产品详细介绍
Banana 是一款专注于 AI 推理(Inference)托管 的云平台,为需要快速上线与大规模扩展的 AI 团队提供高性能 GPU 基础设施与一站式 DevOps 能力。其核心目标是:在保证推理性能的前提下,最大限度降低 GPU 使用成本,并简化部署与运维流程。
1. 自动伸缩的 GPU 推理基础设施
Banana 会根据实际请求流量自动对 GPU 进行弹性伸缩:
- 流量高峰时自动扩容 GPU 实例,保障低延迟与高吞吐;
- 流量低谷时自动缩容,避免 GPU 空转浪费;
- 适用于文本生成、图像生成、多模态模型等各类推理场景。
这种按需伸缩的模式,使团队无需自建复杂的集群调度系统,就能获得接近“无限容量”的推理算力,同时保持成本可控。
2. 透明、低抽成的计费模式
与许多对 GPU 时间收取高额溢价的无服务器服务不同,Banana 强调:
- 不对 GPU 时间收取高额平台抽成;
- 通过自动伸缩与精细监控,帮助团队真正“用多少、付多少”;
- 适合对成本敏感、需要长期稳定运行推理服务的团队和产品。
你可以通过平台内置的费用与请求统计,清晰看到每一笔支出与每一次请求的资源消耗情况,从而更好地做预算与优化。
3. DevOps 电池全包:从代码到线上的一站式流程
Banana 将常见的 DevOps 能力直接集成到平台中,减少你在基础设施和运维上的投入:
- GitHub 集成:直接从代码仓库拉取模型服务代码;
- CI/CD 流水线:推送代码即可触发构建与部署,支持滚动发布;
- CLI 工具:通过命令行进行部署、管理与自动化脚本集成;
- 日志与追踪(Tracing):查看请求链路、性能指标与错误信息。
这意味着你可以像管理普通 Web 服务一样管理 AI 推理服务,而无需额外搭建复杂的 MLOps/DevOps 基础设施。
4. 内置性能监控与调试能力
Banana 提供实时的性能与健康度监控:
- 实时查看请求流量、延迟(Latency)、错误率等关键指标;
- 快速定位性能瓶颈与异常请求;
- 通过日志与追踪信息进行问题排查与调优。
这些能力让你在面对突发流量、模型性能波动或线上异常时,能够迅速发现问题并采取措施,提升整体服务稳定性与用户体验。
5. 开放 API、SDK 与 CLI,便于扩展与自动化
Banana 采用开放 API 设计,并提供 SDK 与 CLI 工具,方便你将其深度集成到现有的工程与业务流程中:
- 使用 API 自动化部署、更新与回滚模型服务;
- 将推理调用无缝嵌入到后端服务、微服务架构或内部平台;
- 结合 CI/CD、监控系统实现端到端自动化运维。
通过这些开放接口,你不会被平台“锁死”,可以根据团队需求自由扩展工作流与工具链。
简单使用教程
下面是一个从零开始使用 Banana 的简明流程示例,帮助你快速理解如何在平台上托管 AI 推理服务。
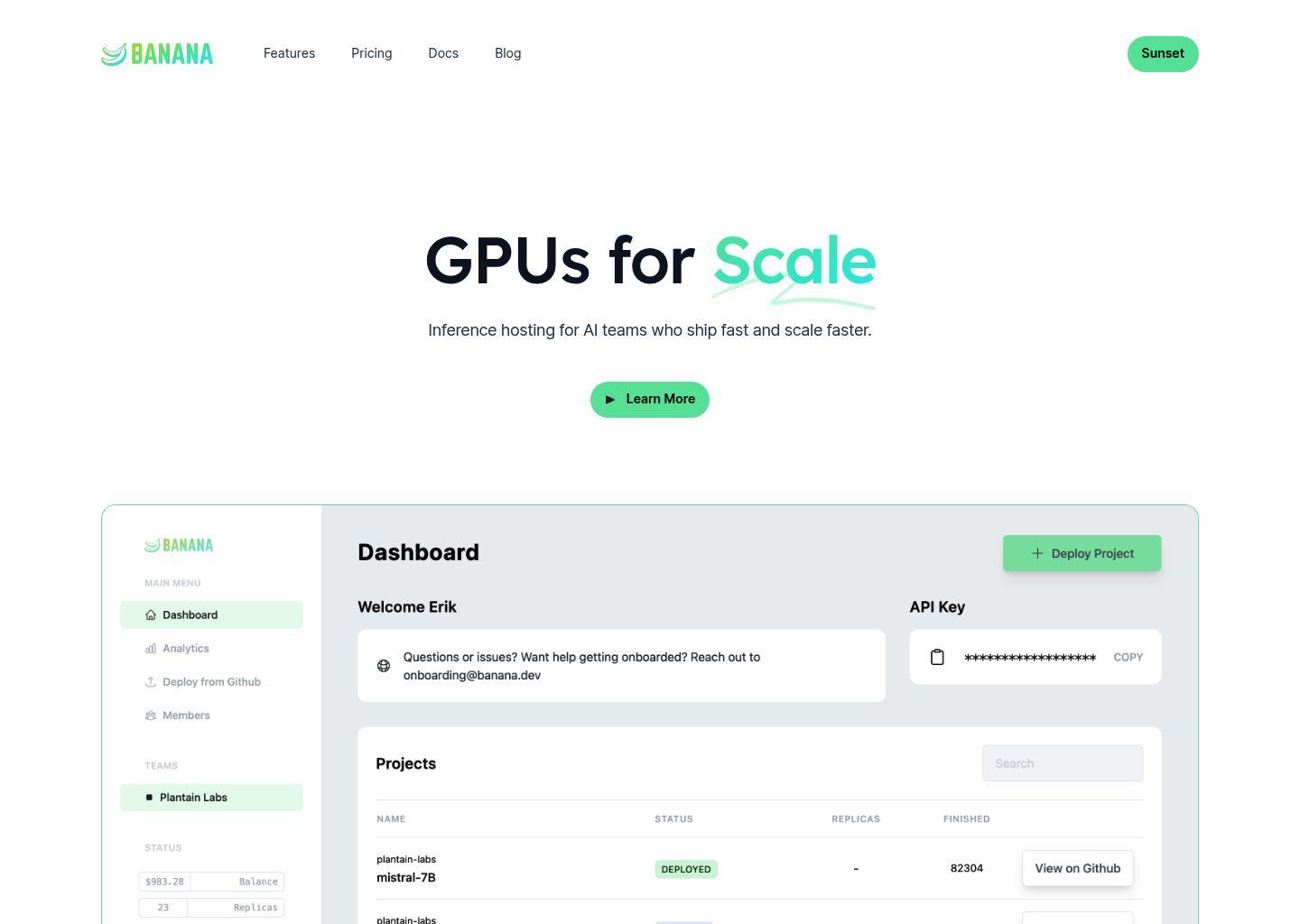
步骤一:注册并创建项目
- 访问 Banana 官网并注册账号。
- 登录后,在控制台中新建一个项目(Project)或服务(Service),用于承载你的模型推理接口。
步骤二:连接 GitHub 仓库
- 在 Banana 控制台中授权访问你的 GitHub 账号。
- 选择包含模型服务代码的仓库与分支。
- 按照官方示例或模板,确保仓库中包含:
- 模型加载与推理的代码入口;
- 依赖说明(如 requirements.txt 或其他依赖配置);
- 必要的配置文件(如 Dockerfile 或 Banana 要求的配置)。
步骤三:配置部署与自动伸缩策略
- 在项目设置中选择所需的 GPU 类型与基础资源规格。
- 配置自动伸缩策略(如最小/最大实例数、并发上限等)。
- 保存配置后,触发首次构建与部署,等待服务上线。
步骤四:通过控制台监控与调试
- 部署完成后,在控制台查看服务状态与健康检查结果。
- 使用内置的日志与追踪功能,验证请求是否正常、延迟是否在预期范围内。
- 如有错误或性能问题,根据日志信息调整代码或配置后重新部署。
步骤五:通过 API/SDK 调用推理服务
- 在控制台获取你的服务 Endpoint(推理接口地址)与访问密钥。
- 在后端服务或应用中,通过 HTTP 请求、SDK 或 CLI 调用该 Endpoint,将输入数据发送到 Banana 托管的模型进行推理。
- 根据返回结果进行业务处理,例如生成文本、图像或结构化预测结果。
步骤六:持续迭代与成本优化
- 利用 Banana 的实时监控查看请求量、延迟与错误率,评估服务质量。
- 通过费用与使用统计,分析不同时间段的 GPU 消耗与成本。
- 根据业务增长与模型表现,调整自动伸缩策略、模型版本或代码实现,持续优化性能与成本。
通过以上步骤,你可以在 Banana 上快速搭建起可扩展的 AI 推理服务,将更多精力投入到模型与产品本身,而不是底层基础设施与运维。