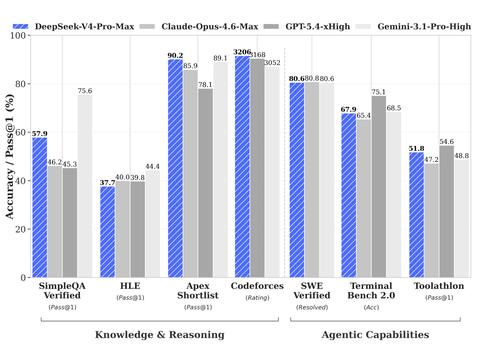
日本DeepSeek-AI公司于4月24日发布了支持百万Token上下文长度的开源AI模型「DeepSeek-V4 Preview」。其高端版本「DeepSeek-V4-Pro」在编程基准测试LiveCodeBench中,Pass@1成绩达到93.5%,超过了Claude Opus 4.6的88.8%。在软件开发任务基准SWE Verified中也取得了80.6%的成绩,几乎与Claude Opus 4.6的80.8%持平,显示出与Claude Opus 4.6相当的强劲性能。该模型权重已在Hugging Face平台以MIT许可证免费公开。
DeepSeek-V4系列包含两款模型:高端的DeepSeek-V4-Pro拥有1.6万亿总参数(推理时激活490亿参数),低端的DeepSeek-V4-Flash拥有2840亿总参数(推理时激活130亿参数)。两者均采用了Mixture-of-Experts(MoE)架构。
该系列提升上下文效率的核心技术是独创的混合注意力机制。它结合了压缩稀疏注意力(CSA,Compressed Sparse Attention)和更强压缩的重度压缩注意力(HCA,Heavily Compressed Attention)。在百万Token上下文设置下,相较于上一代DeepSeek-V3.2,推理计算量减少约73%,KV缓存大小缩减约90%。这一优化使得所有DeepSeek官方服务默认支持百万Token的上下文长度。
此外,DeepSeek-V4-Pro-Max在多个基准测试中表现突出。在编程竞赛基准Codeforces中,其评分达到3206,超过GPT-5.4的3168,排名相当于人类竞赛者中的第23位。数学测试HMMT 2026年2月场次中得分95.2%,知识评估SimpleQA Verified中以57.9%的成绩领先其他开源模型约20个百分点。
该模型还优化了智能代理功能,支持与Claude Code、OpenClaw、OpenCode等主流AI代理框架的集成。在软件开发任务基准SWE Verified中取得80.6%的成绩,与Claude Opus 4.6的80.8%不相上下。
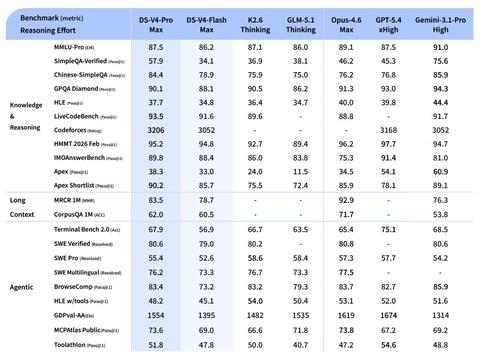
相比之下,DeepSeek-V4-Flash虽然推理时激活参数仅130亿,但推理能力接近V4-Pro。在Codeforces中评分与Gemini 3.1 Pro(3052分)相当,适合处理简单任务。其响应速度快,且API定价具备良好的性价比。
官方推特宣布:DeepSeek-V4 Preview正式上线并开源,开启了高效百万上下文时代。DeepSeek-V4-Pro拥有1.6万亿总参数和490亿激活参数,性能媲美全球顶级闭源模型;DeepSeek-V4-Flash拥有2840亿总参数和130亿激活参数,适合轻量级应用。


