
当我们与AI进行长时间聊天时,常会发现AI的回答变得粗糙,甚至忘记了最初设定的内容。比如让AI阅读大量PDF时,后半部分的信息往往被优先处理,而前半部分的重要条件却被忽略了。
笔者曾经经常让AI创作短篇小说,先设定角色和场景,写好开头后让AI续写故事。

然而,早期的AI在这方面表现并不理想。角色的名字、性别、年龄和属性经常混乱,甚至会突然出现陌生人物,严重时故事结构会崩溃。
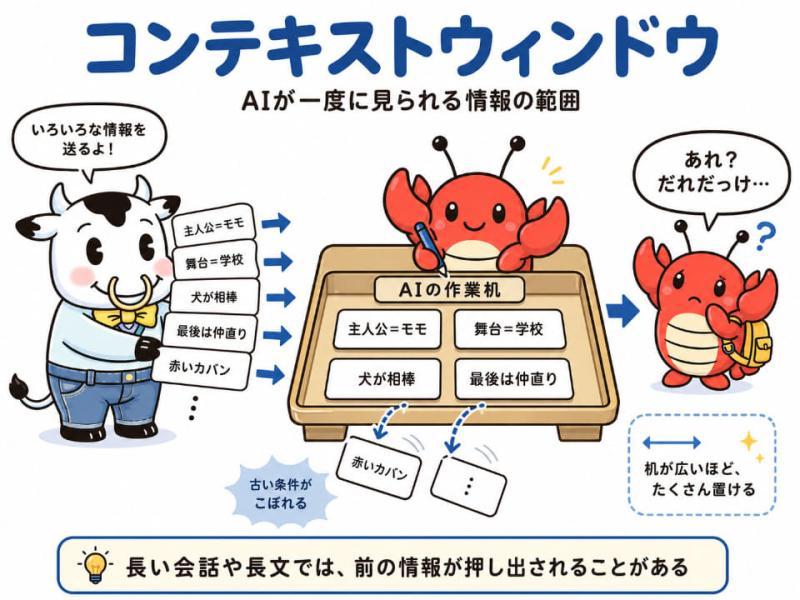
这并非AI不认真,而是因为AI一次能处理的信息量有限,也就是所谓的“上下文窗口”有限。
上下文窗口指的是AI一次能够参考的信息范围。可以把它比作AI工作的桌面大小。桌面越大,能同时放置的资料越多,AI就能同时处理更多信息;桌面太小,旧资料就会被挤到一边,难以查看。
这个“桌面大小”用“Token”(令牌)来衡量。Token是AI处理文本时的最小单位,在日语中相当于字符或词语的一部分。
图像生成中也会出现“遗忘”问题
这种问题不仅出现在文本处理中。
笔者用AI生成本系列文章的插图时,反复要求“保持第一张角色形象,换个构图”,结果牛君的皮带、领带,龙虾君的包包等细节会逐渐消失。
这同样是因为AI无法始终完美保持最初的指令和图像特征。除了上下文窗口限制外,还有“注意力分散”的因素。随着对话变长,重要条件会被推到桌面角落,难以被AI关注。
上下文窗口对RAG技术也至关重要
在第8回中介绍的RAG(检索增强生成)技术中,曾提到让AI参考公司内部手册。
有人可能会想,为什么不直接把所有手册内容贴到聊天框里?但上下文窗口的限制使得一次性输入所有资料并不能保证AI能正确参考全部内容。
因此,RAG通过检索需要的部分,动态传递给AI,避免超出上下文窗口限制。
这说明上下文窗口不仅决定AI能记住多少信息,也影响RAG和长文本处理的设计。
上下文窗口容量正在快速扩大
近年来,上下文窗口容量大幅提升,从几千Token扩展到几十万,甚至有AI能处理百万级Token。
这将极大改变AI的应用方式。
例如,AI可以一次性处理长合同、厚重的规格书、大量会议记录、完整源代码,甚至长时间的音频和视频内容。
用户可以让AI分析会议录音,询问“25分钟时A先生说的话与后半部分结论是否矛盾”,或者在保持小说设定的情况下续写故事,这些都变得现实可行。
不过,上下文窗口扩大并非万能。即使能输入大量信息,AI也不一定能完全理解所有内容,或准确抓住关键点。桌面变大了,找到真正需要的资料仍然需要其他能力。
上下文窗口更像是AI的“工作桌面大小”,容量越大能处理的信息越多,但如何整理信息和下达指令同样重要。
因此,当让AI处理长文档或复杂对话时,不仅要考虑能放多少信息,更要明确告诉AI“优先关注哪些内容”。


