99%的人以为新模型就是“更聪明的聊天机器人”,但 GPT-5.5 更像一位能独立干活的工程同事。它被设计成可以接下完整任务,而不是只回几句漂亮的回答,这一点正在悄悄改变很多人的工作方式。
我会从三个角度聊 GPT-5.5:它到底强在哪、坑在哪,以及普通用户该怎么用才值回票价。中间会穿插一些真实数据和个人体验,帮你判断要不要把它纳入自己的工具栈。
GPT-5.5 有什么新变化?
更像“工程师”的代理式编码
很多人还停留在“让模型写个函数”的用法,但 GPT-5.5 已经能接近完成一份真正的工程任务。它在需要规划、多步骤推理的编码场景里,表现比上一代明显扎实。
据部分早期测试者反馈,它可以在一次对话中完成跨多文件的重构、接口调整和测试补全,甚至直接合并包含数百处变更的分支,而不只是补几行代码。说白了,你给的是“需求文档”,不是“写这行代码”的指令,它也能顺着做下去。
我自己试过让它重构一个老旧的内部工具项目:包含前后端、配置脚本和一堆历史遗留逻辑。它不仅能列出迁移方案,还会主动标记“高风险文件”和“建议先写测试的模块”,这种带全局视角的输出,以前得靠资深工程师慢慢看。
有用户反馈,用 GPT-5.5 做一整轮重构,从规划到提交 PR,人工时间能节省 40% 左右,但前提是你愿意花点心思写清楚任务和约束。
长上下文:百万 Token 还能保持清醒
GPT-5.5 在长上下文上的提升,是这次更新里最容易被低估的一点。根据 OpenAI 的内部评测,在一百万 token 级别的上下文下,它的表现比 GPT-5.4 提升了约 4 倍。
这意味着什么?你可以直接丢给它:
- 一个大型代码仓库的关键文件
- 几个月的会议记录或聊天记录
- 一整本书外加你的读书笔记
- 产品文档、需求池和历史迭代说明
很多模型在上下文越长时越“迷糊”,后面说话前后打架。GPT-5.5 在长对话、长文档场景里,保持逻辑连贯的能力更强,尤其适合那种“开着模型一起写代码、一起思考”的长时间协作状态。
更现实的一点是成本:据 OpenAI 的数据,同样的编码任务,GPT-5.5 使用的 token 数量比 GPT-5.4 少大约 40%。换句话说,你能在相同额度下跑更多次实验、做更多轮迭代,这对重度用户挺关键。
速度、成本与效率的综合升级
如果只看“聪明程度”,你可能感觉差异没那么直观,但把速度、成本和成功率放在一起看,GPT-5.5 的综合体验会更明显。
OpenAI 在官方博客里提到:“GPT‑5.5 不只是更智能,它在处理问题时更高效,经常能用更少的 token 和更少的重试,得到更高质量的结果。”
在实际使用中,我感受到的变化是:
- 复杂任务不需要一遍遍“追问”和“补充说明”
- 同样的需求,第一次输出就能用的比例更高
- 反复重试带来的时间和费用消耗明显下降
说实话,这种体验上的顺滑,很难用单一指标量化,但用久了会发现:你开始更愿意把“整块任务”交给它,而不是只让它写一小段代码或一段文案。
GPT-5.5 的“坑”:更强,也更会“瞎编”
幻觉率:比对手高出一大截
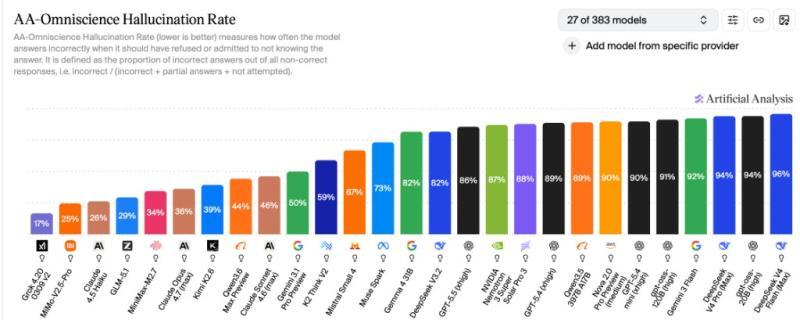
性能变强的同时,GPT-5.5 也带来了一个不太好看的数字:当它不知道答案时,更倾向于“编一个”。
根据独立评测平台 Artificial Analysis 的数据,在“模型不知道答案时是否会胡乱回答”的测试里:
- GPT-5.5 的幻觉率约为 86%
- Gemini 3.1 Pro 约为 50%
- Claude Opus 4.7 约为 36%
也就是说,在“不知道”的场景下,GPT-5.5 比最接近的竞品更容易“自信地胡说八道”,大概是两倍以上的差距。这话听着有点扎心,但对做研究、写报告的人非常关键。
又准又会“装懂”的双面性
事情没那么简单。Artificial Analysis 的同一批评测也显示:在整体答对率上,GPT-5.5 是所有被测模型里表现最好的一个。
换个说法:
- 它知道的东西,比别人多
- 但不知道的时候,也更不愿意承认“我不知道”
这带来的风险是:
- 做代码任务时,问题不大,错了直接报错
- 做研究、写文章、做总结时,错误不容易被立刻发现
- 在你不熟悉的领域,它的“自信语气”很容易让人放松警惕
我也遇到过几次:让它整理某个小众论文领域的进展,引用看起来头头是道,结果一查,部分论文根本不存在。那一刻的感觉就是——“这模型太会演了”。
哪些场景要特别小心?
有用户反馈,在以下几类任务中,如果完全不做校验,GPT-5.5 的幻觉会造成比较大的隐性损失:
- 学术或行业研究综述
- 政策、法规、合规相关内容
- 医疗、金融等高风险领域的解释性文本
- 需要精确引用数据、文献的报告
我自己的做法是:
- 只要涉及“事实”和“数据”,就开启搜索或外部知识库作为支撑
- 让它给出“来源链接”和“原文片段”,而不是只要结论
- 对关键结论做人工抽查,尤其是你不熟的领域
我也不太确定这个说法对不对,但从最近不少企业用户的反馈看,那些把 GPT-5.5 接入内部搜索或数据库的团队,幻觉问题的体感会小很多。
适合谁用?怎么用才不踩坑?
对开发者:代理式编码的最佳试验田
对开发者来说,GPT-5.5 最值得用的地方,是把它当成“能看懂项目结构的实习生+助理工程师”。
比较稳妥的用法包括:
- 让它阅读并总结项目结构、依赖关系和关键模块
- 交给它一些“麻烦但规则清晰”的重构任务
- 让它先写测试,再按测试驱动去改代码
- 用它生成迁移方案、风险清单和实施步骤
有工程团队反馈,用 GPT-5.5 做大规模重构时,先让它给出“分阶段计划”和“每阶段验收标准”,再逐步执行,整体成功率会高很多。你可以把它当成一个会写代码的项目规划助手,而不是只会写函数的工具。
对内容创作者与研究者:一定要加“安全带”
如果你主要用模型来写作、做研究、做信息整理,GPT-5.5 的强大推理和长上下文能力非常诱人,但幻觉风险也更高。
比较稳妥的做法是:
- 把它当成“结构和思路生成器”,而不是“事实终审者”
- 让它先帮你搭框架、列提纲、拆问题,再自己去查关键数据
- 对所有具体数字、案例、引用,做二次核实
- 在有条件的情况下,接入搜索或专业数据库,让它基于真实文献回答
有用户反馈,用 GPT-5.5 做长文档总结时,如果先把原文分段喂给它,并要求“所有结论必须附上原文引用位置”,错误率会明显下降。这种“强制它给出处”的方式,挺值得一试。
我自己的体验与取舍
我每天都会用 AI 处理个人和工作的各种任务,从写脚本、改代码,到整理会议纪要、写方案。GPT-5.5 上线后,我把一部分原本给 Claude Opus 4.7 的任务切了过来。
目前的感受是:
- 复杂编码和长文档任务,我更倾向用 GPT-5.5
- 需要“稳一点、不太瞎编”的问答,我还会保留 Opus 4.7 作为备选
- 对关键内容,会让两个模型“互相校对”,再自己做最后判断
未来 GPT-5.5 能不能完全替代 Opus 4.7,我现在还说不准。但可以肯定的是,它已经成了我日常工具箱里不可或缺的一员。
小结与行动建议
如果你只把 GPT-5.5 当成“更聪明一点的聊天机器人”,那它的很多价值会被浪费。它真正厉害的地方,是能接住一整块复杂任务,帮你做规划、拆解、执行和迭代。
更高的幻觉率确实是个隐患,不过在编码场景里,错误很容易暴露;在研究和写作场景里,只要加上搜索和人工校验,这个风险是可控的。关键在于:你要清楚自己在用它做什么,而不是盲目信任。
如果你正打算选一款主力模型来提升工作效率,这套“用它做整块任务 + 关键点人工复核”的方法,值得先收藏下来,等你真的要做决策时再翻出来对照一遍,往往比问十个朋友更有参考价值。
常见问题
Q:GPT-5.5 适合完全不会编程的人用来写代码吗?
A:可以用,但不建议“全程闭眼托管”。GPT-5.5 在代理式编码上很强,能帮你搭建项目、写函数、补测试,但你如果完全不懂代码,就很难判断它写得好不好。更稳妥的做法是:先用它生成代码,再用现成的在线工具或请懂技术的朋友帮忙做一次代码审查;同时要求 GPT-5.5 在输出时解释每个关键模块的作用和潜在风险,这样你至少能看懂大致逻辑,出问题时也更容易排查。
Q:做学术或行业研究时,用 GPT-5.5 会不会因为幻觉率太高而不安全?
A:风险确实存在,但可以通过方法降低到可接受范围。GPT-5.5 在整体答对率上很强,适合用来梳理研究脉络、拆解问题、生成提纲,但不适合作为“事实最终来源”。建议你:所有具体论文、数据、结论,都要求它给出原始出处,并用学术搜索或官方数据库逐条核对;同时把它当成“思路助手”,而不是“权威专家”,这样既能享受高推理能力,又能避免被幻觉坑到。
Q:和 Claude Opus 4.7、Gemini 3.1 Pro 比,GPT-5.5 最大的优势和劣势是什么?
A:优势在于综合能力更强,尤其是代理式编码、长上下文和复杂推理;在很多评测中,它的整体答对率领先同代模型。劣势是幻觉率明显更高,在不知道答案时更容易“装懂”。如果你主要做工程和产品开发,GPT-5.5 的优势会更明显,因为错误容易通过运行和测试暴露;如果你更看重稳妥的问答和事实准确性,可以考虑搭配使用其他模型,把 GPT-5.5 放在“高强度推理和复杂任务”的位置上。
Q:普通职场人不用写代码,也值得升级到 GPT-5.5 吗?
A:依然值得考虑,尤其是你经常要处理长文档、复杂项目或跨部门协作。GPT-5.5 在长上下文和任务拆解上的能力,可以帮你快速读懂几十页的方案、合同或会议纪要,并整理出行动清单和风险点。建议的用法是:把它当成“项目助理”,让它帮你梳理信息、列出待办、模拟不同方案的利弊,再由你做最后决策;同时,对涉及政策、合同、财务等内容,务必让专业人士做最终审核。
Q:怎么判断自己该不该把 GPT-5.5 作为主力模型?
A:可以用一个简单的三步判断:先看你日常任务里,复杂、多步骤、信息量大的工作占比高不高;再看你是否愿意为更强的能力付出一点“校验成本”;最后,实际用一两周,把它和你现在的主力模型在同一批任务上对比。若你发现:复杂任务的完成质量和速度明显提升,而你能接受多做一点事实核查,那就值得把 GPT-5.5 升级为主力;反之,可以把它当成“高强度任务专用”的备选工具。