99% 的团队在接入 AI 工具时,都低估了“集成”这件事有多折磨人。你以为只是多写几个接口,结果写着写着,代码像蜘蛛网一样缠住了自己。等到要换模型、加工具、上新平台,才发现每一步都在拆雷。MCP 的诞生,就是为了把这场长期的技术债清算掉。
AI 应用越多,这个问题越明显。一个朋友做内部 AI 助手,本来只想接三个常用工具,结果光是对接不同模型和平台,就写了十几个适配层。代码能跑,但没人敢动,谁改谁背锅。说实话,这种“能用就行”的集成方式,在短期看省事,长期看就是在给自己挖坑。
有用户反馈,他们在一年内更换了两次大模型供应商,每次迁移都要重写大部分工具集成代码,迁移周期平均拉长到 3 个月以上。
问题所在
M×N 集成的隐形成本
在 MCP 出现之前,把 AI 和外部数据、操作连起来,基本都是一堆零散的单独方案。每个团队自己搞一套:有的直接在代码里硬编码每个工具的调用逻辑,有的用一长串提示词链来“糊”出一个流程,还有的被迫绑定在某个厂商的插件框架上。看起来各有各的聪明做法,结果却共同掉进了同一个坑:M×N 集成。
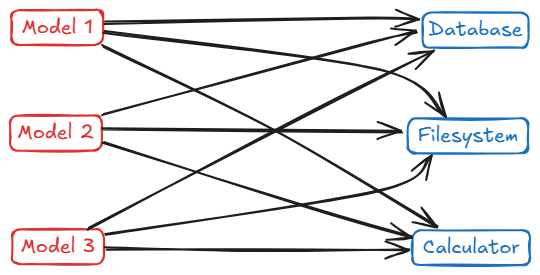
一旦你有 M 个不同的 AI 应用,再加上 N 个不同的工具或数据源,理论上就要维护 M×N 个定制集成。比如 3 个 AI 应用配 3 个工具,就可能要写 9 套适配逻辑。数据显示,有团队在扩展到 6 个内部系统和 4 个模型后,相关集成代码超过 2 万行,任何一次升级都像拆炸弹。代码量不是唯一问题,认知负担、测试成本、回归风险,全都在指数级上涨。
更麻烦的是,这些集成往往风格各异。不同开发者写的接口规范不统一,错误处理方式也不一样,连日志格式都各说各话。等到要排查问题时,你会发现自己像在读六七种方言,还没有翻译器。
工具提供方的多重负担
从工具提供商的角度看,这种局面同样是一场灾难。AI 应用的开发者每次都在“重新发明轮子”,而工具方则被迫适配一堆不兼容的 API。一个数据库服务,可能要同时支持某云厂商的插件协议、某大模型平台的扩展接口、再加上几家企业自定义的 Webhook 规范。
有厂商反馈,他们为了适配不同 AI 平台,维护了 5 套以上的 SDK 和插件版本,每次平台升级都要跟着改,测试矩阵直接爆炸。长期下来,工具方的产品路线被拖慢,创新资源被消耗在“追平台节奏”上。说白了,大家都在为缺乏标准付出隐形税。
这种状态下,任何一个平台的协议变化,都可能让一整条集成链断掉,风险被放大到业务层面,而不仅仅是技术问题。
复杂拓扑带来的脆弱性
如果把这些集成关系画成图,你会看到一张密密麻麻的网:每个 AI 模型节点都要连向每个外部服务节点。数据库、文件系统、搜索引擎、计算器、内部业务系统……每多一个,就多出一圈连线。拓扑结构越复杂,系统就越脆弱。
一位企业架构师跟我说,他们内部画过一次“AI 调用外部系统关系图”,打印出来铺满了一整面白板。任何一个节点的变更,都可能牵动十几个调用路径。更糟的是,这些路径很多是“历史遗留”,没人能完整说清楚为什么当初这么设计。我也不太确定这是不是所有大公司都会经历的阶段,但从我看到的案例看,挺常见。
解决方案
MCP:把 M×N 变成 M+N
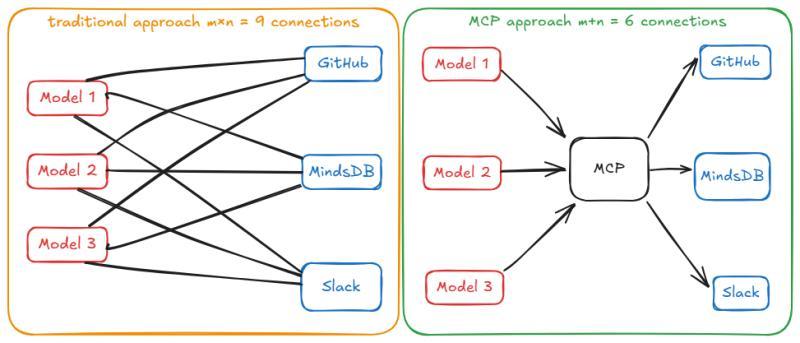
MCP 的核心思路,其实很朴素:引入一个中间的标准接口层。原本是每个 AI 应用直接对接每个工具,形成 M×N 的关系;有了 MCP 之后,变成每个 AI 应用只需要实现一次 MCP 客户端,每个工具只需要实现一次 MCP 服务器。数学上从 M×N 变成 M+N,架构上则是从“乱线”变成“总线”。
现在,所有参与方都说同一种“语言”。AI 应用不再关心某个具体工具的私有 API,只要会说 MCP 协议,就能调用任何遵守 MCP 的工具。工具提供方也不必为每个 AI 平台写一套适配,只要实现 MCP 服务器,就能被所有 MCP 客户端理解。这种解耦方式,在传统软件工程里早就被验证有效,只是很多人没把它认真搬到 AI 工具集成领域。
据一些早期采用者反馈,引入 MCP 后,新接入一个工具的时间从几周缩短到几天,甚至在已有 MCP 生态下可以压缩到数小时。
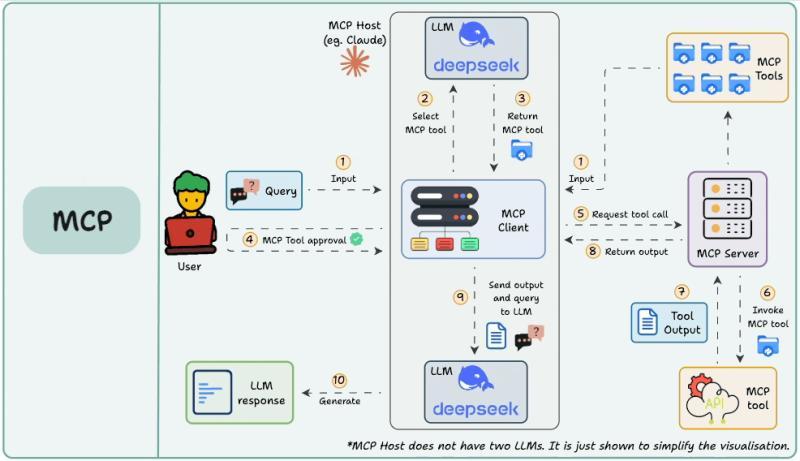
从“点对点”到“通过翻译器”
可以把 MCP 想象成一个通用翻译器。左侧是各种模型、AI 应用,右侧是各种工具和数据源。过去是每一对说不同语言的人,都要配一个专属翻译;现在变成所有人都学会和同一个翻译器对话。新来一个人,只要会和翻译器沟通,就能和所有人交流。
在 MCP 之前:
- 每个模型都必须直接连接到每个工具,写专用适配代码。
- 工具升级或接口变动时,要逐个通知所有集成方。
- 新增一个模型或工具,都会引发一轮“全线改造”。
有了 MCP 之后:
- 每个模型和工具都只需要对接 MCP 层。
- 协议稳定后,内部实现可以自由演进,对外接口保持一致。
- 新的模型或工具加入生态,只要遵守 MCP,就能即插即用。
你也可以把它类比成 USB 标准出现前后的差别:以前每个设备一个口,线缆堆满抽屉;有了统一接口,电脑只要提供几个标准插口,绝大多数设备都能直接用。
现实中的收益与风险
从实践看,MCP 带来的收益不只是“看起来更优雅”。有团队统计,在采用 MCP 之后,新工具接入时间平均缩短了 60% 以上,回归测试用例数量也明显下降,因为测试重点从“每一对组合”转向“协议是否正确实现”。开发者的心智负担减轻了,文档也更容易维护。
不过,也不能把 MCP 神化。任何标准都会有演进成本,一旦协议设计不合理,可能会在未来暴露出新的限制。还有一个现实问题:在生态尚未完全成熟时,你可能会遇到“想用的工具还没支持 MCP”的尴尬,需要自己写一层过渡适配。这些都是需要提前预期的风险。
我自己的体验是,只要项目规模超过两三个 AI 应用、三四个外部系统,MCP 这种标准化层就开始显出价值。小项目可能感觉不到差异,但一旦进入“要长期维护”的阶段,这种架构上的简化,会在每一次迭代中持续省下时间和精力。
为什么这套方法值得记住
如果你正在规划 AI 能力在公司内部的落地路径,MCP 提供的是一种可复用的判断标准:
- 当你发现集成关系图开始变得难以一眼看清,就该考虑引入统一协议层。
- 当工具方抱怨“适配太多平台太累”,说明标准化的时机到了。
- 当你频繁更换模型供应商,却每次都要大改代码,MCP 这种解耦思路会非常有用。
这个判断方法在不少团队里被反复验证有效,适合收藏下来,当作你做架构决策时的一把“提前预警”的尺子。如果你正准备上马一个新的 AI 项目,这些经验往往比问身边人“用哪个模型好”更关键。
常见问题
Q:小团队项目也有必要上 MCP 吗?
A:小团队如果只做一次性 Demo,确实可以先不用 MCP,但只要你预期项目会长期维护或扩展,越早引入统一协议越省事。原因在于,M×N 的复杂度一旦形成,就很难在后期“无痛重构”,往往要推倒重来。建议做一个简单判断:如果你计划接入超过 3 个外部工具,或者未来可能更换模型供应商,就可以把 MCP 纳入设计,哪怕一开始只用到一小部分能力。
Q:MCP 会不会限制我使用某些高级工具特性?
A:短期内有可能遇到这种情况,因为标准协议往往优先覆盖通用能力,对一些极其定制化的高级特性支持不一定那么快。原因是 MCP 需要在“通用性”和“特性完备”之间做平衡,过度追求覆盖所有细节,反而会让协议变得臃肿。可行的做法是:对核心能力通过 MCP 统一接入,对极少数特殊能力保留旁路直连接口,并在文档中明确标注,避免混淆调用路径。
Q:已经有一堆历史集成代码了,还能平滑迁移到 MCP 吗?
A:可以迁,但不会完全“无感”,需要有计划地分阶段替换。原因在于,历史集成往往深度耦合在业务逻辑里,直接整体切换风险很大。建议的做法是:先选一两个相对独立的工具,围绕它们实现 MCP 服务器,再让一个新或非关键的 AI 应用接入 MCP 客户端,通过这条新链路验证协议和流程。稳定后,再逐步把其他工具和应用迁到 MCP 上,同时保留一段时间的双轨运行,确保业务不中断。
Q:如果未来出现比 MCP 更好的标准怎么办?
A:任何技术标准都有被替代的可能,这点不需要回避。关键在于,MCP 本身就是一种“解耦层”,它把业务逻辑和底层实现隔开了,这反而让你未来切换到新标准更容易。原因是,你只需要在 MCP 层和新标准之间建立一个桥接适配,而不是重写所有 AI 应用和工具的集成代码。建议在设计时就把 MCP 层实现得足够清晰、模块化,为未来可能的“标准迁移”预留一个缓冲带。
Q:MCP 会不会增加系统的延迟和复杂度?
A:从调用链上看,引入 MCP 确实多了一层转发,理论上会带来一点点额外延迟,但在大多数业务场景下,这个开销远小于它带来的维护收益。原因在于,MCP 主要增加的是“结构复杂度”的可控性,而不是“运行复杂度”的失控。可操作建议是:在性能敏感路径上做基准测试,确认 MCP 带来的延迟是否在可接受范围内;同时通过连接池、并发调用、缓存等手段优化实现,避免把协议层的好处浪费在糟糕的工程实践上。