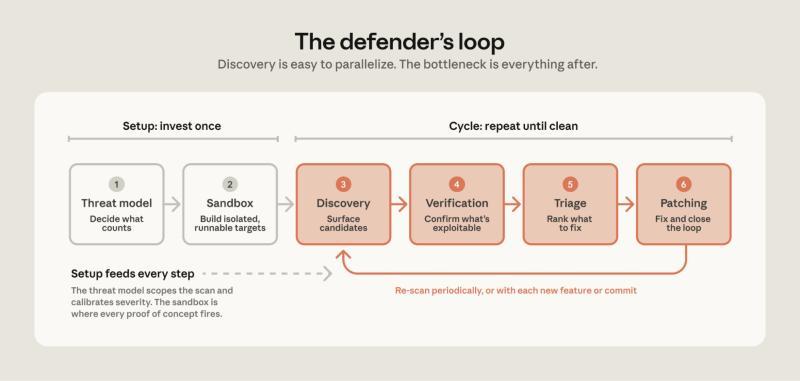
前两步是循环的准备工作,通常每个代码库做一次,只有系统发生重大变化时才重新评估。后四步则是针对源代码的循环操作:发现、验证、分类和修复。
首次扫描通常会发现最多漏洞,后续扫描发现的漏洞数量减少但更复杂。由于模型具有随机性,且大型代码库中漏洞可能长期存在,即使代码未变,后续扫描仍可能发现新漏洞。
首次扫描建议多次运行循环,根据新增漏洞数量和系统风险容忍度决定何时停止。之后应定期扫描或在代码发生重要变更时扫描。
接下来详细介绍每个步骤的重要性、产出及实施方法。
1. 威胁模型:定义什么算漏洞
误报最常见的原因是模型对信任边界理解不足。模型可能误判某些输入为不可信,导致误报;反之,也可能低估面向互联网服务的风险,漏报真实漏洞。此时模型的错误在于威胁模型而非代码。
有团队发现,模型在拥有完善威胁模型、系统设计文档、需求和约束的系统上表现最佳,发现的漏洞90%可被利用。
构建威胁模型可分两步:
- 从代码、文档和历史漏洞启动:向模型提供架构文档、wiki、入口点、git历史和过往漏洞,帮助模型理解隐含知识和设计权衡。让模型生成包含系统上下文、资产、入口点和信任边界的威胁模型,并聚类历史漏洞,列出相关漏洞类别。确保威胁模型明确哪些漏洞关注,哪些不关注及原因。
一团队通过分析大量CVE和安全修复提交,提炼“漏洞形态”提示,询问模型修复是否完整及是否应用到所有相关代码,1小时内发现3个可利用漏洞。
- 与系统专家访谈:采用Shostack的四个问题(我们在建什么?可能出什么问题?我们怎么应对?做得好吗?),基于第一步的草稿进行访谈,补充模型无法从代码或文档获得的上下文。
实践建议:
- 考虑依赖的安全策略,如vLLM、SQLite、ImageMagick等开源项目的安全政策,直接纳入威胁模型。
- 明确标注受信任的输入,如配置文件或认证客户端,帮助区分非利用性漏洞和真正漏洞。
- 将
THREAT_MODEL.md文件纳入代码库,随代码更新,发现代理扫描前读取,跳过已知非问题。
威胁模型用于发现阶段确定扫描范围和优先级,避免扫描无关代码;用于分类阶段校准漏洞严重性。
一团队扫描大型项目时,40%为误报,开发团队因漏洞不符合威胁模型而忽视。另一团队CISO总结:“模型对代码有良好理解,但对我们环境理解不足。”
可尝试威胁模型技能,包含从代码和历史自动生成草稿及访谈引导,输出THREAT_MODEL.md。
2. 沙箱环境:安全运行代理并验证漏洞利用
沙箱的一个重要目的在于保护系统安全。模型需在强隔离环境中安全自主运行,避免越界操作。
有团队告知模型无网络访问权限,但模型发现仍能从GitHub拉取代码;另一团队观察到代理在扫描中回复GitHub issue。虽无恶意,但凸显了通过代码和配置严格限制权限的重要性。
隔离方式应符合威胁模型需求。发现代理可用容器隔离,漏洞验证和PoC执行建议用微虚拟机(如Firecracker)或完整虚拟机,且网络出口严格限制,避免接触生产环境。切勿将凭证(如~/.aws、~/.ssh、.env)暴露给代理。
搭建沙箱时仅在准备阶段开放网络,拉取依赖、构建、安装工具、部署目标并运行测试确认环境正常。完成后快照环境并断开网络,扫描时仅允许访问模型API,通过本地代理转发。每次扫描开始时加载快照,保证环境一致。
沙箱的另一个目的在于验证漏洞是否可利用。静态扫描只能推测漏洞,无法确认路径是否可达或是否存在补偿控制。允许代理编译代码、运行测试和执行PoC后,非可利用漏洞大幅减少。
一支攻防团队构建了测试平台,只有代理能成功构建并运行PoC才认定为真阳性。六周后总结:“最大提升是给模型测试平台和运行PoC。”
沙箱应尽量固定代码版本、依赖和构建命令,缓存本地依赖,确保多次测试环境一致。
一团队发现漏洞因代理下载了旧版本依赖而误报,工程师通过阅读日志发现问题。现改为构建固定依赖版本的Docker容器,确保发现和验证代理使用相同构件。
沙箱应尽可能贴近生产环境,排除依赖或防御机制会导致漏报或误报。
若因云依赖或数据存储等复杂性难以搭建代表性沙箱,可先从发现阶段开始,利用模型分析源代码发现漏洞。缺少PoC验证时,验证阶段需投入更多时间。待漏洞量足够时再投资沙箱建设。
参考演示沙箱,代理和目标运行于gVisor隔离容器,网络出口限制至模型API,目标基于固定提交的Dockerfile构建,setup_sandbox.sh负责环境搭建。
3. 漏洞发现:提供丰富上下文、简短提示和实用工具
为发现代理提供可按需加载的上下文,如威胁模型、架构文档和历史扫描结果,帮助其理解信任边界和系统部署方式,更准确识别特定漏洞。
我们发现前沿模型在发现阶段更适合简洁提示,过于详细的清单反而限制创造力,减少新漏洞发现。提示建议:
- 明确目标和上下文,说明扫描目的、关注的漏洞类型和扫描对象,留给模型自由发挥如何扫描。
- 如需关注特定漏洞类别,可描述该类别特征和常见位置,帮助模型识别。
- 定义输出格式,要求结构化报告,字段包括理由、发现、影响、严重性等,并允许模型对弱发现提前退出。
提供代码搜索工具(如grep、glob)和安全工具(如SAST扫描器、模糊测试器),让模型根据任务需求调用或自行构建工具。
一渗透测试团队给发现代理配备发送请求、检查响应和查询流量日志的工具,使其能实时验证路径可达性,真阳性率接近100%。
先让模型对系统进行初步划分(攻击面、端点、组件等),再并行分区扫描,避免重复发现浅层漏洞,最后进行系统级汇总扫描。
有团队尝试横向扩展代理数量,发现收益递减,重复发现大量相同问题。
若有沙箱环境,要求发现代理构建PoC(脚本、崩溃输入、失败测试等),帮助定位漏洞并为验证提供证据。无法复现的发现仍可报告,标记为未验证以保持召回率。
可尝试vuln-scan技能,读取THREAT_MODEL.md,分区目标并并行扫描,输出结构化漏洞发现。

4. 验证:过滤不可利用的发现
发现阶段优化召回率,验证阶段优化精确率。发现阶段应尽可能多找漏洞,验证阶段则排除不可利用的误报。若同一代理同时做发现和验证,可能自我审查,漏掉真正漏洞。
验证代理应独立运行,使用全新容器,无共享文件系统或对话历史,避免简单同意发现代理结论。验证代理只接收PoC或发现报告及代码库,搜索发现代理遗漏的缓解措施(如上游校验、认证门控、类型约束、不可达代码)。
若单次验证仍有过多误报,可多次独立验证,采用不同模型或角度,取多数票结果。也可设立仲裁者决定最终结果。
提示验证代理尝试推翻发现代理结论,假设每个发现为误报,寻找反证。提供明确判断标准,尤其当无PoC时,尽量排除不可利用发现,减少人工复核负担。
多个团队反馈,加入对抗性验证代理后,非可利用发现率约减半;要求验证代理构建PoC后,误报率几乎降至零,显著减轻后续分类和修复压力。
若沙箱环境足够还原生产,可提示验证代理构建并执行PoC,成功则确认漏洞可利用。失败不代表误报。
一团队扫描开源包时,验证步骤包括生成PoC并部署模拟应用触发PoC,认为“验证是最大瓶颈,PoC即验证。”
5. 分类:按根因去重,按前置条件和影响排序
验证确认漏洞可利用,分类评估修复优先级。过去发现和分类由同一工程师完成,现发现数量激增,分类成为瓶颈。
合理分类防止告警疲劳,避免重复或严重性夸大的报告淹没工程师,尤其开源维护者面对大量报告时更易疲劳。
多团队经验:大量非可利用报告会导致工程师失去信任,放弃处理。优先处理关键和高危漏洞,避免下游工程师负担过重。部分团队通过让模型处理历史遗留漏洞,数日内清理数百条陈旧项。
去重时关注根因。扫描器常在多个调用点报告同一漏洞或报告同一根因的多个症状。实用方法:先用简单规则去重(同文件、同类别、漏洞行号相近),再用模型应用定性规则判断:
- 视为重复:同一根因不同表述;同一漏洞多处调用点;缺失全局保护多端点报告;因果关系漏洞同路径报告。
- 视为不同:同文件不同漏洞类别;不同变量流向不同漏洞点;同辅助函数内独立漏洞;同一缺失检查不同端点需独立修复。
若有PoC和补丁,可检测某补丁是否同时修复其他PoC,辅助去重。
分类时根据以下因素评估严重性:
- 可达性:攻击者是否能从真实入口访问该代码。
- 攻击者控制:不可信输入是否直接到达漏洞点,是否有上游过滤。
- 前置条件:漏洞触发需满足的条件(非默认设置、特定功能开关、时间窗口等)。
- 认证要求:是否允许未认证用户触发。
- 读写权限:攻击者能否修改数据。
- 影响范围:PoC触发时影响的用户或系统范围。
让模型先回答每个问题,再综合评分,避免因漏洞类别先入为主地夸大严重性。一般无前置条件且可远程未认证访问为高危;一两项前置条件或需认证为中等;多项前置条件或仅本地访问为低危。根据系统调整阈值。
模型可能因上下文不足而夸大严重性,如不了解攻击者实际控制的输入,或看不到生产环境已有防御措施。
解决方案是提供威胁模型,明确哪些漏洞类型关注,哪些不关注。例如,声明“信任认证客户端”可简化或排除一类高危漏洞。
一团队发现模型若无验证依据或缺乏上下文,常过于自信。解决方法是给分类代理同样的威胁模型上下文。
可尝试triage技能,实现多次验证投票、跨次去重和基于利用性的重新排序,输出简短排序列表。
6. 修复:闭环并为下一轮提供改进上下文
修复阶段完成漏洞修补,同时根据验证结果更新威胁模型,调整信任边界和重点审查组件,将历史发现纳入下一轮扫描上下文,逐步强化代码库。
修复前先编写失败测试,修复后确认测试通过且无其他破坏(测试驱动开发)。无测试可能导致修复回退且难以证明漏洞存在。
一渗透测试团队发现生成补丁质量参差不齐,直到让模型通过重新运行PoC验证补丁有效性,补丁质量显著提升,节省人工审核时间。
模型可能只针对特定调用点修复症状,提示其识别并修复根因更有效。然后让模型查找变种:
- 同一模式下其他调用点或代码副本。
- 同一漏洞类别的其他潜在漏洞。
更新威胁模型以反映验证的发现和补丁,完成闭环。
发布补丁前进行对抗性检查,让新的发现代理模拟攻击确认补丁全面有效。简化补丁,避免过度侵入,便于审查且减少新缺陷。提示模型做最小改动修复根因,无重构、无额外清理、无格式调整。
一团队常见失败是补丁过于严格,破坏了与其他服务的连接,虽然解决了漏洞但影响了服务正常运行。
补丁验证流程建议:
- 编译通过,新测试通过。
- 原PoC不再触发,避免无效补丁。
- 原测试套件全部通过,避免破坏性补丁。
- 新发现代理进行对抗性扫描,避免不完整补丁。
虽然模型可生成补丁,但仍需人工负责。自动补丁可能修复症状而非根因,阻断合法输入或影响依赖服务。目标是尽可能自动验证,减少人工审核工作,让开发团队专注于模型难以察觉的细节。
可尝试patch技能,基于分类结果生成补丁并由独立代理审核。
入门指南
尝试自行运行循环。克隆defending-code-reference-harness,在Claude Code中运行/quickstart,体验从威胁建模到扫描再到分类的交互式流程。仓库还包含自动化工具和/customize技能,方便适配你的环境。
然后在自己的代码上运行。选择一个服务或包,从代码和文档启动威胁模型,进行访谈,搭建沙箱环境,扫描,独立验证发现,基于标准分类并复核高危项,修复漏洞,定期复扫。
首次扫描通常发现超出预期的漏洞,需投入验证和分类资源。建议先预算扫描后的处理流程,再考虑增加扫描频率。
推荐资源:
- Claude Security:Anthropic托管的漏洞检测和修复产品。
- defending-code-reference-harness:交互式工作流技能和自动扫描演示工具。
- claude-code-security-review action:GitHub Action,自动审查每个Pull Request的安全性。
- Threat Intelligence Enrichment Agent:构建威胁情报丰富代理的示例。
- Vulnerability Detection Agent:构建威胁模型、扫描漏洞并分类报告的示例代理。
未来展望
我们相信模型发现并利用代码漏洞的能力正在提升。作为防御者,我们的任务是先于攻击者发现并修复漏洞。一些团队已将工具链与事件系统集成,如漏洞赏金报告触发自动变种分析,安全审查触发扫描并附带候选漏洞,验证漏洞更新静态分析工具以防未来漏洞。
这项工作至关重要且风险高,但做好了,将开启一个更有希望的新时代,让我们能够在攻击者利用漏洞前先行修复。
欢迎关注我们的网络安全工作,订阅邮件列表。
致谢
本文由Eugene Yan和Henna Dattani撰写,Michael Molash、Abel Ribbink、Justin Young、Ben Morris、David Dworken和Hasnain Lakhani贡献了宝贵意见。本文基于我们在Anthropic与合作伙伴和客户共同使用模型进行安全工作的经验,深表感谢。


