产品详细介绍
Ocular AI 是一款专为多模态 AI 场景打造的数据基础设施平台(Data Foundry),面向需要处理海量文本、图像、视频、音频等非结构化数据的团队和企业。它将数据集中管理、协同标注、模型训练与评估整合在同一平台中,帮助你从原始数据快速构建高质量“黄金数据集”,并在此基础上打造和对齐自定义 AI 模型。
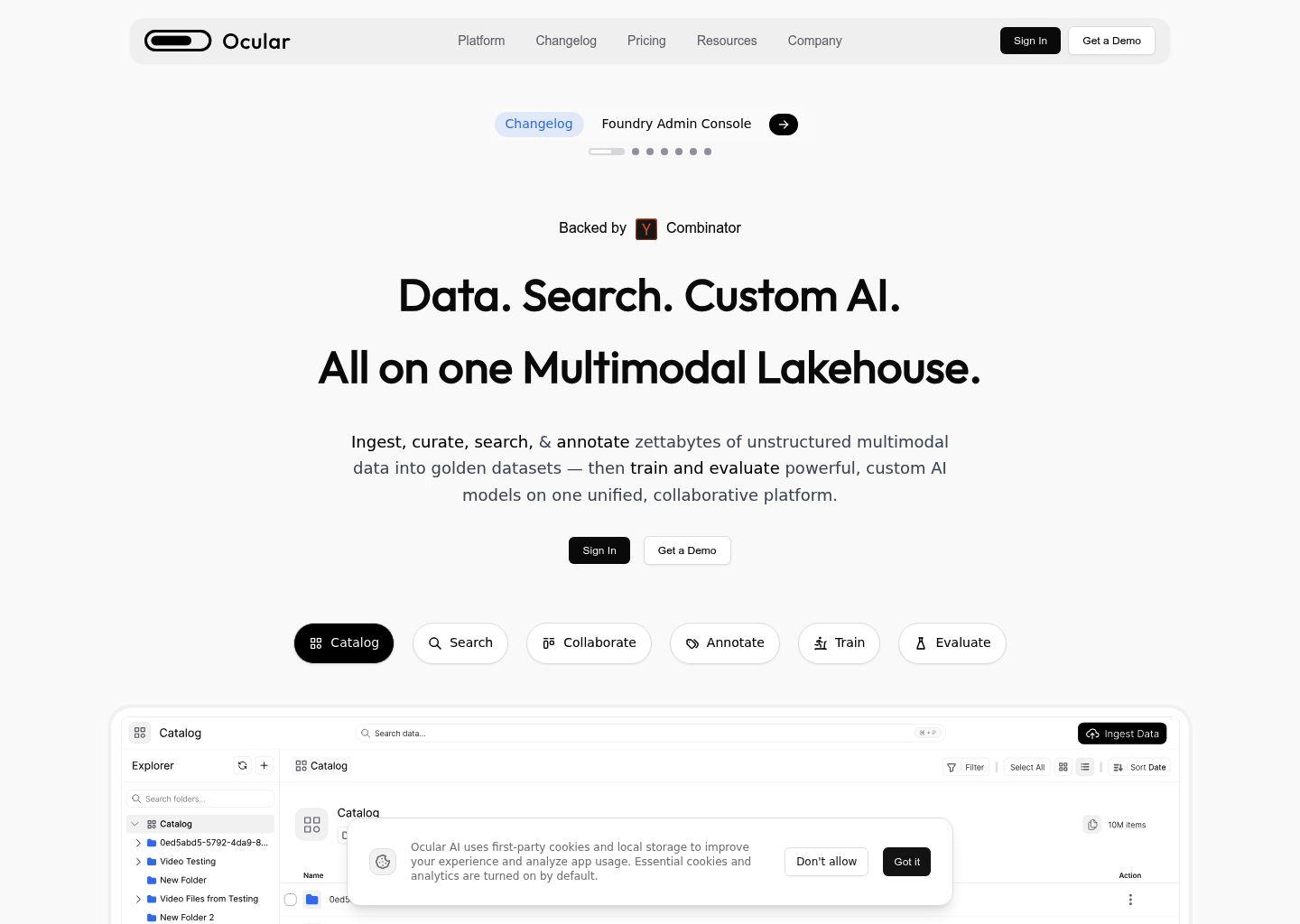
1. 多源多模态数据集中管理
- 支持从各类云端与本地数据源统一接入,打破数据孤岛,将分散在不同系统和存储中的多模态数据集中到一个工作空间中。
- 针对文本、图片、视频、音频等多种数据类型提供统一的可视化浏览与组织能力,便于团队协同查看和管理。
- 数据集中后可进行灵活的分组、筛选、版本管理,为后续标注、训练和评估提供稳定的数据基座。
2. 自然语言多模态搜索与探索
- 支持使用自然语言在视频、图像和音频中进行搜索,无需提前人工打标签。
- 可以快速定位特定物体、场景、对话片段或关键时刻,大幅降低数据筛选和样本发现的成本。
- 搜索结果会自动更新,便于在持续增长的数据集上进行迭代探索。
3. 高效可扩展的数据标注与管理
- 通过 Ocular Foundry 和 Ocular Bolt,将 AI 标注代理与人工审核(Humans-in-the-loop)结合,实现大规模高质量标注。
- 支持灵活配置标注工作流,适配简单分类到复杂多模态任务(如视频中目标检测、场景理解、对话标注等)。
- 内置项目管理与数据集分析功能,可实时跟踪标注进度、质量指标和版本变化,确保数据集可追溯、可复现。
- 支持对数据集进行版本化管理,方便在不同实验和模型迭代中对比数据差异和效果变化。
4. 专家级 RLHF 与专业领域标注
- 提供 RLHF(基于人类反馈的强化学习)能力,可对多模态模型进行对齐和质量提升。
- 可接入来自医生、工程师、法律专家等专业人士的标注与评估,适用于医疗、工业、法律等对专业知识要求极高的场景。
- 通过专家反馈对模型输出进行细致评估和打分,帮助构建更可靠、更符合业务需求的模型行为。
5. 训练、评估与模型对比一体化
- 支持在数据所在环境中直接训练模型,利用托管 GPU 集群和可扩展训练流水线,避免大规模数据迁移带来的成本与风险。
- 可在交互式“模型游乐场”中对模型进行测试和对比,使用自己的数据验证模型性能。
- 支持多模型对比评估,帮助团队快速选择最适合业务场景的模型方案,并持续迭代优化。
6. 企业级安全与合规集成
- 与现有技术栈深度集成,可无缝嵌入现有数据管道和业务流程。
- 即便连接外部数据源,数据仍保留在企业现有基础设施和存储中,降低合规与安全风险。
- 采用企业级安全架构与防护措施,系统持续监控与审计,确保数据隐私与访问控制符合企业与行业标准。
综合来看,Ocular AI 既是多模态数据的“集中仓库”,也是从数据到模型的“生产线”,适合需要在复杂多模态数据上构建高质量 AI 能力的团队和企业使用。
简单使用教程
以下是基于典型工作流的简要上手步骤,帮助你快速理解如何用 Ocular AI 从数据走到模型:
步骤一:接入与集中你的多模态数据
- 注册并登录 Ocular AI 平台。
- 在数据源管理界面,连接你的云存储(如对象存储、数据湖等)和本地数据源。
- 选择需要纳入管理的文本、图片、视频、音频等数据集,配置同步策略(一次性导入或持续同步)。
- 完成后,你可以在统一的工作空间中浏览和组织所有多模态数据。
步骤二:探索与筛选数据样本
- 在数据浏览界面,使用自然语言搜索功能,例如输入“夜间城市街道行人”或“医生与病人对话片段”。
- 根据搜索结果快速定位目标样本,进行筛选、收藏或加入特定数据集。
- 对于视频和音频,可直接跳转到包含关键物体、场景或对话的时间片段,减少人工逐帧查看的工作量。
步骤三:创建标注项目与工作流
- 新建标注项目,选择目标数据集和任务类型(如分类、检测、分割、多模态问答等)。
- 配置标注工作流:
- 设定由 AI 代理进行预标注的规则;
- 指定人工审核或复核环节,实现人机协同(Humans-in-the-loop);
- 设置质检比例和验收标准。
- 邀请团队成员或外部专家加入项目,分配角色与权限。
- 启动项目后,可在项目管理面板中实时查看标注进度、任务分配和质量统计。
步骤四:构建高质量“黄金数据集”
- 在标注完成后,对数据集进行质量抽检和统计分析,识别潜在问题样本。
- 使用版本管理功能,为当前标注结果创建数据集版本,作为后续训练的“黄金数据集”。
- 如需迭代,可在新版本中修正标注、补充样本或引入更多专家反馈,并保留历史版本以便对比。
步骤五:在本地数据上训练自定义模型
- 在训练模块中选择目标数据集版本和模型类型(如多模态分类、检索、生成等)。
- 配置训练参数(批大小、学习率、训练轮数等),并选择使用的 GPU 集群资源。
- 启动训练任务,平台会在数据所在环境中执行训练,避免大规模数据迁移。
- 通过训练监控界面查看损失曲线、指标变化和资源使用情况,必要时中断或调整训练。
步骤六:评估、对比与 RLHF 对齐
- 将训练好的模型部署到交互式评估“游乐场”,使用你的真实业务数据进行测试。
- 对比多个模型在同一数据集上的表现,查看准确率、召回率、延迟等关键指标。
- 若需要进一步对齐模型行为,可创建 RLHF 项目:
- 让专家对模型输出进行打分、排序或修改;
- 将这些反馈用于后续的对齐训练,提升模型在特定场景下的可靠性和可控性。
- 迭代更新模型版本,并与数据集版本一同管理,形成完整的从数据到模型的可追溯链路。
通过以上流程,你可以利用 Ocular AI 将分散的多模态数据转化为结构化的高价值资产,并在此基础上高效构建、评估和对齐适合自身业务的 AI 模型。