99%的人一听到「架构」,脑子里都是复杂的框图和晦涩名词,但MCP的核心结构其实比你想象的简单。它延续了大家早就熟悉的客户端-服务器模式,只是把角色重新命名,专门为AI助手这种新物种做了优化。理解这套关系,能帮你判断:到底是模型在“思考”,还是外部工具在“干活”。
MCP整体架构:一套老思路的新用法
三个角色的基本分工
MCP的核心依然是客户端-服务器架构,只是针对AI场景换了说法:Host(主机)、Client(客户端)和 Server(服务器)。Host是用户真正接触到的那一层,Client是协议适配器,Server则是功能和数据的提供者。可以把它想象成一次网购:你是用户,App是Host,下单逻辑是Client,仓库和物流就是Server。结构并不神秘,关键在于谁负责和谁说话。
据一些开发团队的实践反馈,用这套三层角色拆分后,接入一个新工具的时间可以从几天缩短到几小时,因为每一层的职责都被写死在协议里了。听上去有点抽象,但一旦你把它和自己常用的AI应用对上号,就会发现逻辑非常直观。
为什么要重新命名角色
很多人会疑惑:既然是客户端-服务器,为什么不直接叫 Client 和 Server?原因在于AI应用多了一层「面向用户的智能界面」,这层在传统网络协议里并不突出。MCP用 Host 来强调:这里既有模型,又有对话界面,还可能有插件系统。Client则被收缩成一个更纯粹的通信组件,专门负责和 MCP Server 对接。
有用户反馈,在没有区分 Host 和 Client 的项目里,调试问题时经常搞不清是界面逻辑错了,还是协议调用出问题,排查一次要花半天。
MCP的命名虽然看似多此一举,却让调试边界变得清晰很多。说实话,我也不太确定这个命名是不是最完美的,但在多人协作和大型项目里,它确实减少了沟通成本。
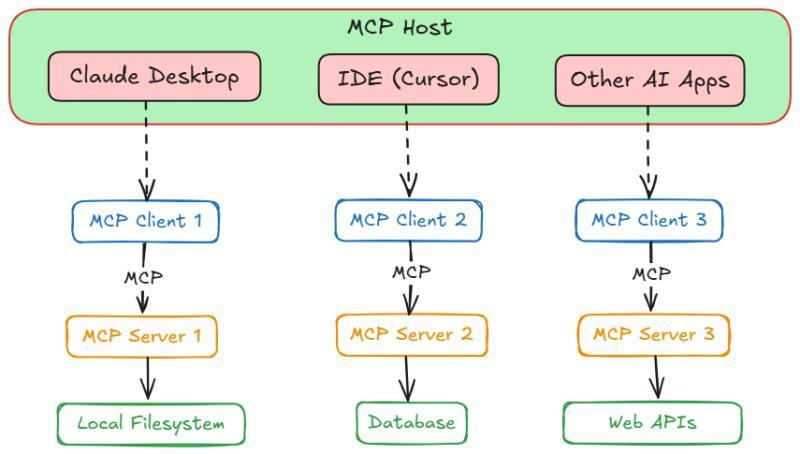
MCP架构带来的几个直接好处
从开发和使用角度看,这种架构至少带来三类好处:
- 模型和工具解耦:可以在不改动Server的情况下更换Host或模型。
- 部署更灵活:Server既可以本地跑,也可以放在云端,Client只要按协议说话就行。
- 能力可发现:Server以标准格式发布自己能做什么,Client可以自动查询和理解。
有团队在一次内部评估中统计过,迁移到MCP后,接入第三方数据源的代码量减少了约40%。当然,前提是你愿意先理解这三个角色的边界,而不是一股脑把逻辑都塞进Host里。
Host(主机):用户看到的一切
Host是什么:AI应用的“外壳”
Host是面向用户的AI应用,是模型所在并与用户直接交互的环境。你每天打开的聊天界面,比如OpenAI的ChatGPT网页、Anthropic的Claude桌面应用,都是典型的Host。再比如AI增强的集成开发环境(如 Cursor),或者嵌入AI助手的自定义应用(如 Chainlit 搭建的前端),也都扮演Host的角色。
Host负责捕获用户输入、维护对话历史、展示模型回复,还要在需要时发起与可用 MCP Server 的连接。简单说:用户所有“看得见摸得着”的体验,都归Host管。它不一定亲自干活,但一定负责“接待”和“协调”。
Host在MCP中的关键职责
Host的一个重要任务,是在合适的时机决定:要不要调用某个 MCP Server。比如用户问“帮我查一下这份合同里有没有自动续费条款”,Host里的模型可能判断:需要调用一个文档分析Server。于是Host通过内部的Client组件发起请求,再把结果整理成自然语言回复给用户。
我曾经在一个项目里,把太多逻辑塞进Host,结果每次改动一个Server能力,前端界面也要跟着大改,体验非常糟糕。后来按MCP的思路,把Host只保留成“决策+展示”层,开发节奏一下子轻松了很多。这种分层带来的好处,只有踩过坑的人才会有切身感受。
Client(客户端):协议层的“翻译官”
Client的角色:适配器和信使
MCP Client是Host内部的一个组件,专门负责与 MCP Server 进行底层通信。可以把Client看作适配器或信使:Host决定要做什么,而Client知道如何用 MCP 协议把这些意图翻译成标准请求,发给对应的Server。
在实现上,Client通常会处理连接建立、请求格式化、响应解析、错误重试等细节。Host不需要关心这些“底层脏活”,只要告诉Client:“我要用某个工具,参数是这些”,剩下的交给Client搞定。这样一来,Host可以专注在用户体验和对话逻辑上。
有开发者形容Client是“你和Server之间那个永远不会嫌你问题多的中间人”,因为它负责把各种零散的调用规范化。
Client存在的价值与潜在问题
Client的价值,在于把协议细节从Host里抽离出来,让不同Host可以复用同一套Client实现。数据显示,在一个多应用共享同一组Server的团队里,引入统一的MCP Client后,维护协议相关Bug的工时下降了约30%。
不过,这一层也有风险:如果Client设计过于复杂,调试时可能出现“Host没错、Server没错,但Client中间处理错了”的尴尬情况。为了降低这种风险,很多团队会:
- 保持Client逻辑尽量薄,只做协议相关的事情
- 为Client单独写集成测试,模拟各种Server响应
- 在日志里清晰标注Host、Client、Server各自的调用链
这种做法虽然多花一点时间,但在系统规模变大时,会让你少掉很多“到底是哪一层出问题”的无效排查。
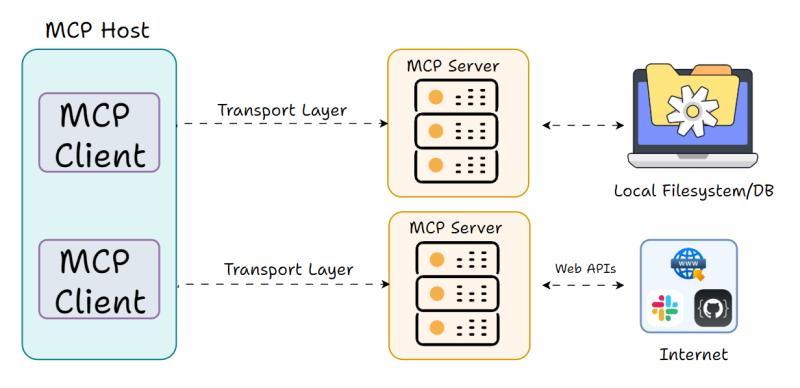
Server(服务器):功能和数据的真正来源
Server是什么:能力的封装器
MCP Server是实际为应用提供功能(工具、数据等)的外部程序或服务。它可以被视为某些功能的封装器,以标准化方式暴露一组操作或资源,让任何符合MCP协议的Client都能调用它们。
这些功能可能是数据库查询、文件系统访问、第三方API调用,或者企业内部的业务系统。Server不关心用户界面长什么样,也不关心模型怎么组织对话,它只负责:接收请求、执行操作、返回结果。换句话说,Server是“干活的那一方”。
部署方式与能力发布
MCP Server可以在与Host相同的本地机器上运行,也可以远程部署在云服务上。MCP的设计目标之一,就是让这两种场景之间的切换尽量无感:对Client来说,只是连接地址不同,协议和调用方式保持一致。
关键点在于,Server需要以标准格式发布其能力,让Client可以查询和理解有哪些可用工具、每个工具需要哪些参数、会返回什么类型的结果。有用户反馈,在接入多个Server的场景里,这种“自描述能力”极大减少了文档对照和人工对接的时间。
当然,Server层也有隐患:一旦权限控制做得不严,模型可能通过Server访问到不该看的数据。尤其在近期频繁爆出的数据泄露事件背景下,给Server加上严格的认证、审计和限流,已经不再是“可选项”,而是上线前的必做项。
小结与实践启发
如果把MCP看成一座城市,Host是面向市民的服务大厅,Client是跑腿的办事员,Server是真正办事的各个职能部门。搞清楚谁负责接待、谁负责传话、谁负责执行,你在设计AI应用时就不会乱套。
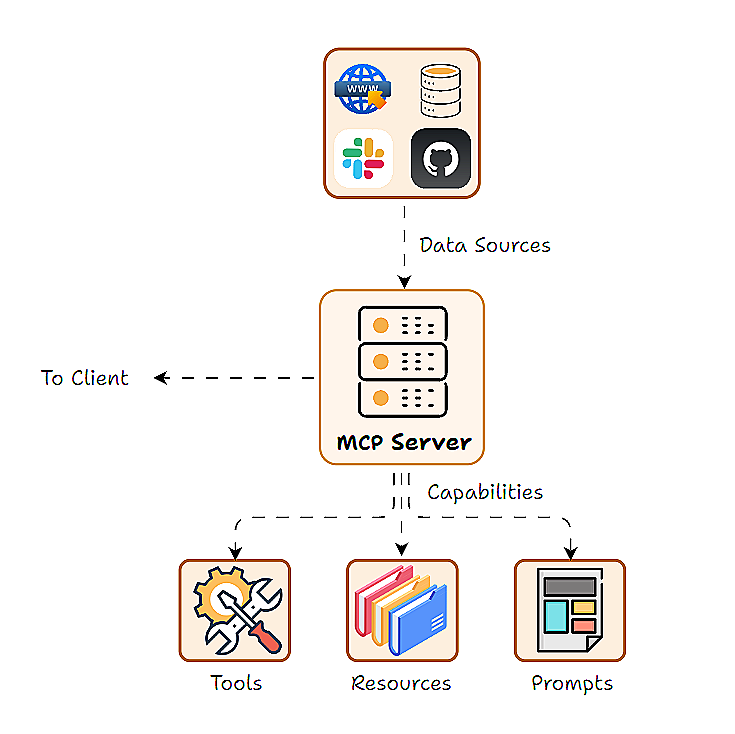
这个分层思路在不少团队里被反复验证有效,尤其适合需要接入多种工具和数据源的复杂应用。遇到类似架构选择时,不妨把这套角色划分拿出来对照一下,往往比随口问身边人“你们都怎么做的”更有参考价值。
常见问题
Q:MCP里的Host和传统意义上的客户端有什么区别?
A:简单说,Host不只是“客户端界面”,还包含了AI模型和对话管理逻辑。传统客户端更多是展示和输入输出,而MCP里的Host会参与决策:什么时候调用哪个Server、如何组织上下文、如何把结果转成自然语言回复。判断时可以看两点:一是它是否直接面向用户交互,二是是否负责调度模型和工具。如果这两点都满足,它更接近MCP里的Host,而不是单纯的UI层。设计时建议把协议细节下沉到Client组件,避免Host过于臃肿。
Q:一个应用里可以有多个MCP Server吗?
A:可以,而且这是MCP非常常见的用法。很多实际项目会为不同能力拆分多个Server,比如一个负责数据库查询,一个负责文件系统操作,另一个对接第三方API。这样做的依据是“按领域或职责拆分”,有利于独立部署和权限控制。落地时建议:为每个Server定义清晰的能力边界和访问策略,在Client层统一做路由和错误处理,避免Host直接感知过多Server细节。
Q:MCP Server放在本地和放在云端有什么取舍?
A:本地部署的优势是延迟低、数据可控,适合对隐私和安全要求高的场景;云端部署则更易扩展和运维,适合需要弹性伸缩、访问频繁的服务。判断时可以从三点考虑:数据敏感度、访问频率和团队运维能力。如果数据高度敏感且团队有本地运维能力,可以优先本地;如果更看重弹性和全球访问速度,云端会更合适。无论哪种方式,都要在Server层加上认证和审计,防止模型“越权访问”。
Q:Client和Host能不能合并成一个组件来实现?
A:技术上可以合并,但不太推荐这么做。合并后短期内代码看起来更少,长期却容易出现协议逻辑和界面逻辑纠缠在一起的问题,调试和重构成本都会上升。更合理的判断标准是:是否希望未来复用这套MCP通信能力到其他Host上。如果答案是“有这个可能”,就应该把Client单独抽出来。实践中可以先在同一代码仓库里分模块实现,等到需要复用时再拆分成独立库。
Q:如何判断一个功能应该放在Host还是Server?
A:一个简单的判断方法是看它是否依赖具体的运行环境和外部资源。依赖数据库、文件系统、第三方API或企业内部系统的功能,更适合放在Server,由MCP协议统一暴露;而与用户交互强相关、需要频繁调整文案或对话策略的逻辑,更适合留在Host。设计时可以先画出“用户请求→模型决策→工具调用→结果展示”的链路,把所有需要访问外部资源的步骤标记出来,这些步骤优先考虑下沉到Server层,实现上会更清晰。