Stability AI,这家开发了Stable Diffusion的公司,近日推出了一系列新的音频模型,名为Stability Audio 3.0。公司声称其顶级模型能够生成超过六分钟的专业级音乐作品。
此次发布的Stable Audio 3.0系列包含四款模型:小型音效模型(459M参数)、小型模型(459M参数)、中型模型(14亿参数)和大型模型(27亿参数)。其中两款小型模型适合在设备端生成最长两分钟的声音和音乐。
中型和大型模型则能够创作时长达6分20秒的完整音乐作品,且能保持良好的音乐结构和旋律调性。这一时长是2024年发布的Stable Audio 2.0模型生成能力的两倍多。
Stability AI将小型音效、小型和中型模型以开放权重的形式发布,供任何人使用和修改。2024年,该公司曾推出Stable Audio Open,支持最长47秒的音乐生成。此次新模型家族相比之前的开放版本有了显著提升。
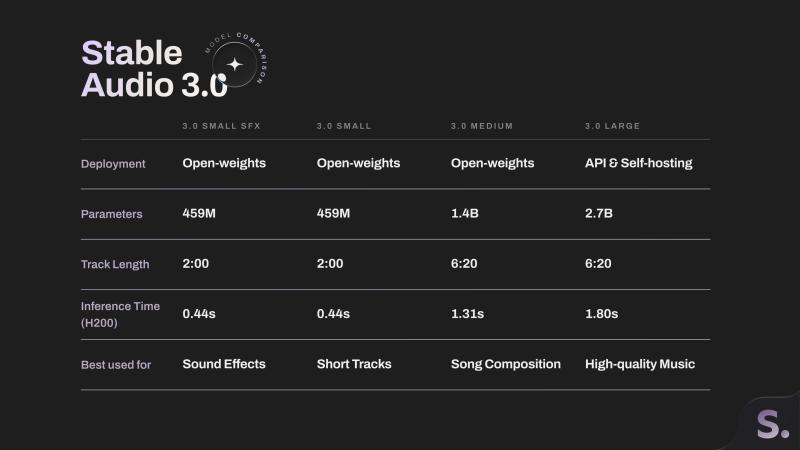

大型模型仅通过API和付费自托管服务提供,且年收入超过100万美元的企业需获得企业许可。
目前,包括谷歌和ElevenLabs在内的多家公司也在发布音乐生成相关的模型和工具。然而,正如Suno和Udio的法律纠纷所显示,数据授权和与音乐厂牌的合作可能成为这些服务长期发展的关键。
去年,Stability AI与华纳音乐集团和环球音乐集团签署合作协议,共同开发模型和音乐创作工具。公司表示,最新的音频模型基于完全授权的数据构建。
此外,该AI初创公司正开发一套面向专业音乐人的新产品,具体功能尚未公布。前Universal Audio和Fender数字主管Ethan Kaplan将加盟Stability,负责领导其专业音乐业务。
多家AI公司正通过聘请音乐行业高管来提升自身实力。今年早些时候,Suno聘请了前Merlin CEO Jeremy Sirota担任首席商务官,ElevenLabs也聘请了来自独立音乐出版商Kobalt的Derek Cournoyer担任音乐业务战略负责人。