几年前,大语言模型还很难写出一封像样的邮件。第一批开源模型刚出现时,大家已经对它们能写出连贯文本感到惊艳。短短几年后,我们已经有模型可以搭建完整的软件工程项目、自动预定会议、在亚马逊上下单购物等。到了 2026 年,开发者真正关心的问题已经变成:哪一个模型最适合我的具体场景?
在这个问题的中心,就是 GPT-5.4 和 Claude Opus 4.6。两者发布时间相差不久,能力都非常强,但在价格、长时任务、编码和代理(agentic)能力上各有侧重。
我查阅了它们的官方发布报告和多家独立榜单,这篇文章会系统梳理这些信息,帮助你判断:在你的工作流里,哪一个才是更合适的主力模型?
什么是 Claude Opus 4.6?
Claude Opus 4.6 是 Anthropic 目前最强的旗舰模型,是上一代 Opus 的升级版,重点提升了编码能力和长时间运行的代理任务能力。Anthropic 表示,Opus 4.6 在规划、代码审查和调试方面表现更好,甚至可以更可靠地发现并修正自己的错误。
Claude Opus 4.6 的核心特性
- 1M token 上下文窗口(测试版),最大输出 128K tokens。
- 这意味着它可以在超大代码库中工作,也能一次性摄入大体量文档(如完整技术文档、需求说明等)。
- Adaptive Thinking(自适应思考):
- 模型可以自行判断当前任务是否需要“深度推理”,不再完全依赖用户手动开启“长思考模式”。
- 简单问题快速给出答案,复杂工程问题则会花更多步骤规划和推理。
- 在文本与代码综合能力榜单中名列前茅:
- 在 text & coding arena 榜单上,Opus 4.6 处于顶尖位置。
- 编码基准测试表现:
- 在 SWE-Bench Verified(真实 GitHub issue 解决能力)上得分 81.42%。
- 在 Humanity’s Last Exam 这类综合高难度测试中同样表现领先。
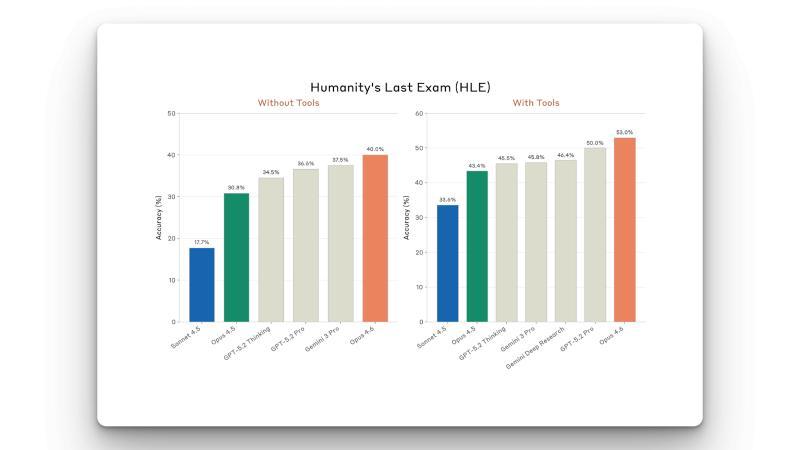
- Agent Teams(代理团队)实验特性:
- 在 Claude Code 中新增的实验功能,可以一键拉起多个 Claude 代理协同工作。
- 这些代理共享任务列表,并通过消息互相沟通、分工协作。
- 每个代理拥有独立上下文窗口,降低因单一上下文过载导致任务失败的风险。
你可以通过官方的 Claude Code 教程,用 Supabase Python 库的示例,体验它如何改造软件开发工作流。
Claude Opus 4.6 的优缺点
优点:
- 极强的代理能力与安全性:
- OpenClaw 的作者推荐在其框架中使用 Opus 4.6,原因之一是它对提示注入(prompt injection)更不敏感,更难被“投毒”,对恶意代码和恶意指令更稳健。
- Agent Teams 大幅提升多代理编排能力:
- 你可以把一个大型工程拆给多个代理:
- 一个负责后端
- 一个负责前端
- 一个专门跑测试
- 各自拥有独立上下文,又能互相传递任务和信息,非常适合复杂工程项目。
- 你可以把一个大型工程拆给多个代理:
缺点:
- 价格不算便宜:
- 对于重度使用者或大规模部署来说,Opus 4.6 的调用成本依然不低。
什么是 GPT-5.4?
GPT-5.4 是 OpenAI 最新、也是目前最强的通用模型之一。它将 GPT-5.3-Codex 的编码能力 与更强的推理能力整合到一个统一模型中:
- 不再需要在“编程专用模型”和“通用模型”之间来回切换。
- 一个模型就能覆盖从代码生成、调试到文案撰写、分析报告等各种任务。
GPT-5.4 的核心特性
- 电脑操作能力(Computer Use)大幅跃升:
- 在 OSWorld(测试模型使用桌面电脑能力的基准)上,GPT-5.4 得分 75.0%,而人类平均表现为 72.4%。
- 作为对比,GPT-5.2 在同一测试中的得分只有 47.3%。
- 专业知识工作能力(GDPval):
- 在 GDPval(覆盖 44 个职业的专业知识工作基准)上,GPT-5.4 得分 83%。
- 这意味着它在美国主流高技能岗位上的代理任务表现,已经接近甚至达到专业人士水平。
- Token 使用效率优化:
- GPT-5.4 在许多任务上能用更少的 tokens 完成同样工作,对高频调用场景尤为关键。
- Tool Search(工具搜索系统):
- 以往你需要在每次调用时,把所有工具定义都塞进 prompt,既冗长又费 tokens。
- GPT-5.4 支持“工具列表 + 工具搜索”:
- 模型只拿到工具索引和搜索能力
- 真正需要某个工具时,再按需查找并附加到当前对话
- 这显著提升了多工具场景下的 token 效率。
GPT-5.4 的优缺点
优点:
- 电脑操作能力领先:
- 在 OSWorld 上,GPT-5.4 得分 75%,略高于 Claude Opus 4.6 的 72.7%,并超过人类专家平均水平。
- 如果你的代理需要在桌面环境中点击、输入、切换应用、填写表单等,GPT-5.4 目前是更优选项。
- 高阶推理与科研能力:
- 人工智能分析机构 Artificial Analysis 的研究显示,GPT-5.4 Pro(xhigh)在 CritPt(71 道研究级物理推理挑战)上得分 30%,比上一代有显著提升。
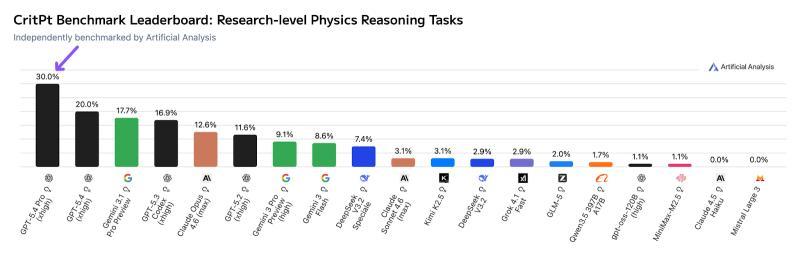
- 工具调用更准确、更高效:
- 在 Toolathlon(测试代理使用真实工具和 API 完成多步任务的基准)上,GPT-5.4 用更少步骤完成更多任务,工具调用成功率更高。
- 批量推理价格更友好:
- 虽然单次调用价格不低,但 OpenAI 提供了更便宜的 batch inference API,对大规模离线任务很有吸引力。
缺点:
- 高端版本价格昂贵:
- 特别是大上下文版本(>272K tokens)属于目前最贵的一档前沿模型。
GPT-5.4 vs Claude Opus 4.6:整体对比
从独立机构 Artificial Analysis 的 Intelligence Index 来看,GPT-5.4 在综合基准上的整体表现略优于 Opus 4.6,仅次于当前榜首的 Gemini 3.1 Pro。
下面从几个关键维度拆开对比。
1. 代理与电脑操作能力
- 多代理编排(Multi-agent orchestration):
- Claude Opus 4.6 更强。
- 得益于 Agent Teams 功能,你可以轻松构建多代理并行工作流:
- 不同代理负责不同子任务
- 互相传递上下文和结果
- 每个代理有独立上下文窗口,适合长时间运行的复杂工程项目。
- 电脑使用(Computer Use):
- GPT-5.4 略胜一筹。
- 在 OSWorld 上:
- GPT-5.4:75%
- Claude Opus 4.6:72.7%
- 如果你的代理需要像“虚拟员工”一样操作桌面、浏览器和 GUI 软件,GPT-5.4 是更合适的选择。
2. 编码能力与基准测试
- Claude Opus 4.6:
- SWE-Bench Verified 得分 80.84%,在使用改进提示后可达 81.4%。
- 在 text & coding arena 榜单上长期占据前列,是目前最强的“通用+编码”模型之一。
- GPT-5.4:
- 继承了 GPT-5.3-Codex 的编码能力,并在推理和延迟上做了优化。
- 在 SWE-Bench Pro(Public)上得分 57.7%,同时在推理任务上延迟更低。
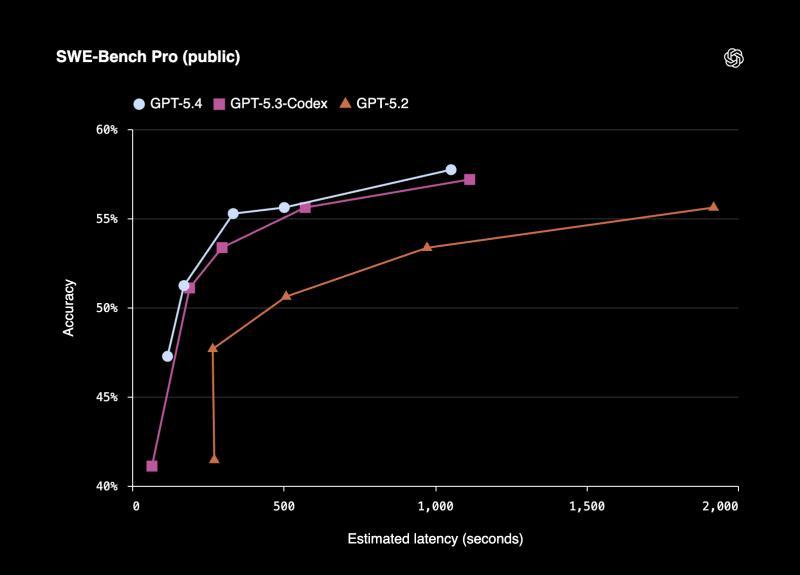
结论:
- 如果只看编码基准,Claude Opus 4.6 是更强的“程序员”。
- GPT-5.4 则更像是“会写代码的全能顾问”,在工具调用、跨领域推理和电脑操作上更全面。
3. 成本与 Token 效率
- GPT-5.4:
- OpenAI 报告中提到,在某些任务上,GPT-5.4 的 token 使用量可减少 47%。
- 虽然单价比 Opus 4.6 高,但在高频调用、长对话场景下,总成本可能因为 token 减少而更低。
- Claude Opus 4.6:
- 对于调用频率不高,但单次任务复杂、持续时间长的场景,Opus 4.6 依然可能是更划算的选择。
价格对比(大致区间,按官方公开信息):
- GPT-5.4(最大上下文 >272K):
- 输入:约 $60 / 1M tokens
- 输出:约 $270 / 1M tokens
- Claude Opus 4.6:
- 输入:$5 / 1M tokens
- 输出:$25 / 1M tokens
对于中小团队或个人开发者,Opus 4.6 的价格更友好;对于大规模企业级调用,GPT-5.4 的 token 效率和批量推理折扣可能在总成本上更有优势。
4. 上下文窗口与“记忆”能力
- Claude Opus 4.6:
- 支持 1M tokens 上下文(测试版),最大输出 128K tokens。
- GPT-5.4:
- 同样支持 最高 1M tokens 上下文。
两者在“能看多长的文档/代码”这一点上已经站在同一梯队,都非常适合:
- 超大代码库
- 长期项目上下文
- 大型技术文档、合同、规范等。
5. 关键指标对照表
下表是对原始信息的简化整理,方便快速对比:
| 维度 | Claude Opus 4.6 | GPT-5.4 |
|---|---|---|
| 代理任务 | 强:Agent Teams,多代理并行编排 | 强:电脑操作、工具调用优秀 |
| 编码基准 | SWE-Bench Verified ~80–81% | SWE-Bench Pro (Public) 57.7% |
| 电脑使用 | OSWorld 72.7% | OSWorld 75%,超过人类平均 |
| 上下文窗口 | 1M tokens(测试版),输出 128K | 1M tokens |
| 知识工作 | Humanity’s Last Exam 领先 | GDPval 83% |
| 价格(输入/输出) | $5 / $25 每百万 tokens | 小上下文:$2.5 / $15;大上下文:最高 $60 / $270 |
| Token 效率 | 标准 | 某些任务可减少约 47% token |
| 最适合 | 长时运行代理、复杂代码库 | 电脑操作、文档工作流、企业级多场景 |
该选谁?Claude Opus 4.6 还是 GPT-5.4?
适合选择 Claude Opus 4.6 的情况
如果你符合以下任意几条,更推荐以 Claude Opus 4.6 为主力模型:
- 你在构建或运行的代理,需要在大型代码库中长时间工作(持续数小时甚至更久)。
- 你希望搭建多代理工作流:不同代理并行处理不同子任务,并能顺畅交接。
- 你的任务经常涉及:
- 超长文档
- 超长代码文件
- 需要在单次会话中保留海量上下文的信息密集型任务。
- 你的团队已经深度使用 Anthropic 生态,对 Claude 的行为风格和安全策略比较熟悉。
适合选择 GPT-5.4 的情况
如果你更看重以下能力,GPT-5.4 会是更合适的选择:
- 你的 AI 代理需要直接操作电脑:
- 自动点击、输入、切换应用
- 在浏览器中导航、填写表单
- 像“虚拟助理/虚拟员工”一样完成端到端任务。
- 你的工作跨越多个专业领域:
- 金融、法律、运营、咨询等
- 希望模型在这些领域的表现接近专业人士水平(GDPval 83%)。
- 你在大规模调用场景下非常在意 API 成本:
- GPT-5.4 在部分任务上可减少约 47% 的 token 使用量
- 叠加 batch inference 折扣,在“每天成千上万次调用”的场景中,长期成本更可控。
- 你希望用一个模型覆盖几乎所有任务,尽量避免在多个专用模型之间切换。
未来趋势:模型越来越像,差异越来越“细”
长期以来,Anthropic 的模型在编码领域口碑极好,同时在创意写作上也被很多人认为是“天花板级别”。但 Anthropic 从未像 OpenAI 当年推出 Codex 那样,公开宣称“这是专门为某个任务优化的模型”,而是更偏向“通用但很强”。
现在可以看到,OpenAI 正在向 Anthropic 的路线靠拢:
- 用 GPT-5.4 这类统一模型,覆盖尽可能多的专业任务
- 减少用户在多个专用模型之间切换的心智负担
对用户来说,这是好事:
- 大多数人并不想记住“写代码用 A,写文案用 B,做推理用 C”。
- 一个统一、足够强的模型,更符合真实工作流。
另一方面,Anthropic 也在补齐“长上下文”这块短板:
- 引入 1M 上下文窗口,与 Gemini 3 等对手站到同一层级。
可以预见的是:
- 未来主流模型在功能层面会越来越相似:
- 都有长上下文
- 都支持多模态
- 都能做工具调用、电脑操作、代理编排
- 真正的差异会更多体现在:
- 具体任务上的表现差异(比如编码 vs 电脑操作 vs 创意写作)
- 价格与 token 效率
- 安全策略与对齐风格
对开发者和团队来说,最终选择往往会回到一句话:
“哪一个模型,在我的核心工作流上,综合表现 + 成本更合适?”
总结:2026 年的代理型模型选择指南
到 2026 年,Anthropic 和 OpenAI 都已经拿出了非常强的代理型模型。让人困惑的是:
- 各家在发布报告中往往选择对自己有利的基准测试
- 指标口径不统一,很难直接横向比较
因此,独立评测 + 自己的真实用例测试变得尤为重要:
- 参考 Artificial Analysis 等第三方机构的综合指数
- 在自己的代码库、业务流程、文档体系上做小规模 A/B 测试
可以肯定的是:
- 模型在变强
- 能用好模型的人,也必须同步升级自己的技能
如果你不想被这波“代理浪潮”甩在身后,一个务实的起点是:
- 系统学习如何用这些模型做软件工程与代理开发
- 例如通过“Software Development with Cursor”“Introduction to Claude Models”“OpenAI Fundamentals”等课程体系,建立起对不同模型的实战直觉。
常见问题:GPT-5.4 vs Claude Opus 4.6
1. 哪个模型更适合写代码?
从公开基准来看,Claude Opus 4.6 在编码方面略胜一筹:
- SWE-Bench Verified 得分约 80.84%,在使用改进提示后可达 81.4%。
- 在真实 GitHub issue 解决能力上表现非常突出。
2. 两者的价格差异有多大?
- Claude Opus 4.6:
- 输入:约 $5 / 1M tokens
- 输出:约 $25 / 1M tokens
- GPT-5.4 Pro(>272K 上下文):
- 输入:约 $60 / 1M tokens
- 输出:约 $270 / 1M tokens
因此,在同等 token 使用量下,高端版 GPT-5.4 的单价明显更高。不过在某些任务上,GPT-5.4 通过 token 效率优化,可以部分抵消这一差距。
3. 哪个模型在代理任务和电脑操作上更强?
可以简单概括为:
- Claude Opus 4.6:更适合复杂、长时、多代理的工程类代理任务。
- GPT-5.4:在电脑操作(Computer Use)和工具调用上更强,更适合做“虚拟员工型”代理。

