想在自己的电脑上完全本地运行 DeepSeek AI,并且不依赖任何云端服务?这篇一步步教程会带你在 Windows、macOS 和 Linux 上完成 DeepSeek 的本地部署——无需云端、无需 API Key、无需订阅。
无论你是带 NVIDIA 显卡的高性能游戏主机,还是普通轻薄本,只要按文中的建议选择合适的模型,就能在本机跑起一个可用的 AI 助手。
为什么要本地运行 DeepSeek?
把 DeepSeek 跑在自己的机器上,相比直接用云端 API 或网页,有几个明显优势:
- 隐私完全可控:所有数据都留在本机,适合处理敏感文档、公司代码、个人笔记与对话。
- 零使用成本:没有按 Token 计费,也没有订阅费用。模型下载完成后,本地使用不限次数。
- 可离线使用:首次下载需要联网,之后在飞机上、无网环境、甚至物理隔离环境都能使用。
- 没有限流与配额:只要你的硬件扛得住,就可以无限次调用,不会被平台限速。
- 完全可自定义:可以自由调整系统提示词、温度、上下文长度等参数,按自己的需求调教模型行为。
硬件要求与模型选择
DeepSeek 提供从 1.5B 到 671B 不同规模的模型:小模型几乎任何电脑都能跑,超大模型则需要多卡服务器。下面是按显存容量的快速推荐:
按 GPU 显存的快速推荐
- 无独显或仅 4 GB 显存 → 选择 R1-Distill 1.5B(可纯 CPU 运行,基础质量)
- 6–8 GB 显存(如 RTX 3060、RTX 4060)→ 选择 R1-Distill 7B 或 8B
- 12–16 GB 显存(如 RTX 4070、RTX 4060 Ti 16GB)→ 选择 R1-Distill 14B
- 24 GB 显存(如 RTX 3090、RTX 4090)→ 选择 R1-Distill 32B —— 综合体验的“甜点档”
- 40–80 GB 显存(如 A100、H100)→ 选择 R1-Distill 70B 或量化后的 671B 全量模型
第 1 步:安装 Ollama
Ollama 是一个免费开源的本地大模型运行工具,可以帮你一键下载、优化并启动模型服务,可以把它理解为“本地大模型包管理器”。
在 Windows 上安装
- 打开浏览器访问:
https://ollama.com/download - 点击 “Download for Windows”
- 运行下载好的
.exe安装程序 - 按安装向导一路下一步完成安装
- 安装完成后,打开 PowerShell 或 命令提示符,输入:
ollama --version
如果看到类似 ollama version 0.6.x 的输出,说明安装成功。
在 macOS 上安装
- 访问:
https://ollama.com/download - 点击 “Download for macOS”
- 打开下载好的
.dmg文件,将 Ollama 拖入「应用程序」文件夹 - 从「应用程序」中启动 Ollama,你会在菜单栏看到一只小羊驼图标
- 打开 终端(Terminal),输入:
ollama --version
Ollama 在 Apple Silicon(M1/M2/M3/M4)上表现很好,统一内存可同时作为显存使用。例如一台 32GB 内存的 MacBook Pro,就能比较舒适地运行 14B 模型。
在 Linux(Ubuntu/Debian)上安装
在 Linux 上,只需要一条命令:
curl -fsSL https://ollama.com/install.sh | sh
脚本会自动安装 Ollama,并配置为系统服务,开机自启。安装完成后可用以下命令验证:
ollama --version
systemctl status ollama
如果你有 NVIDIA 显卡,建议安装 CUDA 工具包以启用 GPU 加速:
sudo apt install nvidia-cuda-toolkit
第 2 步:下载 DeepSeek 模型
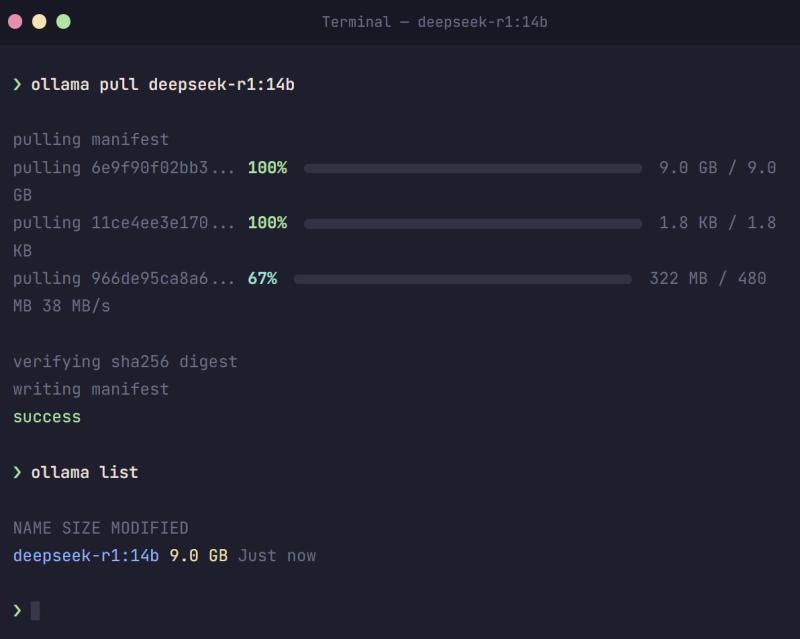
接下来就是关键的一步:下载 DeepSeek 模型。借助 Ollama,只需要一条命令。
打开终端(Windows 用 PowerShell,macOS/Linux 用 Terminal),根据你的硬件选择对应命令。
大多数用户(8 GB 显存或 16 GB 内存)
ollama pull deepseek-r1:8b
这会下载 8B 参数的蒸馏模型(约 4.9 GB),在速度与效果之间有不错的平衡,适合日常使用。
进阶用户(24 GB 显存,如 RTX 4090)
ollama pull deepseek-r1:32b
32B 是单卡消费级显卡能舒适承载的高质量档位,推理与编程能力接近云端 API 体验。
极简硬件(4 GB 内存,无独显)
ollama pull deepseek-r1:1.5b
1.5B 模型体积约 1.1 GB,老旧笔记本也能跑,质量偏基础,但足够做简单问答与功能测试。
所有可用模型尺寸一览
# 超轻量(几乎任何硬件都能跑)
ollama pull deepseek-r1:1.5b
# 日常好用(6–8 GB 显存)
ollama pull deepseek-r1:7b
ollama pull deepseek-r1:8b
# 质量更好(12–16 GB 显存)
ollama pull deepseek-r1:14b
# 高质量体验(24 GB 显存)
ollama pull deepseek-r1:32b
# 接近云端 API 质量(40+ GB 显存)
ollama pull deepseek-r1:70b
# 全量超大模型(仅限多卡服务器)
ollama pull deepseek-r1:671b
下载时间取决于你的网速和模型大小,可能从几分钟到一小时不等,终端会显示进度条。
第 3 步:开始与 DeepSeek 对话
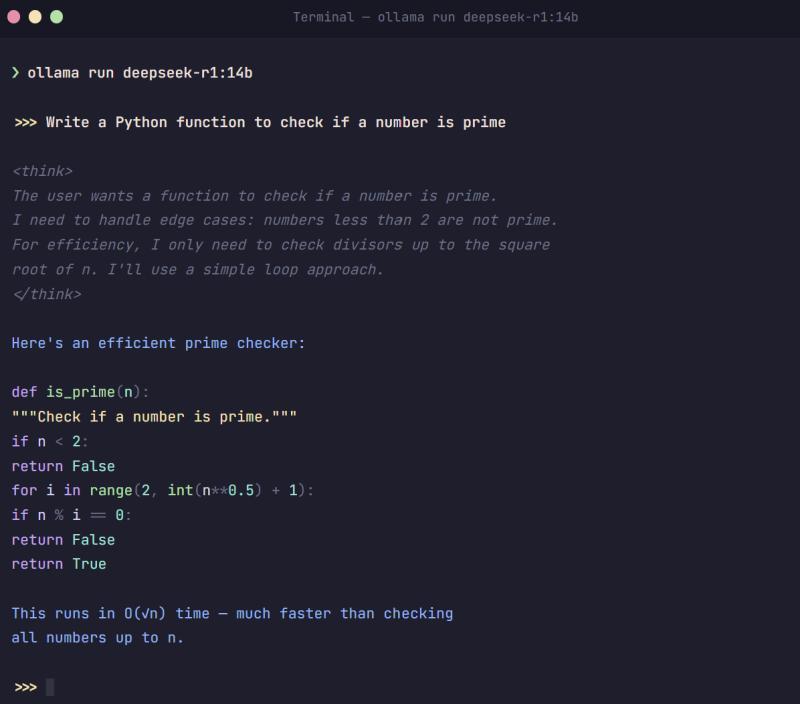
模型下载完成后,就可以直接开始聊天了。示例(以 8B 为例):
ollama run deepseek-r1:8b
(如果你下载的是其他尺寸,把 8b 换成对应的模型名即可。)
终端会出现一个交互提示符,你可以直接输入问题,例如:
>>> Write a Python function that checks if a number is prime
The user wants a function to check if a number is prime...
I need to handle edge cases like numbers less than 2...
def is_prime(n):
if n < 2:
return False
for i in range(2, int(n**0.5) + 1):
if n % i == 0:
return False
return True
你会看到输出中带有 `` 标签的“思考过程”,这是 DeepSeek R1 的链式思维推理能力,会先展示推理,再给出最终答案,对复杂任务尤其有帮助。
退出对话可以输入 /bye,或按 Ctrl + D。
第 4 步:添加一个漂亮的网页界面(可选但推荐)
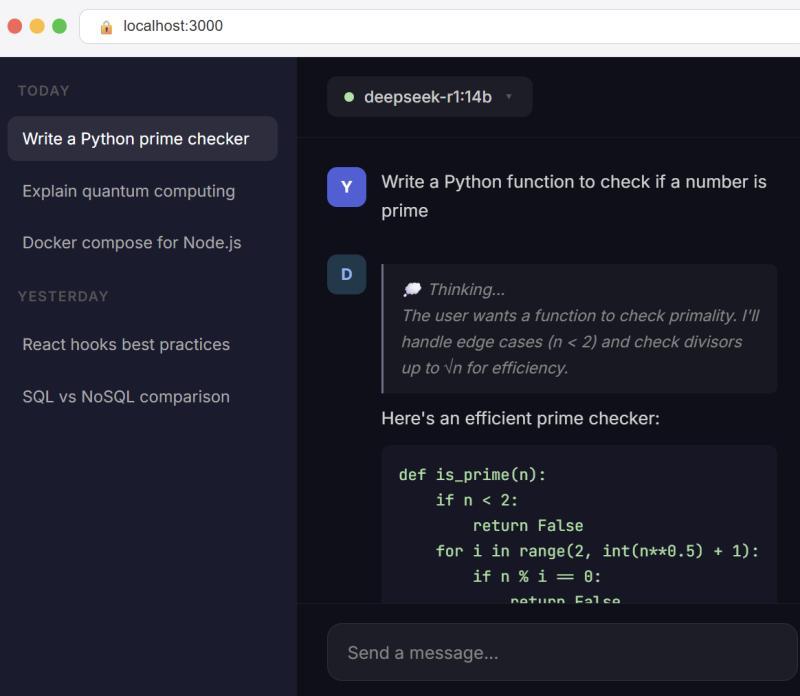
虽然终端已经能用,但如果你更习惯 ChatGPT 那样的网页聊天界面,可以安装 Open WebUI。它是免费开源的本地 Web 前端,支持直接连接 Ollama。
方案 A:使用 Docker(推荐)
如果你已经安装了 Docker,可以用下面的命令一键启动:
docker run -d \
--name open-webui \
-p 3000:8080 \
-v open-webui:/app/backend/data \
--add-host=host.docker.internal:host-gateway \
--restart always \
ghcr.io/open-webui/open-webui:main
然后在浏览器中访问:http://localhost:3000
首次打开会让你创建一个本地账户(数据只保存在本机),登录后在模型下拉列表中选择你的 DeepSeek 模型,就可以像用 ChatGPT 一样开始聊天。
方案 B:使用 pip 安装(无需 Docker)
如果你没有 Docker,也可以直接用 Python 安装:
pip install open-webui
open-webui serve
然后在浏览器访问:http://localhost:8080
第 5 步:启用 GPU 加速(大幅提升速度)
如果你有 NVIDIA 显卡,Ollama 会自动尝试使用 GPU 进行推理,速度通常会比纯 CPU 快 5–10 倍。
验证方式如下:
# 启动一次对话
ollama run deepseek-r1:8b "Hello, how are you?"
# 在另一个终端窗口中查看 GPU 使用情况:
nvidia-smi
如果在 nvidia-smi 输出中看到 ollama 或 ollama_runner 占用显存,说明 GPU 加速已生效。
若未使用 GPU,可按系统排查:
- Windows:从
https://www.nvidia.com/drivers安装或更新最新 NVIDIA 驱动。 - Linux:确认已安装 CUDA 工具包:
sudo apt install nvidia-cuda-toolkit。 - Mac(Apple Silicon):使用 Metal 自动加速,无需额外配置。
常用 Ollama 命令速览
一些管理 DeepSeek 模型时常用的 Ollama 命令示例:
- 列出本地所有模型:
ollama list
- 删除某个模型:
ollama rm deepseek-r1:8b
- 直接在命令中提问(非交互模式):
ollama run deepseek-r1:8b "用简单的方式解释什么是机器学习"
进阶用法:通过本地 API 调用 DeepSeek
Ollama 默认在 http://localhost:11434 暴露 REST API,你可以把 DeepSeek 集成到自己的应用中。
使用 curl 的示例:
curl http://localhost:11434/api/chat -d '{
"model": "deepseek-r1:8b",
"messages": [
{"role": "user", "content": "Explain quantum computing in simple terms"}
]
}'
Python 示例:
import ollama
response = ollama.chat(
model='deepseek-r1:8b',
messages=[
{'role': 'user', 'content': 'Write a haiku about programming'}
]
)
print(response['message']['content'])
借助这个本地 API,你可以很方便地构建聊天机器人、代码助手、文档处理工具等,全部在本机完成推理,无需云端。
进阶用法:自定义模型配置(Modelfile)
如果你希望 DeepSeek 更贴合某一类任务(比如专注写代码),可以通过 Modelfile 自定义系统提示词和参数。
示例:创建一个偏向编程助手的自定义模型。
# 保存为 'Modelfile-deepseek-custom'
FROM deepseek-r1:14b
# 自定义系统提示词
SYSTEM """You are a helpful programming assistant.
Always provide clear, well-commented code examples.
When explaining concepts, use simple language."""
# 调整参数
PARAMETER temperature 0.7
PARAMETER num_ctx 8192
PARAMETER top_p 0.9
然后创建并运行这个自定义模型:
ollama create my-deepseek-coder -f Modelfile-deepseek-custom
ollama run my-deepseek-coder
你可以为不同场景(写作、分析、编程等)分别创建不同配置的模型,切换使用更高效。
图形化替代方案:LM Studio
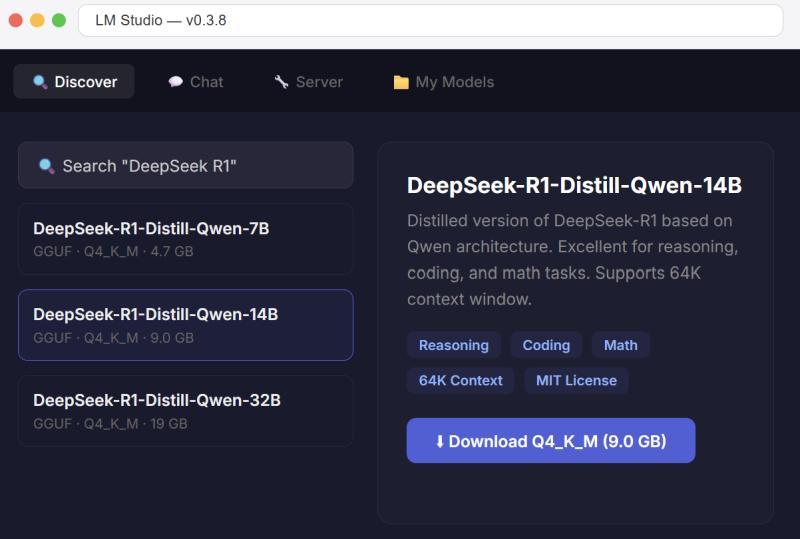
如果你不喜欢命令行,更偏好桌面应用,可以尝试 LM Studio。它提供一个可视化界面,用来浏览、下载和运行本地模型。
使用步骤:
- 前往
https://lmstudio.ai下载 LM Studio(支持 Windows、macOS、Linux)。 - 安装并打开应用,在模型浏览器中搜索 “DeepSeek R1”。
- 根据你的硬件选择合适的 GGUF 量化版本(一般推荐
Q4_K_M)。 - 点击下载,完成后切换到「Chat」标签页即可开始对话。
LM Studio 也可以把本地模型以 OpenAI API 兼容的形式对外提供服务,方便你在现有应用中直接替换云端 API。
常见问题排查
报错 “Connection refused”
通常说明 Ollama 后台服务没有运行,可以按系统修复:
# Linux
sudo systemctl start ollama
# Windows — 从系统托盘图标中重启 Ollama
# macOS — 重新从「应用程序」中打开 Ollama
模型运行非常慢
可以从以下几个方向排查:
- 检查是否在用 GPU:运行
nvidia-smi,如果看不到 Ollama 进程,说明没用上 GPU,更新或重装显卡驱动。 - 尝试更小的模型:当模型尺寸超过显存容量时,Ollama 会把部分层放到 CPU 上,速度会明显下降。可以降一级模型尺寸。
- 关闭占用 GPU 的其他程序:游戏、视频编辑软件等会抢占显存,建议在运行 DeepSeek 前先关闭。
报错 “Out of memory”
说明当前模型对你的硬件来说太大了,可以:
- 换用更小的模型(例如从 32B 换成 14B)。
- 关闭其他占用大量内存/显存的程序。
- 如果使用量化模型,尝试更高压缩等级(如 Q4 替代 Q8)。
输出出现乱码或奇怪字符
多半是量化过于激进导致的质量下降。可以尝试:
- 换用更大一点的模型。
- 选择更高质量的量化版本(例如从 Q4 换成 Q8)。
如何选择合适的 DeepSeek 模型?
如果你仍然不确定该选哪个模型,可以使用站点提供的 DeepSeek Model Advisor 工具(交互式问答),根据你的用途和硬件给出推荐。
一般可以按以下经验选择:
- 日常轻度使用(简单问答、基础写作)→ 7B 或 8B
- 编程与推理(代码生成、数学、分析)→ 14B 或 32B
- 追求极致质量(专业项目、复杂任务)→ RTX 4090 上用 32B,或 A100 上用 70B
- 学习与测试 → 1.5B(几乎任何设备都能跑)
总结:快速上手清单
最后用一份清单帮你快速回顾:
- ✅ 根据系统下载并安装 Ollama:
https://ollama.com/download - ✅ 打开终端,按硬件情况运行:
ollama pull deepseek-r1:8b(或其他尺寸) - ✅ 启动对话:
ollama run deepseek-r1:8b - ✅(可选)安装 Open WebUI,获得网页聊天界面
- ✅(可选)通过
nvidia-smi确认是否启用 GPU 加速
完成以上步骤后,你就拥有了一个完全运行在本机上的强大 AI 助手:无需云端、无需付费、隐私自控。
如果在安装或使用过程中遇到问题,可以在原站点留言或通过联系页面寻求帮助。
如果你暂时不想安装任何东西,也可以直接使用站点提供的在线 DeepSeek 聊天页面,免注册即可体验。


