OpenAI近日在其Realtime API中引入了三款全新的音频模型,旨在帮助开发者构建更加自然、智能且能够实时响应的语音交互体验。
这三款模型分别是“GPT-Realtime-2”、“GPT-Realtime-Translate”和“GPT-Realtime-Whisper”。其中,GPT-Realtime-2的定价为每100万个语音输入令牌32美元(缓存输入令牌0.40美元),语音输出令牌每100万个64美元;GPT-Realtime-Translate按每分钟0.034美元计费;GPT-Realtime-Whisper则为每分钟0.017美元。
-
GPT-Realtime-2 这是首个具备GPT-5级推理能力的音频模型,能够满足更高阶的需求,实现自然流畅的对话。
-
GPT-Realtime-Translate 支持70多种输入语言向13种输出语言的实时语音翻译,能够根据说话者的语速进行同步翻译。
-
GPT-Realtime-Whisper 采用全新流式语音识别技术,能够在说话过程中实时将语音转写为文字。
这些模型的推出,使得实时语音交互从简单的呼叫与响应,进化为能够根据对话进展进行听取、推理、翻译、转写并执行操作的功能性语音接口。
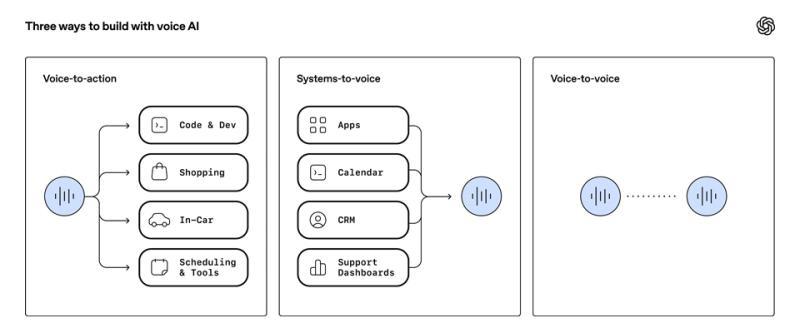
随着语音成为使用软件的更自然方式,开发者正围绕三大新模式构建语音AI:
-
语音到行动(Voice-to-action) 用户表达需求后,系统能推理并利用工具完成任务。例如,美国Zillow开发的助手能理解“帮我找符合预算、避开拥堵路段的房子,并预约周六看房”的请求,并执行相应操作。
-
系统到语音(Systems-to-voice) 软件根据情境实时提供语音指导。比如旅游应用能主动告知旅客“您的航班延误,但转机仍可顺利进行,已为您标注新登机口及最短路径,行李转运无忧”。
-
语音到语音(Voice-to-voice) AI支持跨语言、跨任务的实时对话延续。德国电信正构建一套语音支持体验,允许客户使用最熟悉的语言交流,模型实时翻译对话内容。
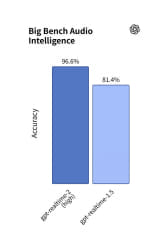
在接近真实语音代理的评测中,GPT-Realtime-2(高性能版)在评估逻辑推理和智能的“Big Bench Audio”测试中,比GPT-Realtime-1.5高出15.2%。而GPT-Realtime-2(超高性能版)在“Audio MultiChallenge”音频对话AI能力测试中,得分比GPT-Realtime-1.5高出13.8%,显示其在推理、上下文管理和控制能力上有显著提升。