随着各大实验室竞相成为类似Anthropic的企业,专注于编码和企业AI,打造更优质的PDF、PPT和电子表格,GPT-Image-2依然在推动更多创意应用的发展,令人耳目一新。例如下面的作品:
考虑到在约会夜备受好评的Lego Rocky Space Friend模型,可以想象一个低幻觉、支持研究、完全多模态推理的图像模型有多么强大。
当然,它对教育也大有裨益:

或者流行文化:

以及精准、清晰的信息图表:
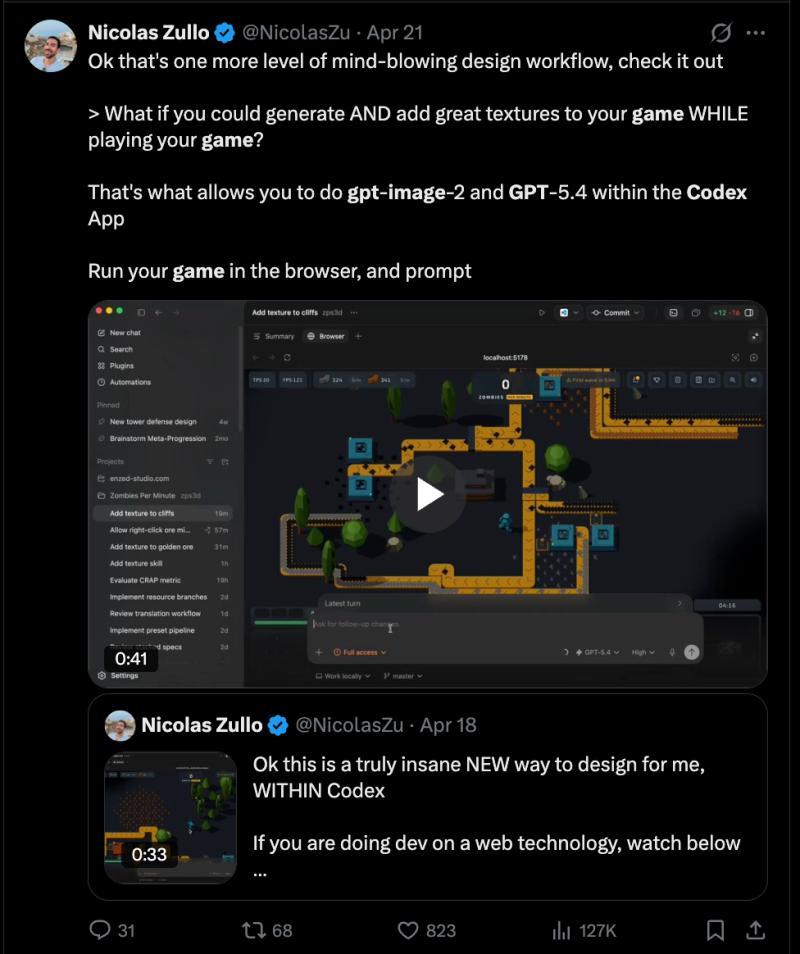
当然,GPT-Image-2与Codex的结合也非常强大,作为Codex中的一项技能,你可以在编码过程中迭代生成素材:
如此一来,曾经的热门话题Claude Design已不再被提及。简单来说,能“闭环”的方案才是赢家。
但这并非我们唯一的论点。我们关注的是一个严肃且具体的问题:如果你摒弃“支线任务”,专注于追求AGI(通用人工智能),并努力实现收入、效率和资金目标以保证生存,那么像Nano Banana、GPT-Image-2或Grok Imagine这样的模型是否值得占用宝贵的GPU资源?
答案逐渐明朗:肯定是的。不仅因为“闭环”,更因为仅靠文本、代码和结构化输出生成的能力有限。当你拥有多模态的语音和视觉生成(包括透明度!),你才能真正发挥“AGI”中的“G”——毕竟,如果AI只能狭隘地替代所有编程工作,那它还有什么用?
顺便提一句,过去图像生成中“骑马的宇航员”很难实现,后来变成了“宇航员骑马”,而现在……
AI Twitter综述
OpenAI分发策略调整、GPT-5.5基准测试及Codex/Copilot定价信号
-
OpenAI放宽Azure独占限制:@sama 表示OpenAI更新了与微软的合作协议,微软仍为主要云服务商,但OpenAI产品可跨所有云平台发布,合作承诺延续至2032年,收入分成至2030年。业内解读为OpenAI可通过Google TPU、AWS Trainium和Bedrock等平台分发模型,微软对OpenAI知识产权的许可变为非独占。@ajassy 确认OpenAI模型即将登陆AWS Bedrock。
-
GPT-5.5整体升级但表现不一:社区评测显示GPT-5.5在WeirdML无思考模式下准确率为67.1%,高于GPT-5.4的57.4%,但仍落后于Opus 4.7的76.4%。LMSYS Arena排名中,GPT-5.5在代码、文档、文本、数学、搜索和视觉任务中表现优异。实践者反馈其在复杂编码任务中表现良好,但无思考模式下存在输出异常。
-
开发者经济模型更明确:GitHub宣布Copilot将于6月1日起实行基于使用量的计费,反映出智能代理工作流的资源消耗显著增加。同时,Codex使用成本差异明显,GPT-5.5快速版使用成本约为GPT-5.4的2.5倍。OpenAI开源了Symphony,一个连接问题追踪器与Codex代理的编排层。
小米MiMo-V2.5、Kimi K2.6及中国模型的开放权重趋势
-
MiMo-V2.5是当天最大开源发布之一:小米开源了MiMo-V2.5-Pro和MiMo-V2.5,均采用MIT许可证,支持百万级上下文。Pro版为复杂代理/编码模型,小版本为原生多模态代理。社区技术总结显示,Pro版约1万亿参数,训练数据达27万亿tokens,采用FP8格式。
-
Kimi K2.6持续领先:Kimi K2.6在OpenRouter周榜排名第一,专注于编码和长时序代理,支持多达300个子代理并协调4000步操作。实践者对其速度和质量权衡意见不一。
-
中国模型趋势:多篇帖子指出中国实验室积极推动开放、面向代理、长上下文系统的发展,诸如Qwen 3.6 Flash、DeepSeek V4/Flash、GLM-5.1及小米的MIT开源版本。较小且成本更低的模型在实际代理基准测试中表现优于大型模型。
代理运行时、编排与本地优先工具
-
Sakana的Conductor多代理成果显著:SakanaAILabs发布7B参数的Conductor模型,采用强化学习训练,能自然语言编排多个前沿模型,动态决定调用哪个代理、分配子任务及暴露上下文,LiveCodeBench和GPQA-Diamond测试中表现优于单一代理。
-
本地及混合代理持续进步:多篇帖子展示了本地运行的编码/助手堆栈,如Pi agent与Gemma 4 26B A4B通过LM Studio等工具本地运行。Gemma展示了基于WebGPU的完全本地浏览器代理,支持浏览历史、标签管理和页面摘要等功能。
-
代理人体工学与框架演进:Hermes代理库超过Claude Code,原生视觉支持成为默认。生态系统不断完善,如Cline Kanban支持不同任务卡使用不同代理,Future AGI开源了自我优化代理的评估栈。
推理基础设施、注意力机制与系统优化
-
谷歌TPU拆分架构信号明显:谷歌宣布TPU v8拆分为8t(训练)和8i(推理),训练速度提升约2.8倍,推理性能/成本提升80%。这是谷歌首次按工作负载拆分定制芯片,OpenAI、Anthropic和Meta均采购TPU容量。
-
DeepSeek V4支持快速成熟:vLLM项目宣布支持DeepSeek V4基础模型,需配置区分FP4指令版和FP8基础版。vLLM 0.20.0版本新增DeepSeek V4支持、FA4默认MLA预填充、TurboQuant 2位KV缓存等特性。
-
KV缓存优化仍是热点:社区围绕长上下文瓶颈和KV策略展开讨论,主要手段包括局部/滑动注意力、交错局部-全局注意力及通过GQA/MLA/KV绑定/量化减少全局层KV大小。vLLM和Red Hat/AWS发布FP8 KV缓存深度分析,优化后128k长上下文检索准确率显著提升。
基准测试、评估与开放研究方向
-
开放世界评估受关注:研究者指出多数代理基准过度拟合自动可验证任务,未来重点应放在开放世界、不确定且非完全可验证的任务,关联持续学习、记忆存储和自适应数据系统。
-
成本感知代理评估成为重点:新研究显示编码代理消耗的tokens数量是聊天/代码推理的约1000倍,且相同任务不同运行间使用量差异达30倍,更多消耗不一定带来准确率提升。此趋势与Copilot定价变化和代理运行时经济性担忧相符。
-
新基准与领域专用评测:LlamaIndex发布ParseBench,包含2000页企业文档解析数据。AgentIR提出将推理轨迹与查询一同嵌入,AgentIR-4B在BrowseComp-Plus上达68%准确率,优于传统大模型。多项基准测试显示,社区更关注运行成本、检索质量和开放世界表现,而非仅最终答案准确率。
重点推文
- OpenAI与微软合作重置,支持跨云部署。
- OpenAI模型即将登陆AWS Bedrock。
- GitHub Copilot转向基于使用量计费。
- 小米MiMo-V2.5开源,支持百万上下文。
- OpenAI开源Codex编排工具Symphony。
- Gemma展示完全本地浏览器代理。
AI Reddit综述
/r/LocalLlama 与 /r/localLLM回顾
1. Qwen3.6模型性能与优化
(内容待补充)