日本国家凸版控股公司开发出了一款能够解读通常被认为难以识别的中世纪希腊语的AI-OCR引擎。
古老文献中记载了许多具有历史价值的史实和地区文化信息,但这些文献大多以手写体形式存在,现代人难以辨认。
凸版印刷此前一直致力于支持日本历史资料的研究,专注于解读现代人难以识别的“くずし字”(草书体)古文书。早在2015年,便开始利用AI图像识别技术研发“くずし字OCR”,此次则将相关技术应用于中世纪希腊语的解读。
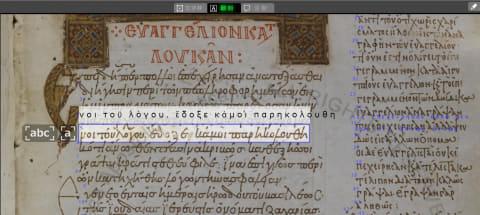
中世纪希腊语的书写形式因时代和作者不同而异,部分单词会被省略,拼写也与现代不同,且单词之间常无明显分隔,这些特点使得无专业知识的现代人难以阅读。该AI-OCR引擎通过学习包含百万字形和行数据的数据库,实现了对中世纪希腊语文字的识别。
此外,利用梵蒂冈教皇图书馆收藏的约5000件希腊语手稿中的50件(约400张IIIF图像)及其转录文本作为AI训练数据,结合专家的人工校对,提升了解读的准确性和质量保障。此举不仅加速了庞大希腊语手稿收藏的数字化进程,也使AI-OCR引擎的中世纪希腊语识别准确率达到95%以上成为可能。
该技术成果将于4月25日起在日本国家印刷博物馆举办的特别展览“名著诞生展 梵蒂冈教皇图书馆III+”中进行演示。