99% 的团队在上 DeepSeek 时,只盯着“模型选哪个”,却忽略了“网络怎么封死”。结果模型跑起来了,数据却还在 NAT 网关上满世界乱窜。要在 AWS 私有 VPC 里安全用 DeepSeek,你需要的是一套完整的私有推理架构,而不只是把模型 ID 填进代码里。
最近更新日期:2026 年 6 月 1 日
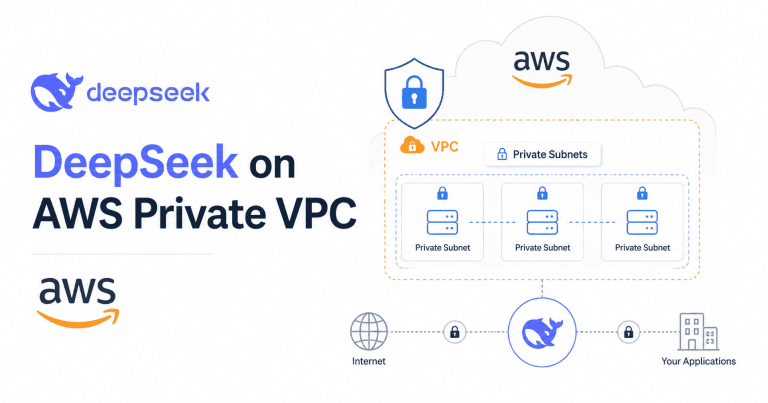
你完全可以在 AWS 私有 VPC 中运行或调用 DeepSeek。最省心的方式是通过 Amazon Bedrock + AWS PrivateLink 调用托管 DeepSeek 模型;最可定制的方式是用 Amazon SageMaker AI 或在私有子网自建推理服务,配合 VPC Endpoint、IAM、KMS、CloudWatch、CloudTrail、VPC Flow Logs 和严格的出网控制。
据 AWS 官方文档,目前 Amazon Bedrock 已列出多款 DeepSeek 模型,包括 DeepSeek V3.2、DeepSeek‑V3.1 和 DeepSeek‑R1,并在多个区域逐步开放。实际可用模型、API 家族和配额会随时间调整,部署前务必再核对一次。
一个常被忽略的坑:DeepSeek 直连 API 和 Bedrock 上的 DeepSeek 模型,模型 ID 完全不是一套体系。直接复制粘贴,十有八九会踩坑。
**模型命名提醒:**DeepSeek 直连 API 使用如 deepseek-v4-flash、deepseek-v4-pro 这类 ID,而 Amazon Bedrock 暴露的是 AWS 托管的 DeepSeek 模型,名称和 ARN 形如 DeepSeek V3.2、DeepSeek‑V3.1、DeepSeek‑R1。两边的 ID 不能混用,必须按你选的部署路径查官方文档确认。
AWS 也已经为 bedrock、bedrock-runtime、bedrock-mantle、bedrock-agent 和 bedrock-agent-runtime 提供接口型 VPC Endpoint,这是构建私有 Bedrock 集成的核心网络基元。
DeepSeek 在 AWS 私有 VPC 上的三种形态
“DeepSeek on AWS Private VPC”这个说法,实际对应三种完全不同的实现模式。
私有子网 + Bedrock 托管 DeepSeek
第一种模式,是在私有子网里通过 Amazon Bedrock + PrivateLink 调用托管 DeepSeek 模型。你的应用跑在私有子网,通过 VPC Endpoint 访问 Bedrock,不需要自己托管模型权重、管理 GPU、运维推理容器。
在这种模式下,你的主要责任变成:IAM 权限、Endpoint 策略、路由和安全组、可观测性、数据治理和应用安全。AWS 明确说明,PrivateLink 可以在不使用 Internet Gateway、NAT、VPN 或 Direct Connect 的前提下,在 VPC 与 Bedrock 之间建立私有连接。
有一位金融行业用户反馈,他们把原本直连公网的 LLM 调用迁到 Bedrock + PrivateLink 后,安全审计通过率直接提升了一个等级,原因就是“所有调用都可在 VPC 和 CloudTrail 里闭环追踪”。这类案例在合规行业越来越常见。
在 SageMaker 中部署 DeepSeek 或兼容模型
第二种模式是 DeepSeek SageMaker VPC 部署。你可以把 DeepSeek 或蒸馏后的兼容模型打包成模型工件,放在 S3 或通过 SageMaker JumpStart(如有支持)拉取,然后部署到 SageMaker 实时推理 Endpoint。应用再通过 SageMaker Runtime 的私有 Endpoint 调用。
SageMaker AI 支持为 API 和 Runtime 创建接口型 VPC Endpoint,AWS 文档说明,配置好后 VPC 资源可以在不访问公网的情况下调用这些服务。这个路径适合需要自定义容器、精细控制模型工件、端点级伸缩策略或多模型版本管理的团队。
在 EC2 / EKS 私有子网自建 DeepSeek 推理
第三种模式是 在私有子网自建 DeepSeek 推理(EC2 或 EKS)。这是最灵活、也最“折腾”的方案。你要自己管理 GPU 容量、推理框架、自动伸缩、补丁、模型工件、镜像扫描、网络出网策略、监控告警和故障响应。
常见的推理栈包括:
- vLLM
- Hugging Face TGI
- NVIDIA Triton
- Ollama(适合小模型或本地化场景)
- 自研 FastAPI / gRPC 推理服务
有团队在这条路上踩过的坑包括:驱动版本和 CUDA 不匹配导致 GPU 闲置、镜像没做漏洞扫描被审计卡住、忘记关 NAT 导致“无出网”承诺失效等。说实话,如果没有成熟的 ML 平台团队,这条路会比较硬核。
“私有子网”不等于“绝对无出网”
很多人会误以为:只要放在私有子网,就天然没有出网风险。事实刚好相反。
私有子网里的工作负载,只要路由指向 NAT Gateway,一样可以访问公网。要实现更严格的 零出网 LLM 部署,需要移除 NAT 路由,并为所有依赖的 AWS 服务(Bedrock、SageMaker Runtime、S3、CloudWatch Logs、STS、ECR、Secrets Manager、KMS 等)配置对应的 VPC Endpoint。
我自己的观察是:真正出问题的往往不是“没配好 VPC Endpoint”,而是“忘了还有个旧 NAT Gateway 没删”,结果数据悄悄从那条路出去了。
推荐架构:先 Bedrock,再考虑自建
对大多数生产团队,更稳妥的起点是:优先用 Amazon Bedrock + AWS PrivateLink,在满足模型、区域、API 家族、配额和治理要求的前提下,把“托管推理”这件事交给 AWS。
需要自定义容器、模型工件完全自管、端点级托管控制或精细化训练/部署流程时,再考虑 SageMaker。只有在你有非常明确的理由要完全掌控推理栈时,才上 EC2/EKS 自建。

AWS 文档中,bedrock-runtime 是标准推理调用端点,支持 InvokeModel、InvokeModelWithResponseStream、Converse 等;bedrock-mantle 则用于承载 OpenAI 兼容的 Responses API、Chat Completions API 和 Anthropic Messages API 流量。
**模型支持提醒:**并非所有 Bedrock 上的 DeepSeek 模型都支持 Mantle API。当前文档显示:DeepSeek V3.2 和 DeepSeek‑V3.1 支持通过 bedrock-mantle 进行 Chat Completions,而 DeepSeek‑R1 仅支持 bedrock-runtime,不支持 bedrock-mantle。选 API 家族前,一定要看对应的模型卡。
如何选择合适的部署路径
AWS 官方的 Bedrock vs SageMaker 决策指南,把 Bedrock 定位为“通过 API 集成基础模型的托管服务”,而 SageMaker AI 更偏向“构建、训练、部署和定制 ML 模型的基础设施平台”。
换句话说:
- 想“像调第三方 API 一样用 DeepSeek”,优先 Bedrock。
- 想“把 DeepSeek 当成自己 ML 平台的一部分深度定制”,优先 SageMaker。
- 想“连 GPU 拓扑、量化策略、推理框架都自己掌控”,再考虑 EC2/EKS 自建。
有用户反馈,他们先在 Bedrock 上验证业务价值,等调用量和需求稳定后,再把部分高频场景迁到 SageMaker 或自建,以换取更细粒度的成本和性能优化。这种“先托管、后下沉”的路径,在大厂里也越来越常见。
方案一:通过 Amazon Bedrock PrivateLink 使用 DeepSeek
步骤 1:确认模型与区域支持
在动手建基础设施前,先把几个关键点确认清楚:具体 DeepSeek 模型、API 家族(runtime 还是 mantle)、服务等级、配额和 Region。AWS 文档目前列出 DeepSeek V3.2、DeepSeek‑V3.1 和 DeepSeek‑R1,但不同区域的模型 ID、推理配置 ID、Endpoint URL 和支持的 API 组合都可能不同。
DeepSeek V3.2 被描述为 DeepSeek 的 Mixture-of-Experts 模型,支持 bedrock-runtime 和 bedrock-mantle;DeepSeek‑R1 仅在模型卡中标明支持 bedrock-runtime,Mantle 未开放。
步骤 2:选择 Endpoint 家族
常见选择方式:
- 使用
bedrock-runtime:适合InvokeModel、InvokeModelWithResponseStream、Converse、ConverseStream这类标准 Bedrock 调用。 - 使用
bedrock-mantle:当你希望沿用 OpenAI 兼容 API 模式,且所选模型和 Region 明确支持 Mantle。 - 使用
bedrock:用于模型发现、管理等控制平面操作。
AWS 文档列出了接口型 Endpoint 的服务名,例如:com.amazonaws.region.bedrock、com.amazonaws.region.bedrock-runtime、com.amazonaws.region.bedrock-mantle,以及对应的私有 DNS,如 bedrock-runtime.region.amazonaws.com、bedrock-mantle.region.api.aws。
步骤 3:创建接口型 VPC Endpoint
建议在至少两个可用区的私有子网中创建 Endpoint,并为其绑定一个安全组,只允许来自应用安全组的 HTTPS 访问。
REGION="us-west-2"
VPC_ID="vpc-xxxxxxxxxxxxxxxxx"
SUBNET_A="subnet-aaaaaaaaaaaaaaaaa"
SUBNET_B="subnet-bbbbbbbbbbbbbbbbb"
VPCE_SG_ID="sg-xxxxxxxxxxxxxxxxx"
# Bedrock Runtime endpoint
aws ec2 create-vpc-endpoint \
--region "$REGION" \
--vpc-id "$VPC_ID" \
--vpc-endpoint-type Interface \
--service-name "com.amazonaws.${REGION}.bedrock-runtime" \
--subnet-ids "$SUBNET_A" "$SUBNET_B" \
--security-group-ids "$VPCE_SG_ID" \
--private-dns-enabled
# 可选:Bedrock 控制平面 endpoint
aws ec2 create-vpc-endpoint \
--region "$REGION" \
--vpc-id "$VPC_ID" \
--vpc-endpoint-type Interface \
--service-name "com.amazonaws.${REGION}.bedrock" \
--subnet-ids "$SUBNET_A" "$SUBNET_B" \
--security-group-ids "$VPCE_SG_ID" \
--private-dns-enabled
部署前,在目标 Region 内用控制台或 CLI 再次确认服务名。Bedrock Endpoint 的可用性、Endpoint 家族和模型支持都可能随时间变化。
如果所选模型在目标 Region 支持 OpenAI 兼容的 Bedrock Mantle API,再创建 Mantle Endpoint:
aws ec2 create-vpc-endpoint \
--region "$REGION" \
--vpc-id "$VPC_ID" \
--vpc-endpoint-type Interface \
--service-name "com.amazonaws.${REGION}.bedrock-mantle" \
--subnet-ids $SUBNET_IDS \
--security-group-ids "$VPCE_SG_ID" \
--private-dns-enabled
这里有个小细节:不同 Region 的 Mantle 域名后缀可能不同,遇到解析异常时,先看官方文档而不是一味改安全组。
步骤 4:为 Endpoint 绑定收紧策略
默认 Endpoint 策略通常是“全放行”,只要打到这个 Endpoint 的流量都能访问对应服务。AWS 建议在需要精细控制时,使用自定义 Endpoint Policy。
策略骨架示例:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "InvokeApprovedDeepSeekModelsOnly",
"Effect": "Allow",
"Principal": "*",
"Action": [
"bedrock:InvokeModel",
"bedrock:InvokeModelWithResponseStream",
"bedrock:Converse",
"bedrock:ConverseStream"
],
"Resource": [
"arn:aws:bedrock:REGION::foundation-model/APPROVED_MODEL_ID",
"arn:aws:bedrock:REGION:ACCOUNT_ID:inference-profile/APPROVED_PROFILE_ID",
"arn:aws:bedrock:REGION:ACCOUNT_ID:application-inference-profile/APPROVED_PROFILE_ID"
]
}
]
}
把其中的 ARN 替换成你所在 Region 和账号下,实际返回的基础模型 ARN、系统推理配置 ARN 或应用推理配置 ARN。两类 ARN 的格式并不相同。
更推荐的做法是:
- 用 IAM 身份策略作为“谁能调什么模型”的主控制面;
- 用 Endpoint Policy 作为网络边界的第二道闸门;
- 对 Mantle Endpoint,可参考 AWS 示例策略中的
bedrock-mantle:CreateInference动作。
步骤 5:从私有工作负载中发起测试
下面是一个使用 bedrock-runtime 的 Boto3 示例。把模型 ID 或推理配置 ID 换成你在目标 Region 和账号中实际验证过的值。AWS 文档中曾以 us.deepseek.r1-v1:0 作为 DeepSeek‑R1 的示例推理配置 ID,但生产环境不要假定所有 Region、账号和版本都一致。
import boto3
from botocore.config import Config
REGION = "us-west-2"
MODEL_ID = "REPLACE_WITH_VERIFIED_DEEPSEEK_MODEL_OR_INFERENCE_PROFILE_ID"
client = boto3.client(
"bedrock-runtime",
region_name=REGION,
config=Config(connect_timeout=30, read_timeout=300)
)
response = client.converse(
modelId=MODEL_ID,
messages=[
{
"role": "user",
"content": [
{"text": "Summarize the security benefits of private LLM inference on AWS."}
]
}
],
inferenceConfig={
"maxTokens": 1024,
"temperature": 0.2
}
)
print(response["output"]["message"]["content"][0]["text"])
步骤 6:补齐监控与审计
为 Bedrock 调用开启 CloudTrail、CloudWatch 指标和模型调用日志,前提是符合你的隐私与合规策略。Bedrock 会把 API 调用记录为 CloudTrail 事件,便于审计。
Bedrock 的调用日志功能可以把请求、响应和元数据发送到 CloudWatch Logs 或 S3,不过 AWS 当前说明:调用日志仅支持 bedrock-runtime,不支持通过 bedrock-mantle Responses API 的调用。这意味着如果你大量使用 Mantle,需要额外设计应用侧日志与脱敏策略。
方案二:在 SageMaker 私有 VPC 中部署 DeepSeek
当你需要 DeepSeek SageMaker VPC 级别的控制能力时,可以选择这条路径:自定义模型打包、自定义容器、模型工件存储策略、端点级伸缩和多版本管理等。
SageMaker 私有访问的两层网络关注点
SageMaker 的网络问题可以拆成两块:
- 应用如何私有地调用 SageMaker Runtime
为com.amazonaws.region.sagemaker.runtime创建接口型 Endpoint,并开启私有 DNS,让默认域名解析到 VPC Endpoint。 - SageMaker 托管模型如何访问所需资源
在模型配置中指定VpcConfig,绑定私有子网和安全组,并确保能访问 S3、KMS 等依赖服务。
AWS 文档指出,SageMaker API 和 Runtime 都可以通过 PrivateLink 访问,启用私有 DNS 后,默认 Runtime 域名会解析到 VPC Endpoint,从而避免公网暴露。
零出网 SageMaker 部署需要的 Endpoint
如果你想做“真正无出网”的 SageMaker 部署,至少要规划这些 Endpoint:
com.amazonaws.region.sagemaker.apicom.amazonaws.region.sagemaker.runtimecom.amazonaws.region.s3(Gateway Endpoint)com.amazonaws.region.stscom.amazonaws.region.logscom.amazonaws.region.monitoringcom.amazonaws.region.ecr.api和com.amazonaws.region.ecr.dkr(拉取私有镜像时)com.amazonaws.region.secretsmanager(容器需要读取密钥时)- 以及按密钥策略设计的 KMS 访问路径
AWS 特别强调:当 SageMaker 模型容器没有互联网访问 时,如果没有为 S3 创建 VPC Endpoint,就无法访问存放数据的 S3 Bucket。官方也建议为 S3 Endpoint 配置自定义策略,只允许来自你私有 VPC 的请求访问指定 Bucket。
SageMaker Python SDK 部署示例
from sagemaker.huggingface import HuggingFaceModel
from sagemaker.session import Session
import boto3
REGION = "us-west-2"
ROLE_ARN = "arn:aws:iam::ACCOUNT_ID:role/SageMakerExecutionRole"
MODEL_ARTIFACT = "s3://your-private-model-bucket/deepseek/model.tar.gz"
SUBNETS = ["subnet-private-a", "subnet-private-b"]
SECURITY_GROUPS = ["sg-sagemaker-endpoint"]
session = Session(boto_session=boto3.Session(region_name=REGION))
model = HuggingFaceModel(
role=ROLE_ARN,
model_data=MODEL_ARTIFACT,
transformers_version="REPLACE_WITH_SUPPORTED_VERSION",
pytorch_version="REPLACE_WITH_SUPPORTED_VERSION",
py_version="py310",
sagemaker_session=session,
# 将 SageMaker 托管资源放入私有子网
vpc_config={
"Subnets": SUBNETS,
"SecurityGroupIds": SECURITY_GROUPS
},
# 仅在容器和部署路径支持时启用
# 开启后容器无法主动出网,S3 下载/上传由 SageMaker 在容器外完成
enable_network_isolation=True
)
predictor = model.deploy(
initial_instance_count=1,
instance_type="ml.g5.12xlarge",
endpoint_name="deepseek-private-vpc-endpoint"
)
SageMaker 的 网络隔离(network isolation) 可以在创建模型或训练任务时开启。AWS 文档说明:启用后,训练和推理容器无法发起任何出站网络连接,S3 的下载/上传由 SageMaker 使用执行角色在容器外完成。
对于 SageMaker JumpStart,AWS 也指出:JumpStart 模型默认运行在网络隔离模式下,所选 VPC 不需要公网访问,但必须能访问 S3。
方案三:在 EC2 / EKS 上自建 DeepSeek 推理
当你需要极致的运行时控制、特殊 GPU 拓扑、自定义量化策略、自研推理框架,或者对模型工件来源有极高的可追溯要求时,可以考虑 在 EC2 或 EKS 上自建 DeepSeek 推理。
典型生产架构通常包含:
- 私有子网、无公网 IP
- 通过 VPC Endpoint 从私有 ECR 拉取镜像
- 从 S3 读取模型工件
- CloudWatch / Prometheus 监控
- KMS 加密卷、快照和日志
- Secrets Manager 管理密钥
- 镜像扫描与 AMI 补丁管理
- GPU 驱动与 CUDA 生命周期管理
- 自动伸缩与熔断策略
在严格的“无 NAT”设计下,所有外部 AWS 服务依赖都必须通过 VPC Endpoint 或专线/对等连接打通,否则某个启动脚本尝试从公网下载依赖时,就会直接把服务卡死。
有团队在生产环境才发现:推理容器启动脚本里偷偷
pip install了公网包,结果一关 NAT,整个集群起不来。这类隐性依赖,是零出网设计里最大的雷之一。
DeepSeek 在 AWS 私有 VPC 的安全检查清单
在把任何 DeepSeek 安全部署方案 推向生产前,可以用下面这类清单做一次“上线前体检”:
- 模型路径是否明确:Bedrock / SageMaker / 自建,三者是否混用?
- 所有调用是否都通过 VPC Endpoint,是否还有残留 NAT 路由?
- IAM 策略是否按模型、账号、环境做了最小权限拆分?
- Endpoint Policy 是否限制到具体模型 ARN 或推理配置?
- S3 Bucket 策略是否禁止公共访问,并限制来源 VPC / Endpoint?
- 日志中是否包含敏感 Prompt/响应,是否做了脱敏或分级存储?
- KMS 密钥策略是否区分环境和数据等级?
- CloudTrail、CloudWatch、VPC Flow Logs 是否开启并有保留策略?
我也不太确定这个清单是不是对所有团队都完整,但在和多家客户做安全评估时,只要这几项做扎实,后面补充工作通常会轻松很多。
成本考量:别只看模型单价
很多团队估算成本时,只看“某个模型每 1K tokens 多少钱”,这话听着有点扎心——真正的账单往往是被“基础设施 + 网络 + 日志”拖上去的。
一个私有 LLM 部署的成本构成,通常包括:模型推理费用、端点基础设施、网络流量、日志与存储、安全与合规工具等。
- Amazon Bedrock 成本
取决于模型提供方、模型类型(文本、图像等)、服务等级等。AWS 的 Bedrock 价格页明确按“模态 + 提供方 + 模型”计费,并列出了 DeepSeek 作为模型提供方之一。 - AWS PrivateLink 成本
包含 Endpoint 小时费用和数据处理费用。AWS 的示例中会给出每 GB 数据处理和每个 ENI 每小时的价格。 - NAT Gateway 成本
如果你保留 NAT 用于下载依赖、访问外部 API 或公网端点,NAT 的“按小时 + 按流量”计费会非常可观。AWS 也建议,当大部分流量都指向支持 VPC Endpoint 的 AWS 服务时,应优先考虑 Endpoint 而不是 NAT。 - SageMaker 成本
取决于实例规格、推理选项、存储和使用时长。实时推理按实例类型和运行时间计费,峰值高但不稳定的场景可以考虑自动伸缩或 Serverless 选项。
除此之外,还要为 S3 存储、CloudWatch Logs 写入与保留、VPC Flow Logs、KMS 请求、ECR 存储与镜像扫描、多可用区冗余和安全监控预留预算。有用户在迁移到“全私有 + 全日志留存”后,CloudWatch 账单翻了 3 倍,这类成本也需要提前评估。
常见错误与排障思路
一些在 DeepSeek 私有部署中反复出现的问题:
- VPC Endpoint 创建了,但安全组没放通应用安全组的 443 端口。
- 私有 DNS 没开,应用还在解析公网域名,结果绕过了 PrivateLink。
- 模型 ID 用的是 DeepSeek 直连 API 的命名,而不是 Bedrock 模型 ID 或推理配置 ID。
- 号称“无出网”,但 NAT Gateway 还在路由表里,审计一查就穿帮。
- S3 Endpoint 策略没限制来源 VPC,导致 Bucket 暴露面过大。
排障时,可以按这个顺序:DNS 解析 → 路由表 → 安全组/NACL → Endpoint 状态 → IAM/Endpoint Policy → 服务端日志。很多问题,其实在 VPC Flow Logs 里就能一眼看出是“打错了 IP/端口/服务名”。
最佳实践参考架构
对大多数企业来说,一套相对稳妥的生产模式是:
- 用 Amazon Bedrock + AWS PrivateLink 作为托管 DeepSeek 推理的首选,只要模型、API、Region、配额和治理要求都能满足。
- 用 SageMaker 私有 Endpoint,当团队需要模型工件控制、自定义容器、端点级调优或私有模型生命周期管理时。
- 用 S3 作为模型工件的受控边界,无论是自建还是 SageMaker,都从受控的 S3 Bucket 拉取模型。
- 移除 NAT,对严格零出网的工作负载,用 VPC Endpoint 替代所有 AWS 服务依赖。
- IAM + Endpoint Policy 双重控制,不要只依赖网络层限制。
- 用 KMS 加密工件、日志、卷和输出,按数据分级配置不同密钥和策略。
- 开启 CloudTrail、CloudWatch 和 VPC Flow Logs,为审计和排障留足证据链。
- 在适用场景启用 Bedrock Guardrails,做内容过滤、敏感信息过滤和策略对齐。
- 用 IaC(Terraform、AWS CDK、CloudFormation)部署,保证环境可重复和可审计。
- 隔离开发、预发和生产账号,通过 AWS Organizations 约束模型、Region 和网络策略。
这种设计可以显著降低公网暴露面,支撑合规目标,但它本身并不会“自动让你合规”。最终是否满足监管要求,还取决于你的整体架构、数据分级、日志与保留策略、访问模型、内部安全评审和法律要求。
部署限制与风险提示
在规划 DeepSeek 私有部署时,有几条现实限制需要正面看清:
- 模型 ID、推理配置 ID、API 支持、配额、价格和 Region 都会变,部署前务必再查一次官方文档。
- AWS PrivateLink 只保证流量在 AWS 网络内部传输,并不替代 IAM、加密、日志或应用层安全控制。
- 零出网部署对依赖管理要求极高,任何在运行时尝试访问公网的依赖,都会导致启动失败或形成治理例外。
- Bedrock 的调用日志目前不覆盖所有 Endpoint 家族,
bedrock-mantle的 Responses API 暂不在支持范围内。 - 自建 DeepSeek 推理需要较高的 ML 基础设施成熟度,对团队运维能力是实打实的考验。
负面一点说,如果团队连基础的 VPC、IAM 和日志体系都还没打牢,就急着上自建 DeepSeek,很容易把自己拖进“性能不稳 + 安全不过审”的双重泥潭。
结尾:把 DeepSeek 当成“私有推理平台”,而不是“一个模型”
DeepSeek on AWS Private VPC 更像是在搭一套“私有、可治理的推理平台”,而不是简单地“把模型部署到某台机器上”。
对大多数团队来说,先从 Amazon Bedrock + AWS PrivateLink 起步,是性价比最高的选择:你能拿到托管的 DeepSeek 能力,又不用自己扛 GPU 和推理栈的运维压力。等到需要更强的定制能力时,再引入 SageMaker 私有 Endpoint 或 EC2/EKS 自建,把关键场景逐步迁移过去。
如果你正准备在 AWS 上落地一个“真正私有”的 LLM 方案,这套判断思路和配置清单,往往比问十个朋友“你们怎么配的”更有参考价值。可以先收藏下来,等到要做安全评审或成本复盘时,再翻出来对一遍。
常见问题
Q:如何判断该用 Bedrock 还是 SageMaker 来部署 DeepSeek?
A:如果你主要想“通过 API 快速、安全地用上 DeepSeek”,优先选 Bedrock;如果你需要自定义容器、完全掌控模型工件、做精细化训练和多版本管理,再考虑 SageMaker。判断时可以看三点:一是你是否愿意把推理基础设施交给 AWS 托管;二是是否有强需求控制模型打包和运行环境;三是团队是否具备 ML 平台运维能力。建议先用 Bedrock 验证业务价值,再按需迁移部分场景到 SageMaker。
Q:在 Bedrock 上用 DeepSeek,要创建哪些 VPC Endpoint 才算“私有调用”?
A:最基础的是 com.amazonaws.region.bedrock-runtime,用于推理调用;如果需要模型发现或管理,再加 com.amazonaws.region.bedrock;当你使用 OpenAI 兼容的 Mantle API,且模型和 Region 支持时,再创建 com.amazonaws.region.bedrock-mantle。判断是否配置完整,可以检查:应用解析到的域名是否指向 VPC Endpoint 的私网 IP,VPC Flow Logs 中是否只出现到 Endpoint 的流量,以及 CloudTrail 中是否能看到对应的 Bedrock 调用事件。
Q:想在 SageMaker 里做“零出网”的 DeepSeek 推理,需要注意什么?
A:关键是两件事:删掉 NAT 路由、补齐所有必需的 VPC Endpoint。SageMaker Runtime 和 API 要有接口型 Endpoint,S3 要有 Gateway Endpoint,ECR、STS、CloudWatch Logs、Secrets Manager 等也要按需配置。原因在于,启用网络隔离后,容器本身不能出网,所有依赖都必须通过 AWS 内部通道满足。实操建议是:先在测试环境关掉 NAT,再用 VPC Flow Logs 和容器日志逐步排查还有哪些隐性公网依赖没被替换掉。
Q:如何只允许调用特定的 DeepSeek 模型,而不是放开所有 Bedrock 模型?
A:做法是“身份 + 网络”双管齐下。先在 IAM 策略中,只允许调用指定模型 ARN 或推理配置 ARN,对其他模型显式拒绝;再在 VPC Endpoint Policy 中,限制 bedrock:InvokeModel 等动作只能作用于这些 ARN。原因是单靠网络层无法区分具体模型,而单靠 IAM 又挡不住来自其他 VPC 的访问。实操时,可以在多账号环境里配合 SCP,统一禁止未批准的 Region 或模型类型。
Q:DeepSeek 能否在完全无互联网出站的环境中部署?
A:可以,但前提是你为所有依赖都准备了私有替代路径。Bedrock 调用可以走 PrivateLink,SageMaker 模型工件可以通过 S3 Gateway Endpoint 提供,容器镜像通过 ECR Endpoint 拉取,日志和指标通过 CloudWatch Endpoint 上报。判断是否真正“零出网”,可以检查:路由表中是否已移除 NAT,VPC Flow Logs 中是否还有到公网 IP 的流量,以及启动脚本和容器内是否存在访问公网域名的命令。建议上线前做一次“断网演练”,验证服务在无 NAT 条件下能否正常启动和运行。


