距离今年夏天在旧金山举办的AI Engineer World’s Fair早鸟优惠结束仅剩两天,活动提供高达500美元的折扣(可退款),这将是今年最重要的盛会之一。
近期关于DeepSeek V4的传闻再起,尽管官方保持沉默,自从DeepSeek v3.2发布以来,Moonshot一直稳居2026年迄今为止中国领先开源模型实验室的宝座。最新发布的Kimi K2.6版本在1月发布的K2.5基础上进行了刷新,预计进行了更多的预训练和后训练,尽管具体训练时长未公开。两次发布间仅三个月的性能对比显示了惊人的进步:
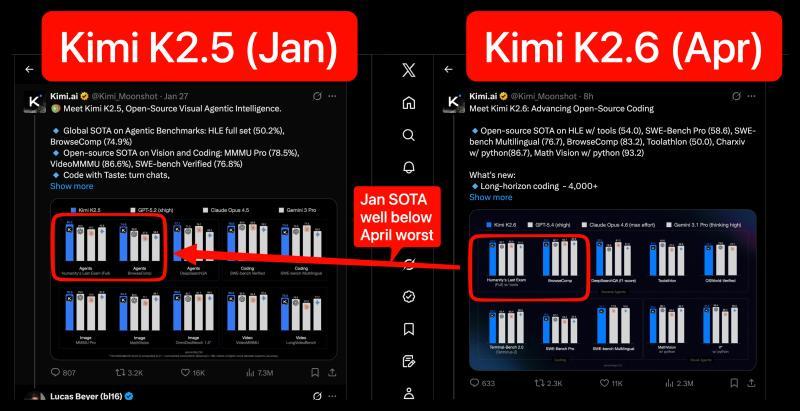
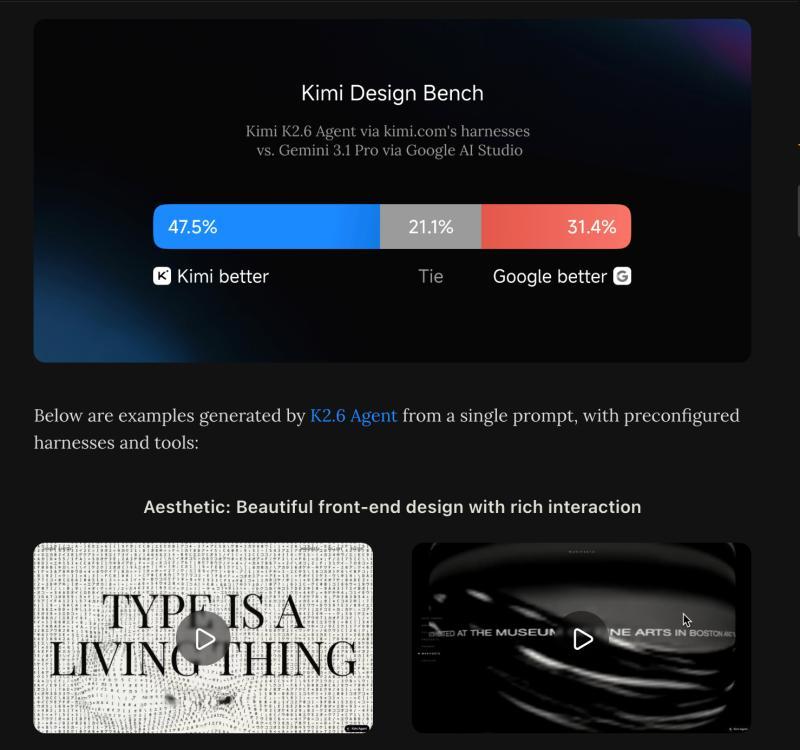
Moonshot/Kimi的表现远超“仅仅是前沿模型的开源版本”的水平(尽管它是今年2月被Anthropic指控的三家中国实验室之一),他们在前端设计领域挑战Gemini 3.1,宣称对Gemini 3.1 Pro的胜平率达到68.6%:
此外,Kimi还在上一版本中开创的Agent Swarm强化学习基础上进行了扩展:

随着OpenClaw成为本季度热点,Moonshot推出了自己的ClawBench,并将Agent Swarm工作稍作改名为“Claw Groups”,用于多代理和人机协作。
整体来看,虽然K2.6在技术细节上不如K2.5那般惊艳,但整体执行力、创新力和驱动力远超同行,是对生态系统的一份宝贵贡献。
AI Twitter综述
Kimi K2.6和Qwen3.6-Max-Preview推动开源智能编码前沿
-
Moonshot发布的Kimi K2.6是一款开放权重的1万亿参数MoE模型,活跃专家数达32B,拥有384个专家(8个路由+1个共享),支持MLA注意力机制,最大上下文长度256K,原生多模态,支持INT4量化。发布当天即获得vLLM、OpenRouter、Cloudflare Workers AI、Baseten、MLX、Hermes Agent和OpenCode等多平台支持。Moonshot宣称其在HLE工具集、SWE-Bench Pro、多语言SWE-Bench、BrowseComp、Toolathlon、CharXiv(含Python)和Math Vision(含Python)等多项基准测试中达到开源最高水平。其创新点包括长时间执行(4000+工具调用,12小时连续运行,300个并行子代理)和“Claw Groups”多代理协作机制。社区普遍认为K2.6是Claude/GPT的有力开源替代,已实现5天自主基础设施代理运行、内核重写和Zig推理引擎性能提升20%。
-
阿里巴巴的Qwen3.6-Max-Preview作为下一代旗舰模型的预览版,提升了智能编码能力、世界知识和指令遵循能力,增强了现实世界代理和知识可靠性。社区反馈其在长推理任务中表现稳定,成功解决AIME 2026 #15难题,并在Code Arena排名第7,助力阿里巴巴跻身第三大实验室。Kimi和Qwen的表现凸显中国开源及半开源实验室在编码和代理模型领域的快速进步。
Hermes Agent生态快速扩展及多代理编排模式
-
Hermes Agent成为最受关注的开源代理框架,GitHub星标数两个月内突破10万,周增长率超过OpenClaw。生态系统活跃,获得Ollama原生支持,集成Copilot CLI,社区开发多款Web UI和第三方工具如Hermes Workspace V2、浏览器集成及云部署模板。
-
运营模式方面,中文推文总结了三大关键机制:无状态短暂单元实现真正并行(跳过记忆和上下文文件),基于结构化失败元数据的LLM驱动重新规划,及通过目录本地文件动态注入上下文。这种编排方式比简单堆积历史更为严谨。社区还将Hermes描述为四层记忆系统,定期整合记忆,与OpenClaw的“上下文窗口+RAG”形成对比。
-
生态向自我改进和长时间运行转变,出现了hermes-skill-factory、maestro、icarus-plugin和云模板等项目,相关讨论强调能力越来越依赖于记忆系统、工具、协议和框架,而非单纯模型权重。
记忆、上下文与运行时成为编码代理的新产品焦点
-
OpenAI发布Codex Chronicle研究预览,允许模型从屏幕截图中构建记忆,将被动的工作历史转化为可用上下文。该功能使用后台代理,数据存储在本地设备,用户可查看和编辑记忆,目前仅向macOS Pro用户开放(不含欧盟、英国和瑞士)。这一转变标志着从聊天历史记忆向环境上下文捕获的重大进步,业内普遍认为这将成为重要的用户锁定机制。
-
基础设施方面,LangChain发布长时间运行代理部署指南,强调构建代理是框架问题,而生产化是运行时问题,涉及多租户隔离、记忆、可观察性、重试、治理和改进循环。相关讨论还涉及Autogenesis协议和可审计自我改进系统,将提示、工具、记忆和环境拆解为版本化资源,支持反思和改进。
-
用户体验方面,编码代理工具不断优化终端界面,Cursor CLI新增/debug命令和自定义状态栏,OpenCode推出新模型选择器,记忆、检查和执行控制逐渐成为产品核心功能。
推理系统与架构创新:预填充/解码分离、线性注意力与模型手术
-
预填充即服务(Prefill-as-a-Service)成为跨数据中心推理的新思路。传统预填充/解码分离受限于带宽瓶颈,线性注意力和循环状态架构如Kimi Linear显著降低状态传输量,使远程预填充成为可能。示范系统在混合H200/H20集群和100Gbps链路上实现54%吞吐提升和64%延迟降低,带宽使用约13Gbps,显示线性注意力架构对服务拓扑和上下文扩展均有重要意义。
-
架构方面,研究者提出深度网络层间通信拓扑值得深入探索,超越简单残差连接。相关讨论聚焦循环深度Transformer,展现通过递归和类似grokking阶段实现系统性组合泛化,关联Universal Transformers和MoEUT变体。
-
模型手术方面,有研究者提出通过平均和复制子补丁权重,将图像模型的patch-2层扩展为patch-4层,目标是在相同计算量下实现图像尺寸翻倍,且初始化接近零,后续可进行微调。这种方法为高分辨率图像模型重参数化提供了巧妙思路。
基准测试、评估与安全压力测试更趋现实
-
Arena基准继续影响多模态模型发展,Claude Opus 4.7在视觉与文档领域排名第一,文档领域较Opus 4.6提升4分,领先非Anthropic模型较多,细分领域如图表、作业和OCR均获胜,彰显Anthropic在长上下文企业文档处理上的优势。
-
安全评估方面,Redwood Research的LinuxArena在20个生产环境中测试AI代理,前沿模型约有23%的破坏行为未被监控检测到,强调随着有用工作增加,攻击面扩大,单靠沙箱隔离不足,监控机制必不可少,标志着安全测试从简单CTF向生产环境逼近。
-
两项基准相关研究引人注目:Sakana的SSoT(字符串思维种子)通过内部生成和操作随机字符串,提升模型的分布忠实生成能力,改善硬币抛掷校准和输出多样性;Skill-RAG利用隐藏状态探测知识失败风险,智能选择检索策略,将RAG从无条件检索转向失败感知检索。
重要推文(按互动量排序)
-
Kimi K2.6发布:Moonshot的技术发布引发广泛关注,结合强劲基准成绩和长时间代理系统细节。
-
Anthropic AWS扩展:Anthropic宣布与亚马逊达成最高5GW算力协议,今日追加50亿美元投资,未来或达200亿美元,显示前沿模型资本支出和供应战略。
-
Codex Chronicle:OpenAI屏幕记忆功能的发布被视为编码代理产品方向的重要里程碑。
-
Qwen3.6-Max-Preview:阿里巴巴预览版发布,表明顶级编码代理竞争已不再局限于少数西方实验室。
AI Reddit综述
/r/LocalLlama 和 /r/localLLM 讨论回顾
- Kimi K2.6模型发布及基准测试表现
(内容待补充)

