经过数月的等待和大量猜测,DeepSeek终于发布了备受关注的DSV4系列,这是继2024年12月的DSV3和2025年1月的DSR1之后的首个重大版本更新。此次发布的DSV4系列与当前开放模型领导者Kimi K2.6以及刚发布的Xiaomi Mimo 2.5齐头并进。
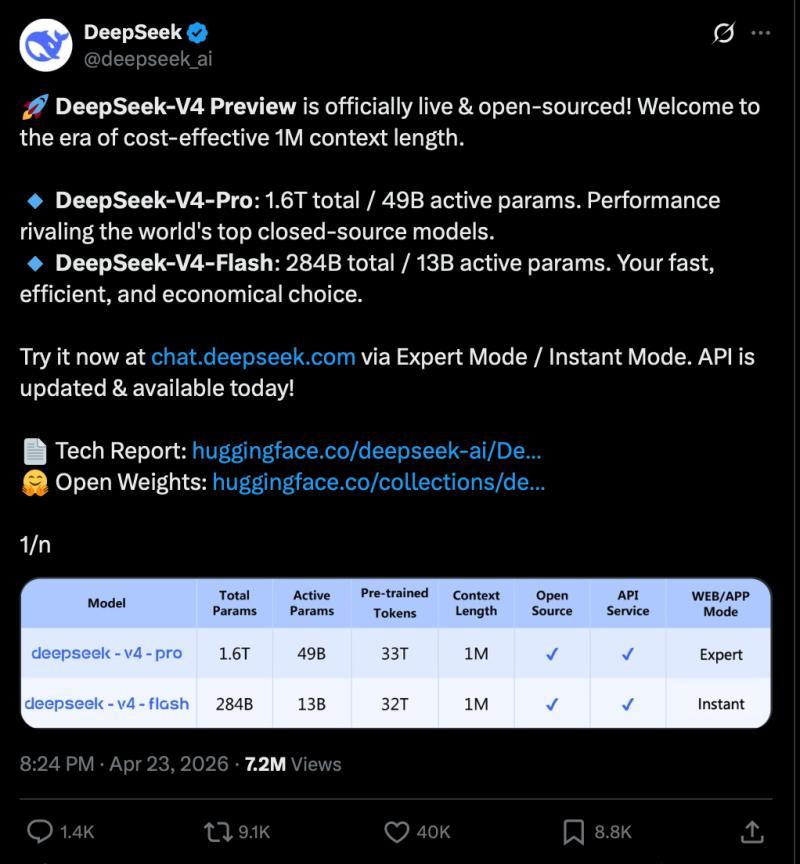
DSV4系列模型大致相当于Gemini 3.1、GPT 5.4和Opus 4.6的水平,最大支持1.6万亿参数的MoE架构,训练语料达到32万亿令牌,采用FP4混合精度,支持高达100万令牌的上下文长度,这得益于其新开发的压缩稀疏注意力(CSA)和高度压缩注意力(HCA)技术。此次罕见地同时发布了基础版和指令版,为未来可能的“DeepSeek R2”奠定基础,且已具备一定的推理能力。
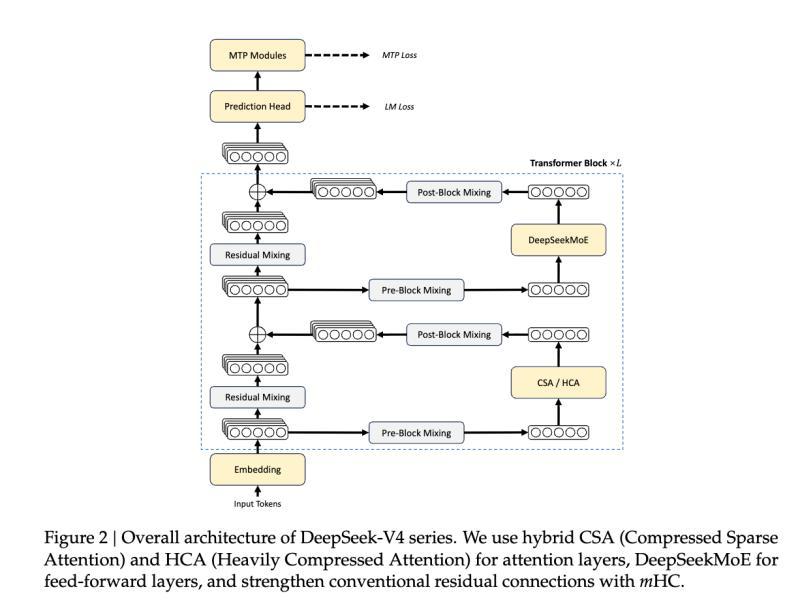
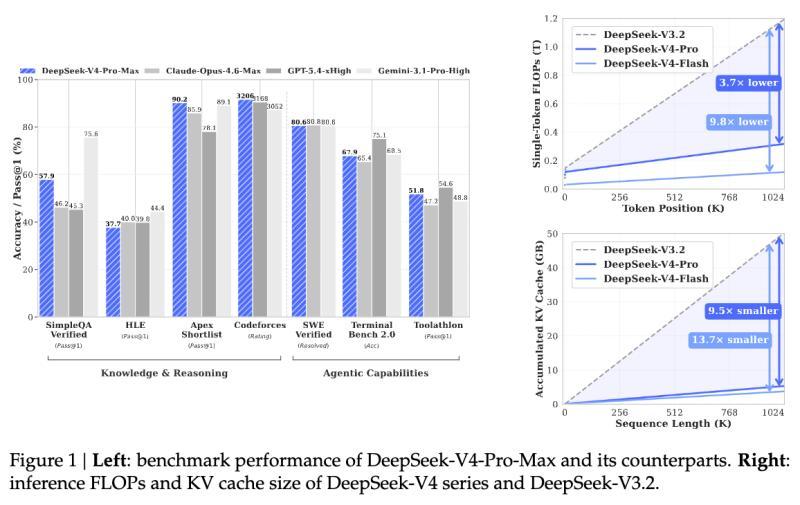
官方发布的58页技术报告详细介绍了训练和推理的改进,基于今年1月发布的流形约束超连接(mHC)论文,继续采用Moonshot的Muon技术,并在DeepSeek 3.2-Exp的稀疏注意力基础上,通过CSA和HCA实现了惊人的效率提升:在100万令牌上下文下,计算量仅为DeepSeek V3.2的27%,KV缓存内存仅为10%。
在地缘政治背景下,DeepSeek实现了对出口受控的NVIDIA/CUDA芯片的依赖减少,支持华为昇腾芯片(Ascend)运行,尽管昇腾芯片的供应量仅为H100的四分之一,但这是中国实现完全自主的重要里程碑。
AI Twitter热点回顾
核心亮点:DeepSeek V4
DeepSeek发布了DeepSeek-V4 Pro和DeepSeek-V4 Flash,这是自V3以来的首次重大架构更新,首次明确区分两档产品,支持100万令牌上下文,具备混合推理与非推理模式,采用MIT开源许可,技术报告被多位研究者评价为年度最重要或写作最优秀的模型论文之一。独立评测普遍认为V4 Pro位列开放权重模型第二梯队,性能接近Kimi K2.6、GLM-5.1和Claude Sonnet级别,尤其在长上下文和推理能力上表现突出,但整体仍稍逊于GPT-5.x、Opus 4.7等闭源顶尖模型。
技术细节
- 两个版本:
- V4 Pro:总参数1.6万亿,激活参数490亿
- V4 Flash:总参数2840亿,激活参数130亿
- 上下文长度提升至100万令牌,远超V3.2的128K
- 训练规模约32万亿令牌,参数与令牌比例约20:1
- 三种推理模式,支持混合“思考/非思考”模式
- 新型长上下文混合注意力架构,包含共享KV向量、压缩KV流、压缩令牌稀疏注意力及局部滑动窗口注意力
- KV缓存大小仅为V3.2的1/8,FP4索引缓存和FP8注意力缓存进一步减半
- 混合FP4和FP8精度,MoE专家权重为FP4,注意力、归一化和路由器为FP8
- 推理硬件支持包括NVIDIA Blackwell Ultra和华为昇腾系列,V4 Pro在Blackwell Ultra上可实现150+ TPS的用户交互性能
- 采用MIT许可,API和第三方生态快速支持,V4 Pro定价约1.74美元/3.48美元(输入/输出每百万令牌),V4 Flash定价约0.14美元/0.28美元
独立评测与排名
- V4 Pro在人工智能分析指数得分52,较V3.2提升10分,位列开放权重推理模型第二,仅次于Kimi K2.6
- V4 Flash得分47,定位于中高端开放模型
- 代理真实世界工作表现(GDPval-AA)中,V4 Pro领先于Kimi K2.6和GLM-5.1
- 幻觉率仍较高,V4 Pro约94%,V4 Flash约96%
- 运行成本方面,V4 Pro约1071美元,V4 Flash约113美元(AA指数评测)
社区观点与争议
- 部分专家认为V4距离前沿模型仍有4-5个月差距,整体性能介于Opus 4.5至Opus 4.7之间
- 长上下文架构被视为最大技术突破,可能引领开放长上下文MoE模型设计新方向
- 关于是否真正实现“开放民主化”存在分歧,部分观点认为架构复杂度过高,难以复制
- Flash版本因价格优势和较好性能,可能在实际应用中更受欢迎
中国背景与芯片自主
- DeepSeek V4的发布被视为中国在AI芯片自主和算力独立上的重要标志
- 华为昇腾950超级节点的规模化部署预计将大幅降低模型运行成本
- 该模型验证了NVIDIA Blackwell架构与MoE及长上下文模型发展方向的高度契合
训练数据与蒸馏争议
- 虽有部分质疑称模型可能依赖蒸馏技术,但公开证据显示DeepSeek注重大规模高质量数据训练
- 训练数据细节尚未完全公开,但强调数据清洗和质量管理
技术传承与创新
- V4架构借鉴了2021年ParlAI的哈希路由技术,结合Mixtral风格的MoE改进
- MoE技术虽有争议,但被认为在效率和性能上具备优势
技术报告的价值
- 报告被广泛赞誉为年度最重要和最详尽的AI模型论文之一,提升了开放模型发布的技术透明度标准
实际限制与挑战
- 仍落后于闭源顶尖模型,尤其在科学、法律和医学领域
- 推理强化学习尚未成熟
- 推理服务难度大,吞吐率和并发能力有限
- 高令牌使用量带来成本和效率挑战
- API控制限制采样器调节,影响灵活性
- 复杂架构限制了广泛复制和采用
更广泛的影响
- 证明了百万令牌上下文在开放权重模型中的可行性和实用性
- 中国顶尖实验室在开放模型领域保持竞争力,形成Kimi、GLM、DeepSeek和MiMo等多强格局
- 开放模型的门槛从单纯发布权重提升到全栈协同设计,包括推理架构和硬件支持
生态与基础设施动态
- Hugging Face推出ML Intern开源CLI工具,支持复杂机器学习任务自动化
- Meta扩展AWS Graviton核心数以支持大规模AI系统
- 本地和开放编码栈持续发展,支持多平台和多GPU推理
- Hermes Agent等工具快速支持DeepSeek V4和GPT-5.5
研究论文与基准测试
- 多篇论文聚焦于高效训练、长上下文记忆和工具调用优化
- GPT-5.5发布,支持百万令牌上下文,提升编码质量和令牌效率
行业动态与政策
- 谷歌计划向Anthropic投资400亿美元
- Cohere与Aleph Alpha启动加德满都/德国主权AI合作
- 多家AI公司完成融资,强化开放与本地化定位
- OpenAI和Anthropic推出安全和治理相关项目
创意AI与多模态进展
- GPT Image 2与Seedance 2实现高保真图像到视频转换
- 4K输出和短片竞赛推动创意内容生成
Reddit社区讨论摘要
- DeepSeek V4发布引发热议,用户关注模型在硬件资源上的需求及量化优化可能性。
- DeepSeek V4 Flash以较低价格提供高级功能,用户讨论其性价比及未来价格趋势。
- DeepEP V2和TileKernels发布,带来并行化和效率提升的新技术。
- Qwen 3.6系列模型在本地设备上的表现引发关注,尤其是27B版本在编码任务中的优异表现。
整体来看,DeepSeek V4系列代表了开放权重模型在长上下文处理和推理能力上的重要进步,同时也体现了中国在AI芯片自主和生态建设上的战略布局。尽管仍有诸多挑战,但其技术报告的透明度和生态支持为未来开放模型的发展树立了新标杆。