99% 的人谈 LoRA,只盯着“省显存、好微调”,却忽略了一个更关键的问题:不用 LoRA,这门生意根本做不大。要把 GPT-3 级别的大模型做成 SaaS 服务,技术细节背后,其实全是成本结构和商业模式的博弈。
我想换个角度聊 LoRA / QLoRA:不是从论文公式出发,而是从“OpenAI 怎么赚钱、你公司怎么省钱”出发,看清这套技术到底解决了哪些业务级难题。
一、为什么传统微调撑不起大模型生意?
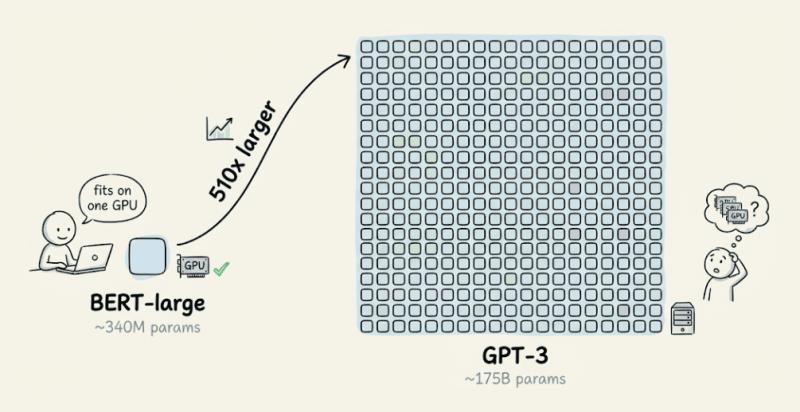
1. 从 BERT 到 GPT-3:参数量背后的成本炸弹
很多团队以为“BERT 都能单卡微调,GPT-3 也差不多”,这想法一旦落地到生产,就会变成灾难。先看一个直观对比:
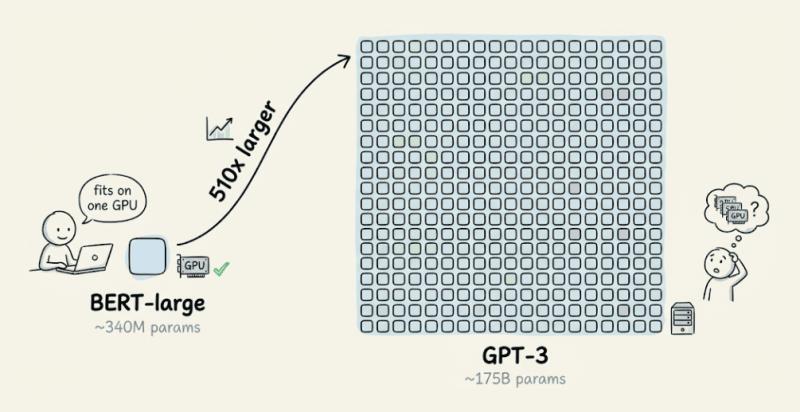
我们在内部多次用传统方式,在单块 GPU 上微调 BERT-large,体验还算顺滑:
但一旦换成 175B 参数的 GPT-3,故事就完全变了。仅仅存储 float16 精度的模型权重,就需要大约 350GB 显存,这还不算优化器状态、激活值等额外开销。现实里,你根本不可能在常规单机环境下用传统方式去微调它。
据公开资料估算,一台 8 卡 A100 服务器的月成本可以轻松上万人民币,如果为每个客户都复制一份 GPT-3 级模型,成本会呈指数级失控。
2. “一人一模型”的商业灾难:算一笔简单的账
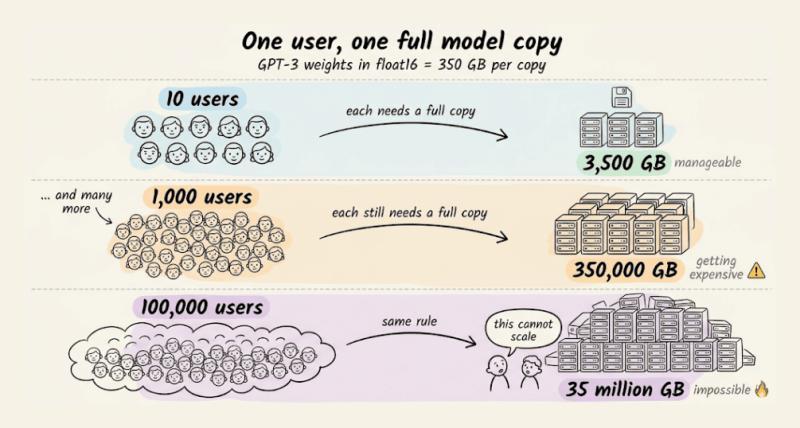
假设 OpenAI 用传统微调方式,在其 Fine-tuning API 里为每个用户维护一份独立模型副本,会发生什么?
- 10 个用户微调 GPT-3 → 需要约 3500 GB 存储模型权重
- 1000 个用户微调 GPT-3 → 需要约 35 万 GB
- 10 万个用户微调 GPT-3 → 需要约 3500 万 GB
问题还不止是存储:
- OpenAI 的计费是按调用量收费,不按“是否微调过”收费。如果有人只是为了学习体验微调了一版,从不调用推理,那这份 350GB 的模型就变成纯成本。
- 请求随时可能到来,服务端是否要把每个用户的微调模型都常驻内存?一旦常驻,大量几乎不用的模型会长期占用 GPU 资源。
- 如果按“谁用谁付”来设计产品,传统微调的成本结构会让这件事几乎无利可图。
我有个朋友在一家中型云厂做内部 LLM 服务,早期他们真试过给几个大客户“复制一份模型再微调”。结果三个月后,GPU 利用率长期低于 20%,但账单高得离谱,领导直接问:这玩意到底是技术创新,还是新的烧钱黑洞?
二、LoRA / QLoRA:技术细节背后的商业逻辑
1. LoRA 的核心思路:只训练“差异”,不动“本体”
LoRA(Low-Rank Adaptation)看起来是一个线性代数小技巧,实质上是对“谁来为个性化买单”的商业问题给出的工程解法。
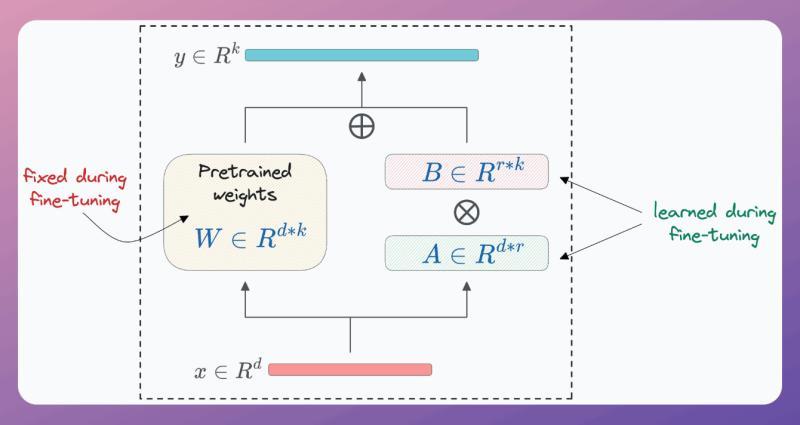
设原始模型某一层的权重矩阵为 W,形状为 d * d。LoRA 做的事情是:
- 为这层引入两个低秩矩阵
A(d * r)和B(r * d) - 其中 `r 有用户反馈,在中型企业内部部署中,用 LoRA 替代全量微调后,单个业务线的显存占用下降了约 90%,同时还能支持更多团队并行试验不同版本的微调模型。
3. QLoRA:在 LoRA 之上再压一层成本
QLoRA 可以理解为“量化 + LoRA”的组合拳:
- 把基座大模型权重量化到更低精度(如 4bit)以节省显存
- 在量化后的模型上,再叠加 LoRA 进行微调
这对那些想在单机或低成本云资源上玩转大模型的团队非常关键。尤其在 GPU 资源紧张、价格高企的当下,QLoRA 让“中小团队也能玩得起大模型微调”不再只是口号。
我也不太确定这个说法是不是绝对,但从最近开源社区的实践看:很多热门开源 LLM 的社区微调版本,背后几乎清一色是 LoRA / QLoRA,而不是全量微调。
三、LoRA 如何解决平台方的三大隐性难题?
1. 用户“玩票式微调”不再是成本黑洞
前面提到一个尴尬场景:
- 有人为了学习、试验,微调了一版模型
- 结果几乎从不调用推理接口
- 平台却要为这份模型长期付出存储和运维成本
在传统微调模式下,这种“玩票式微调”会直接侵蚀利润。而在 LoRA 模式下:
- 每个用户只占用几十 MB 的 LoRA 参数
- 即便 1 万个用户“微调完就扔”,总体存储成本也在可控范围内
- 平台可以更大胆地开放微调能力,甚至做免费额度、教育计划等增长策略
从商业设计角度看,LoRA 实际上给了平台一个“低成本试错池”,让更多用户可以低门槛尝试微调,而不会拖垮整体资源。
2. 推理资源调度:从“常驻”变成“按需挂载”
另一个现实问题是:
- 请求随时可能到来
- 如果为每个用户常驻一份微调模型在 GPU 上,资源会被大量闲置
LoRA 的小体积带来一个关键能力:
- LoRA 参数可以长期放在磁盘或对象存储中
- 当某个用户发起请求时,再把对应 LoRA 加载到内存 / GPU
- 一段时间不用,可以自动卸载,释放显存
这让平台可以:
- 用一套共享的推理集群,服务成千上万份“个性化模型”
- 通过简单的缓存策略(如 LRU)提升热门 LoRA 的命中率
- 把 GPU 资源真正用在“有人在用”的模型上
从工程实践看,这种“基座模型常驻 + LoRA 热加载”的架构,已经成为不少云厂和大厂内部平台的默认方案。
3. LoRA 也有坑:不是所有场景都适合
说实话,LoRA 也不是万能药,负面点也得摊开讲:
- 对于需要大幅改变模型行为的场景(比如从通用对话改成专业代码生成),LoRA 的效果可能不如全量微调稳定
- 多个 LoRA 叠加使用时,可能出现行为冲突,需要精心设计路由或合并策略
- 在极端高精度要求的任务上,LoRA 有时会带来轻微性能损失
风险提示:如果你的业务对错误极其敏感(如医疗诊断、金融风控),在采用 LoRA 方案前,务必做系统性的 A/B 测试和离线评估,而不是只看一两个 demo 效果。
四、从业务视角理解 LoRA / QLoRA 的价值
1. 你可以用 LoRA 做成哪些“可卖的钱”的能力?
站在产品和业务的角度,LoRA / QLoRA 能直接支撑的能力包括:
- 多租户个性化:为每个客户、每个业务线提供“专属模型”,但底层只维护一份基座
- 快速试验:产品团队可以频繁迭代不同微调版本,而不会被资源成本卡死
- 分层计费:基础调用按 token 收费,高阶用户为“专属 LoRA 微调”付额外费用
- 合规与隔离:不同客户的 LoRA 权重天然隔离,便于做权限和审计
有用户反馈,在引入 LoRA 后,他们把“一个通用客服机器人”升级成了“每个大客户一个专属机器人”,并按“专属模型服务费”单独计价,直接拉高了客单价。
2. 判断是否该上 LoRA / QLoRA 的三个信号
如果你在做大模型相关产品,可以用这三个问题快速判断:
- 用户是否需要明显的个性化行为?
- 比如每个客户有自己的语气、术语、知识库
- 是否存在大量“试试就好”的微调需求?
- 如内部团队、教育用户、黑客松参赛者
- GPU / 显存是否已经成为主要成本项?
- 账单里 GPU 占比超过 40%,就值得认真评估 LoRA / QLoRA
如果三个问题里有两个以上回答是“是”,那你大概率已经站在 LoRA 的使用场景里了,只是还没把它产品化。
这只是我自己的观察,但在最近一两年的 AI 创业项目里,凡是能把“个性化 + 成本控制”讲清楚的,大多都绕不开 LoRA / QLoRA 这条路。
五、想系统学“商业向 ML”,还能看什么?
如果你想把 LoRA 放进更大的“商业 ML”知识框架里,可以顺着这些方向继续挖:
- 量化(Quantization):如何把模型压到能在手机、边缘设备上跑
- 置信度与不确定性(Conformal Prediction):让模型的输出“敢说不知道”
- 训练扩展(Scaling Training):多机多卡、混合精度、数据并行等工程实践
- 生产测试(Production Testing):如何在真实流量下验证模型可靠性
- 隐私与合规(Federated Learning、模型压缩):在合规约束下做个性化
有用户反馈,把这些主题串起来学习一遍之后,再看大厂的 LLM 产品架构,很多设计就不再神秘,而是“哦,原来是为了这几笔账算得过来”。
如果你正在为“要不要上 LoRA / QLoRA、怎么设计计费和架构”纠结,这套判断思路可以反复拿出来对照,值得收藏一份留着和团队讨论。
常见问题
Q:我只在公司内部用一个大模型,还需要 LoRA 吗?
A:内部只用一个模型,也依然很可能需要 LoRA,尤其是当不同业务线都想要“自己的版本”时。原因在于:全量微调会让你为每个版本维护一整份模型副本,显存和存储成本会迅速膨胀,而且版本管理会变得非常混乱。更可行的做法是:维护一份统一的基座模型,用 LoRA 为不同业务线做轻量微调,并通过配置或路由选择对应的 LoRA 权重,这样既能满足个性化,又能把资源和运维成本压在一个可控范围内。
Q:LoRA 微调的效果和全量微调相比会差很多吗?
A:在大多数“业务微调”场景下,LoRA 的效果和全量微调非常接近,甚至在小数据集上更稳定。原因是:LoRA 冻结了大部分通用能力,只在低秩空间里学习增量,能减少过拟合和灾难性遗忘。不过在需要大幅改变模型能力的任务上(比如从通用对话转向专业代码生成),全量微调可能略有优势。建议做法是:先用 LoRA 做一版快速验证,通过离线指标和小规模在线实验评估效果,如果差距明显,再考虑更重的方案。
Q:QLoRA 和 LoRA 相比,什么时候值得上?
A:当你的显存已经成为主要瓶颈,或者希望在单机上玩转更大模型时,就很值得考虑 QLoRA。QLoRA 在 LoRA 的基础上,对基座模型做了更激进的量化,显著降低显存占用,但可能带来轻微的精度损失。判断标准可以是:如果你当前因为显存限制被迫使用较小模型,而业务又明显受限于模型能力,那用 QLoRA 压缩大模型、再做微调,往往是更划算的选择。实施时要注意:务必对关键业务指标做充分评估,确认量化带来的损失在可接受范围内。
Q:一个用户能同时挂多组 LoRA 吗,比如既有行业 LoRA 又有公司私有 LoRA?
A:技术上可以叠加多组 LoRA,但需要小心冲突和不可预期行为。原因在于:不同 LoRA 都在对同一基座模型做“增量修改”,叠加后等价于多次对权重做偏移,可能放大某些偏差或互相抵消。可操作建议是:优先考虑分层设计(如行业基座模型 + 公司级 LoRA + 部门级 LoRA),并在每一层做独立评估;如果必须叠加多组 LoRA,建议在灰度环境中做充分 A/B 测试,并为关键场景保留回退到单一 LoRA 或纯基座模型的能力。
Q:从零开始搭一套 LoRA 微调服务,大概要注意哪些工程点?
A:核心有三块:模型管理、推理路由和成本监控。模型管理上,要区分“基座模型版本”和“LoRA 版本”,并为每个租户维护清晰的版本关系;推理路由上,需要设计好“请求如何找到对应 LoRA、LoRA 如何缓存和淘汰”的策略,避免频繁加载导致延迟抖动;成本监控上,要能拆分出“基座模型成本”和“各租户 LoRA 使用成本”,这样才能设计合理的计费和内部结算。实践中,建议先在一个小业务线试点,把这三块打通,再逐步推广到更多团队。