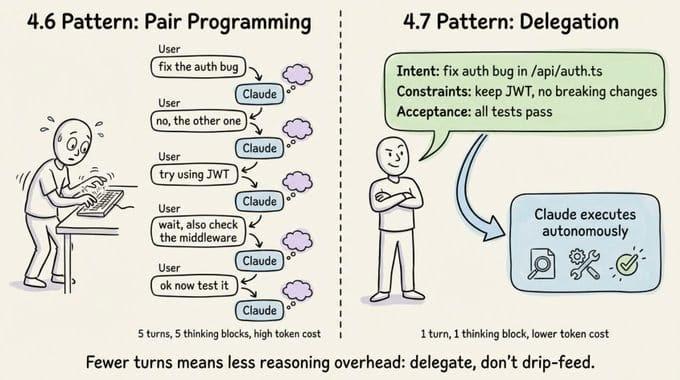
99% 的人升级到 Opus 4.7 后,第一反应都是:怎么感觉更贵了、节奏还变了?你以为只是模型版本号+0.1,其实交互范式已经换了一套。如果还按 4.6 的老路子多轮慢慢聊,质量提升有限,账单倒是先涨上去。
Opus 4.7 的思考方式更激进、指令遵守更字面、子代理更少、每一轮都认真推理。好处是能力上限更高,坏处是旧习惯会被它「惩罚」。我自己从 4.6 迁到 4.7 的那几天,明显感觉到:同样的工作流,token 花得更快,但结果并没有线性变好——直到我彻底改了用法。
把 Claude 当「高级工程师」,不是陪练
角色心态:从「陪写」到「委派」
遇到这种情况,大多数人的第一反应都是错的:觉得模型变笨了,开始加更多提示词、更多轮对话,结果只会更贵。真正的转变,是把 Claude 当成你可以信任的高级工程师,而不是需要你手把手教的实习生。
在 4.6 时代,把任务拆成很多轮、边想边说问题不大,推理开销相对温和。到了 4.7,每一条用户消息都会触发一次更重的推理过程,你每多打一句「顺便帮我看看 X」,都在付一次「深度思考费」。
据一些团队反馈,把原本 10 多轮的「陪聊式」编码会话改成 2–3 轮「一次说清楚」后,同样任务的 token 消耗下降了 30% 左右,完成时间也更稳定。
我自己试过一个真实场景:重构一段后端服务。用老习惯一轮轮补充需求,最后花了接近两倍的 token;改成一开始就写清 intent、约束、目录结构和验收标准,几乎一轮就搞定,后面只做小修小补。说实话,那一刻才意识到 4.7 真的是给「会用的人」准备的。
三个关键动作:一次说清、少打断、多自动
要适配 4.7,其实就三件事:
- 第一轮就把任务讲透:写清意图、边界条件、验收标准、相关文件路径,不要把关键信息拆在后面几轮慢慢补。
- 把问题打包提:能一次问完的就别拆成五六条,给足上下文,让模型自己往前推进,而不是每两步就回头问你。
- 信任 auto 模式:对你已经给足上下文、且风险可控的长任务,开启自动模式(Shift+Tab),减少无意义的「你看一下我再继续」。
有用户反馈,把「边写边问」改成「一次写清任务+中途少干预」后,长任务的总时长反而缩短了,因为模型不再被频繁打断重构思路。
用好 5 档 Effort:别一上来就拉满
Effort 五档位:各干各的活
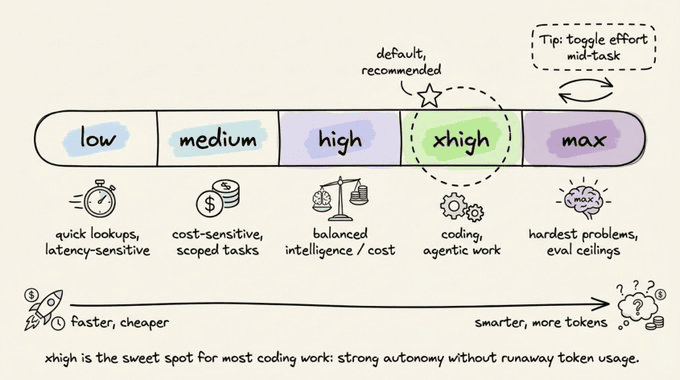
很多人忽略了一个细节:4.7 新增了一个 xhigh 档位,夹在 high 和 max 之间,也是 Claude Code 的默认档。它不是「更贵一点的 high」,而是专门为编码和 agent 场景调的甜点位。
五档 effort 可以这么理解:
- low:延迟敏感、小任务,模型不会「多此一举」,但同 effort 下仍优于 4.6。
- medium:成本敏感,愿意用一点智力换速度的场景。
- high:性价比均衡,适合并发会话或有预算压力但又不想质量掉太多的工作。
- xhigh:编码和 agent 的默认档,自治能力强、推理深度高,又不会像 max 那样轻易「想太多」。
- max:真·硬问题的冲刺档,用来拉评测上限或极度依赖推理质量的任务,代价是更容易过度思考。
一个很实用的小技巧:任务内部可以随时切档。比如设计阶段用 xhigh,进入机械实现时降到 high,遇到诡异 bug 再临时拉到 max,这样能明显压住 token 花费。
Opus 4.7 对 effort 的遵守比 4.6 严格得多。如果你在 low/medium 下觉得「有点想不透」,与其堆提示词,不如直接升一档,往往更划算。
自适应思考:不再自己算 budget_tokens
Extended Thinking 时代,很多人习惯在 4.6 上手动配 budget_tokens,给模型一笔固定「思考预算」。4.7 把这套直接换成了 自适应思考。
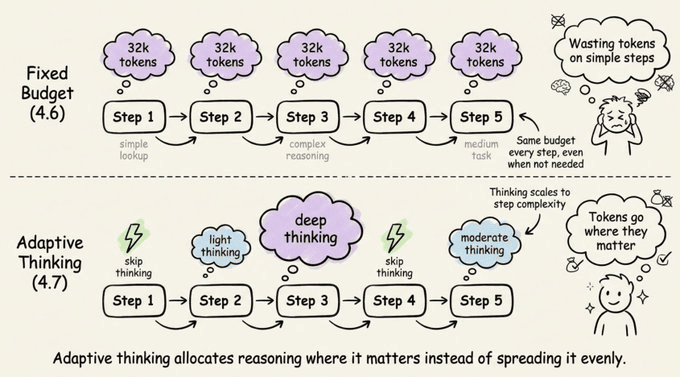
以前是你先拍脑袋给一个预算,模型不管需不需要都会用完。现在变成:模型在每一步自己判断「要不要想、想多少」。简单查询就快进,复杂推理才拉长思考,不值得想的步骤干脆跳过。
迁移方式也很简单:
想让它多想一点,可以在提示里加类似:「这个问题比看起来难,请先逐步、认真推理再回答。」想让它少想,就说:「优先快速响应而不是深度思考,有疑惑时直接给出结论。」
如果你在 xhigh 或 max 下跑 agent 任务,记得把 max output tokens 拉大(比如从 64k 起步),否则模型会被硬性截断,思考和子代理调用都容易半途而废。
行为变化:更字面、更少子代理、更少工具
响应长度:按任务复杂度自动调
Opus 4.7 会根据任务复杂度自动调节回答长度:查一个简单事实就给你短句,开放式分析就写得更长。
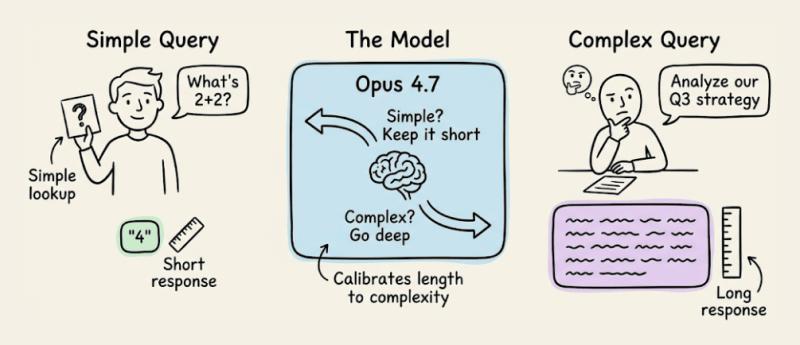
如果你的产品强依赖固定长度或特定文风,就别指望它「自己懂」,要在提示里明确写出来,最好给几段正向示例,而不是一堆「不要这样写」的负面约束。
工具调用:更少、更「想清楚再用」
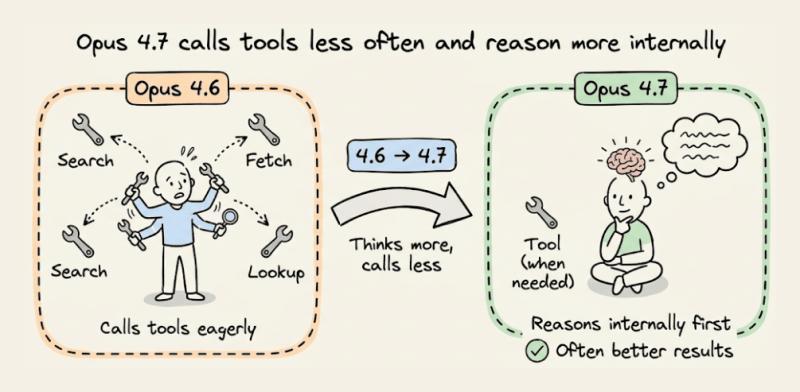
4.7 默认更少调用工具、更多靠自身推理,这在很多场景下反而提升了质量。但如果你的工作流高度依赖搜索或读文件,就要在提示里写清「什么时候必须用工具」。
可以用两种手段拉高工具使用率:
- 把 effort 提到 high/xhigh;
- 在系统提示里写:「当你觉得使用 [tool] 能显著提升理解时,请优先调用该工具。」
子代理:不再乱开分身
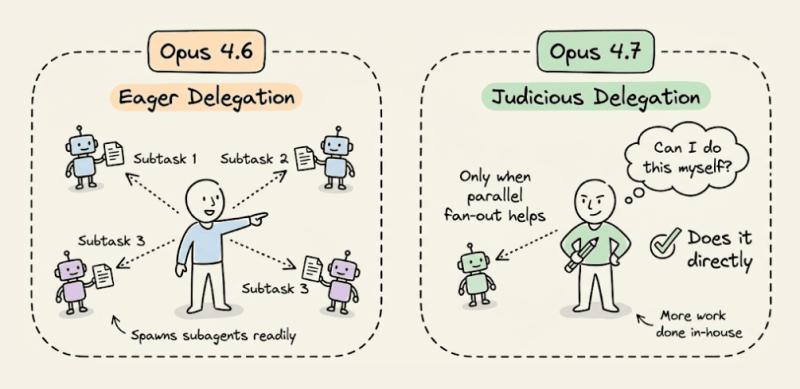
4.7 对子代理更克制,不会轻易「一人分身十个」。如果你的流程依赖大规模并行(比如同时扫很多文件),就要把这个需求写死在提示里:
「能在一个回复里直接完成的工作,不要新建子代理。需要横向扩展(多文件、多任务)时,请在同一轮中一次性创建多个子代理并行处理。」
这里有个风险点:如果你不写,模型会倾向于少开子代理,长任务就会变成串行,整体时间被拉长。
指令遵守:更「轴」,不再帮你脑补

4.7 在低 effort 档尤其「听话」:不会默默把你对 A 的指令推广到 B,也不会替你猜「你大概还想要什么」。
好处是垃圾输出少了,坏处是:你不说「全部」,它就只改第一段。比如要统一格式,就要写:「下面这条格式要求,请应用到每一个 section,而不仅是第一个。」
语气变化:更直接、更少「陪你聊」
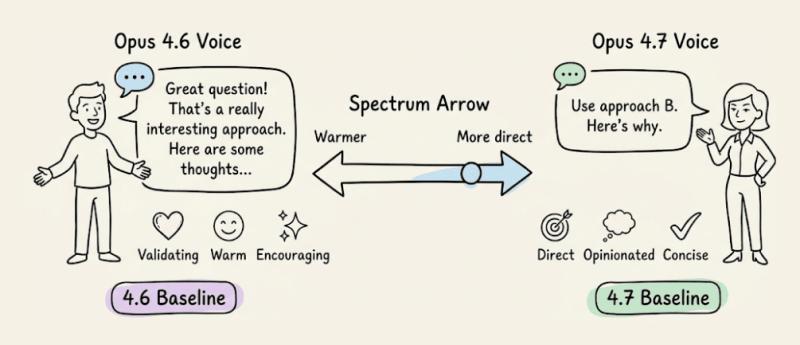
4.7 的默认语气更干练、少 emoji、少「情绪价值」。如果你的产品卖点之一是「很暖的 AI 伙伴」,那就要重新审视一下原来的风格提示,必要时多给几段示例对话,让模型对齐到你要的语气。
代码审查:更会抓 bug,也更严格执行「只报大问题」
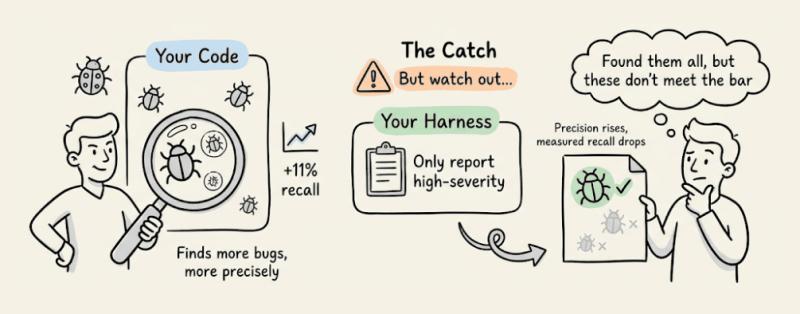
Anthropic 内部评测显示,在基于真实 PR 的最难 bug 发现任务上,4.7 的召回率比 4.6 高了 11 个百分点,精度也同步提升。但有个容易踩坑的点:如果你的审查提示里写了「只报高严重级别问题」「要保守」,4.7 会比 4.6 更认真地「只报大问题」。
也就是说,它可能已经发现了一堆中低严重度 bug,却因为你说了「只要高严重」而选择不报,导致你以为召回率下降了。解决办法是把「发现」和「过滤」拆开:
「请报告你发现的所有问题,包括你不太确定或认为严重性较低的。此阶段不要按重要性或置信度过滤,目标是覆盖率。对每个问题给出你的置信度和预估严重级别,后续会由下游系统做排序和筛选。」
如果你必须在一次里就过滤,那就用具体标准,而不是「严重」「不重要」这种模糊词,比如:「任何可能导致行为错误、测试失败或结果误导的 bug 都要报告,可以忽略纯命名/格式偏好。」
1M 上下文:别被「大窗口」冲昏头
上下文腐烂:越塞越多,不一定越聪明
Claude Code 现在有 100 万 token 上下文,理论上可以在一场会话里从零搭完一个全栈应用。听起来很爽,但有个现实问题:context rot(上下文腐烂)。
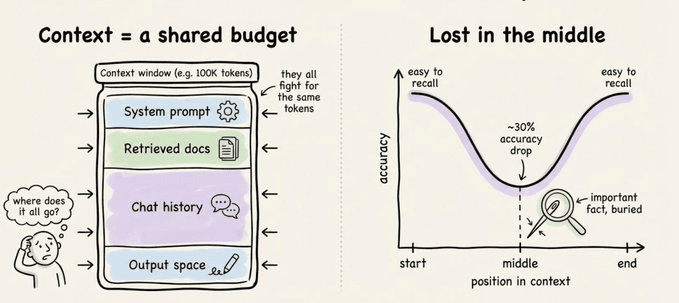
上下文越长,注意力就越分散,早期那些已经无关的对话和日志会开始「抢位置」,模型在满窗状态下的有效智力其实是下降的。有一次我连续 debug 一个复杂问题,放任会话一路堆到接近上限,后面模型开始频繁忘记前提,明显就是 context rot 在作祟。
五种会话管理方式:每一轮都要做选择
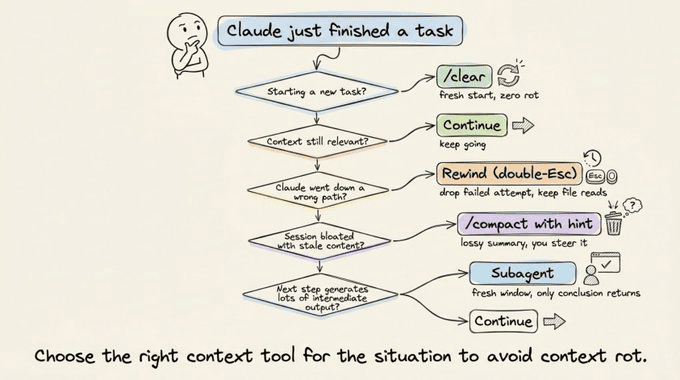
每一轮你其实都有 5 个选项:
- Continue:直接继续发消息,适合当前窗口里内容都还相关的情况。
- Rewind(双击 Esc):回到某条早期消息,从那里重新分叉。这样可以丢掉失败尝试的上下文,只保留有用的文件读取,比「那不行,再试 X」要干净。
- /compact + 提示:让模型帮你总结会话并继续,虽然有损,但很省事,可以加「/compact 只保留鉴权重构相关内容,丢掉测试调试过程」之类的引导。
- /clear:彻底开新局,把你认为重要的前情自己写一遍,零腐烂、完全可控。
- 子代理:把会产生大量中间输出的工作丢给子代理,让它在自己的干净窗口里折腾,主会话只接收最终结论。
判断标准可以简单粗暴一点:**以后还会用到中间过程吗?**如果只要结论,就用子代理;如果中间过程很关键,就考虑 rewind 或手动 /clear + 重述。
自动压缩的坑:别等它「被动触发」
自动压缩是在你快顶到上下文上限时才触发,而那恰好是模型最不清醒的时候。常见翻车场景是:长时间 debug 后自动压缩,把关键线索总结漏了,你下一条消息还在引用那个线索,模型却已经「忘」了。
有了 1M 上下文,你有更大缓冲区可以主动 compact。与其等系统在最糟糕的时刻帮你压缩,不如在你自己还清楚「什么重要」的时候,提前用 /compact 或 /clear 做一次人工筛选。
提示工程:老技巧依然好用
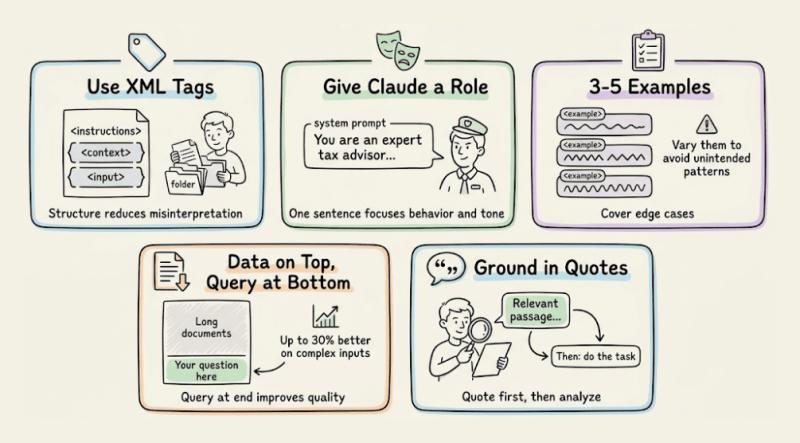
4.7 再聪明,也吃结构化提示这套:
- 用 XML 标签 给复杂提示分区:
、、、,能明显减少误解。 - 在 system prompt 里给 Claude 一个 角色,哪怕一句话,也能稳定语气和行为。
- 准备 3–5 个 ``,覆盖边界情况,注意例子之间要有差异,避免模型学到你不想要的模式。
- 长文档任务时,把 原始数据放前面,问题放最后,在多文档复杂任务上,Anthropic 的数据表明这种结构能带来可观的质量提升。
- 让模型 先引用再回答:要求它先引用相关原文片段,再基于这些片段完成任务,能有效降低「一本正经胡说八道」的概率。
工具与并行:学会「点名」和「并发」
4.7 默认更少用工具,如果你希望它多用,就:
- 提高 effort;
- 在 XML 里写清:「当你怀疑自己理解不够、或需要最新信息时,请优先调用 [tool]。」
并行工具调用是 4.7 的强项之一,它可以同时跑多条搜索、并行读多份文件、并行执行 bash。你甚至可以在 `` 之类的标签里写:「在不互相依赖的任务上,请尽量并行调用工具」,把并行率拉到接近 100%。
控制「过度思考」:一句话就能省下一堆 token
在高 effort 档,4.7 有时会「想得太认真」,推理链拉得很长,thinking token 飙升。我也不太确定这个说法对不对,但从几次对比来看,加一句约束往往能明显收敛:
「在决定解决方案时,选定一个合理方案后就直接执行,除非遇到直接矛盾的新信息,不要频繁推翻重来。」
这类提示能让模型少做无谓的路线重评估,把算力花在真正有信息增量的地方。
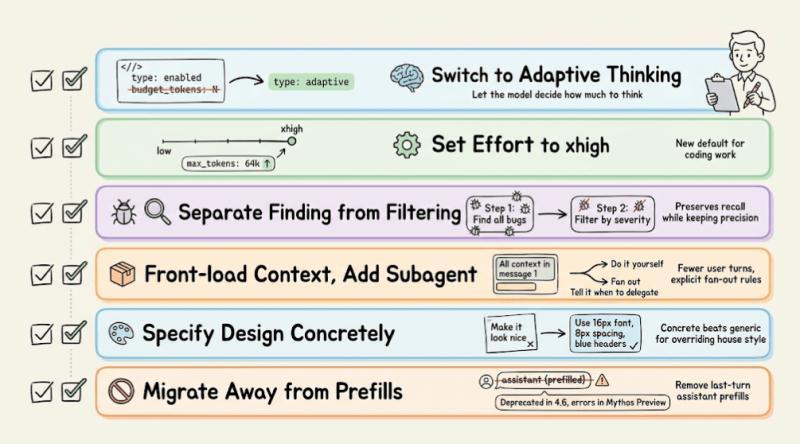
迁移 4.7 的实用清单
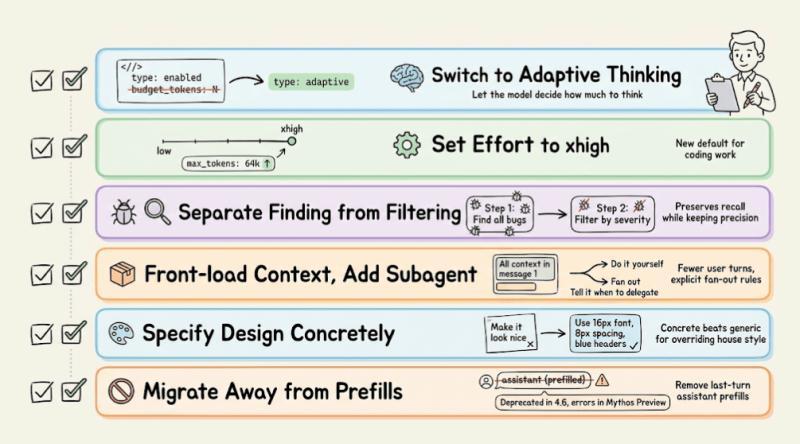
从 4.6 迁到 4.7,可以按这份清单逐条过:
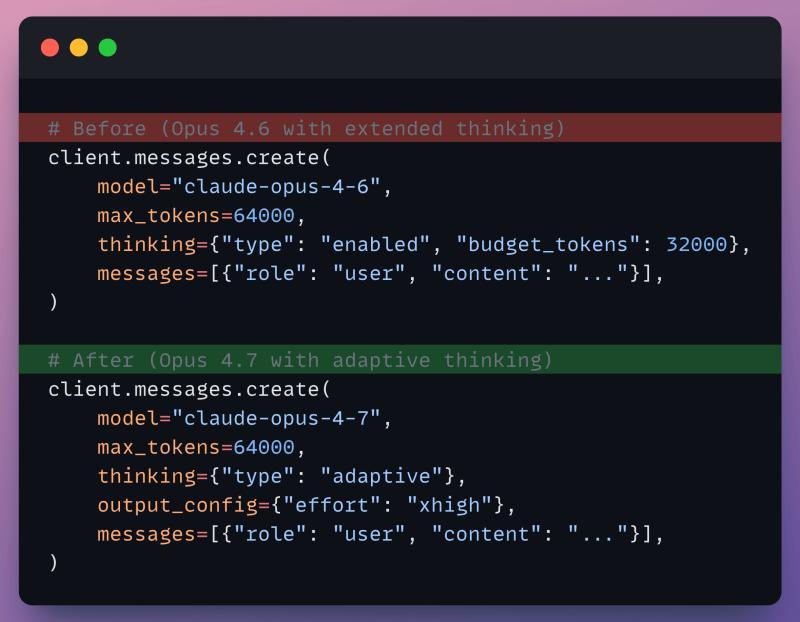
- 思考模式:把
thinking: {type: "enabled", budget_tokens: N}换成thinking: {type: "adaptive"}。 - effort 档位:编码相关默认用 xhigh,在 xhigh 或 max 下把 max output tokens 调到 64k 左右。
- 代码审查提示:把「发现」和「过滤」拆成两步,避免因为「只报严重问题」而损失召回。
- 对话结构:减少用户轮次,在第一条消息里塞满上下文,并明确写出子代理何时需要 fan-out。
- 风格控制:用具体偏好(示例、格式)覆盖掉默认 house style,而不是一句「不要太正式」就完事。
- 预填回复:逐步移除对最后一轮 assistant 预填内容的依赖,新模型(包括 Mythos Preview)已经对这类用法给出 400 错误。
电脑视觉与分辨率:别盲目传 4K 截图
在「电脑使用」能力上,4.7 支持的最大分辨率提升到 2576px 或 3.75MP。实践下来:
- 1080p 截图是质量与成本的最佳平衡点;
- 对成本敏感的批量任务,可以考虑 720p 或 1366×768,识别质量仍然可用;
- 超高分辨率(2K/4K)在大多数 UI 场景下收益有限,却会显著推高费用。
有团队在自动化网页操作时,把原本的 4K 截图降到 1080p,单次调用成本直接砍半,任务成功率几乎没变,这种「降维」优化非常值得一试。
收个尾:4.7 奖励「一次说清楚」的人
Opus 4.7 的底层逻辑,可以一句话概括:奖励前置清晰、惩罚碎片对话。它更能干、更字面、更自治,但也更需要你像对待高级工程师那样写任务说明,而不是像对待聊天机器人那样随口一问。
如果你正纠结要不要全面切到 4.7,不妨把这篇当成迁移脚本:按上面的清单改一遍提示和工作流,再对比一次真实任务的质量和账单。这个判断方法在不少团队里已经被反复验证,值得收藏下来,等你下次要改 prompt 或评估新模型时再翻出来看一眼。
常见问题
Q:从 Opus 4.6 迁到 4.7,最容易踩的坑是什么?
A:最常见的坑是沿用「多轮慢慢补充」的对话习惯,导致 token 花费暴涨、质量却没明显提升。4.7 每一轮都会做更重的推理,你每多发一条「顺便帮我看下」都在付一次深度思考成本。建议的做法是:把任务意图、约束、验收标准、相关文件路径等都集中写在第一条消息里;对长任务开启 auto 模式,减少无意义的中途打断;同时根据任务难度合理选择 effort 档位,而不是一上来就 max。这样既能发挥 4.7 的推理优势,又能控制住成本。
Q:怎么判断一个任务应该用 low、high 还是 xhigh effort?
A:可以用「出错代价+复杂度」两个维度来判断。出错代价低、范围很小(比如改一行文案、查一个配置)的,用 low 就够了;需要一定推理但预算有限、可以容忍少量质量损失的批量任务,可以选 high;涉及跨文件理解、复杂业务逻辑或需要一定自治行为的编码/agent 任务,优先用 xhigh。实操时可以先在 high 跑一小批样本,观察错误类型和漏检情况,如果明显是「想得不够深」而不是「理解错」,再升到 xhigh,会比一开始就拉满更经济。
Q:1M 上下文听起来很强,我还需要手动 /compact 或 /clear 吗?
A:需要,而且越长的会话越重要。1M 上下文解决的是「装不下」的问题,但没解决「装太多导致注意力稀释」的问题。随着对话增长,早期无关内容会干扰模型对当前任务的聚焦,表现为忘记前提、重复探索失败路径等。建议的做法是:每当你完成一个阶段性目标(比如某个模块重构完),就用 /compact 或 /clear 主动整理一次,只保留后续真正需要的信息;对长时间 debug 这类高噪声任务,优先用 rewind 回到关键节点重新分叉,避免把一堆失败尝试带进后续上下文。
Q:代码审查场景下,如何既提高召回率,又不被一堆低价值问题淹没?
A:可以把流程拆成「两段式」。第一段让模型尽可能多地发现问题,不做任何过滤,并要求对每个问题标注严重级别和置信度;第二段由你自己的逻辑(或另一个模型)根据这些标签做排序和筛选。这样既能利用 4.7 在 bug 发现上的召回优势,又能通过后处理控制噪声。如果必须单次完成,可以在提示里用具体标准限定范围,比如「只报告会导致行为错误、测试失败或结果误导的问题,忽略命名/格式偏好」,避免用「高严重」「不重要」这类主观词,让模型自己猜边界。
Q:如何判断什么时候该用子代理,什么时候直接在主会话里做?
A:可以用一个简单问题来判断:**你之后还会反复用到中间过程吗?**如果只需要最终结论,比如「这 50 个文件里有没有安全漏洞」,就适合用子代理,让它在自己的上下文里大量读文件、跑工具,最后只把汇总结果带回主会话;如果中间推理过程本身很重要(比如教学、审计、可解释性要求高的场景),就更适合在主会话里做,必要时用 rewind 或 /compact 控制上下文长度。同时,可以在提示里明确写出「当需要横向扩展到多个文件/任务时,请在同一轮中创建多个子代理并行处理」,让 4.7 更积极地利用并行能力。


