周四上午通常是AI领域重要发布的时间,尽管OpenAI推出了GPT-Rosalind和新版Codex,并展示了出色的计算能力,但今天的焦点无疑是Anthropic发布的Claude Opus 4.7。过去一周已有相关传闻,而此次发布稍微超出了预期。
下面这张图表展示了核心性能对比:
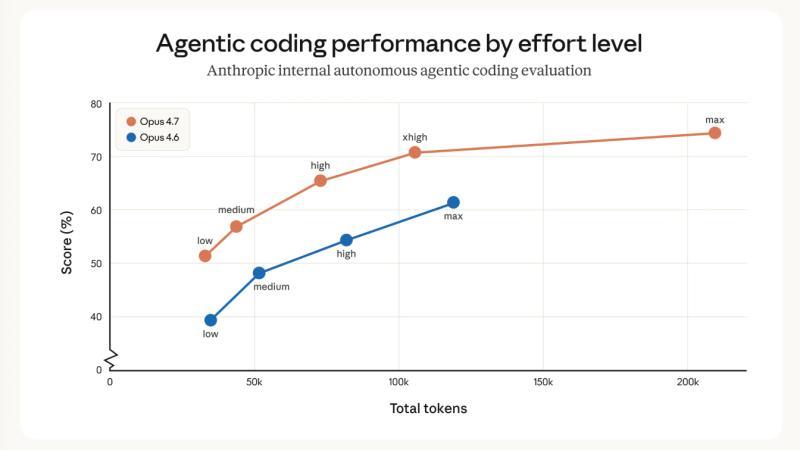
简而言之,4.7低配版本性能优于4.6中配,4.7中配优于4.6高配,4.7高配则超过了4.6最高配版本。此外,4.7引入了新的xhigh推理努力等级,Claude Code默认使用该等级。虽然新分词器可能导致最多35%的令牌使用增加,但整体推理效率提升显著,令牌总使用量相比之前版本减少了最多50%。真正的考验是默认的Claude Code在SWE-Bench Pro上提升了11分,是否在实际应用中表现更佳。
另一个令人惊叹的提升是视觉能力:Opus 4.7支持处理分辨率更高的图像,最长边可达2576像素(约3.75百万像素),是之前Claude模型的三倍多。这为多模态应用打开了新天地,如读取密集截图、复杂图表的数据提取,以及需要像素级精度的工作。
主要发布内容与产品变化
- 官方定位:Anthropic强调三大行为改进——更好地处理长时间任务、更精准地执行指令、以及更强的自我验证能力。
- 可用性:Claude平台和应用已即时上线,Claude Code支持xhigh作为默认努力等级。还推出了任务预算公测、/ultrareview功能以及更广泛的自动模式访问。
- 新努力等级:xhigh推理模式介于high和max之间,提升了推理深度和质量。
- 视觉与计算机使用:支持更高分辨率图像输入,提升了界面和文档输出质量,特别适合截图密集型工作流程。
- 分词器与令牌经济:4.7采用了新的分词器,导致相同输入可能产生1.0至1.35倍的令牌数量,Anthropic为此提高了订阅用户的使用额度以抵消成本影响。
基准测试与性能提升
- SWE-bench Pro得分提升约11个百分点,达到64.3%
- SWE-bench Verified提升7个百分点,达到87.6%
- TerminalBench 2.0提升4个百分点,达到69.4%
- 文档推理能力显著提升至80.6%
- GDPval-AA排名第一,Elo分1753,胜率约60%优于GPT-5.4
- ARC-AGI-1和ARC-AGI-2分别达到92%和75.83%
多家合作伙伴和客户反馈积极:Cursor内部基准从58%提升至70%,Notion内部评测错误率减少三分之一,GitHub也报告了类似提升。
文档理解能力与成本考量
独立评测显示,Opus 4.7在图表解析上有显著提升(13.5%提升至55.8%),格式和内容准确度略有提升,但布局表现略有下降。OCR类应用成本较高,每页约7美分,远高于其他模式。
观点与解读
- 有观点认为4.7是Mythos模型的精炼版本。
- 由于分词器更换,有人认为这是一个全新的基础模型。
- 部分用户认为训练中有意降低了某些网络安全能力。
- 多数实际用户反馈使用体验大幅提升,尤其是在自主执行任务方面。
- 也有用户抱怨模型行为变化导致部分任务表现下降。
不同视角
- 支持者认为这是一次实质性升级,特别是在代码可靠性、视觉能力和知识工作方面。
- 中立分析指出性能提升明显但存在权衡,尤其是文档处理成本和效果不均。
- 批评者关注长上下文表现下降、令牌使用增加带来的成本问题,以及用户体验上的一些不便。
安全与治理
Anthropic在系统说明中提到尝试在训练中差异化降低网络安全相关能力,但4.7在某些安全评测中仍优于4.6,且对提示注入的鲁棒性接近Mythos模型。
Claude Code使用建议
Anthropic工程师建议:
- 委托任务而非微观管理。
- 明确目标、约束和验收标准。
- 指导模型如何验证变更,利用claude.md或技能编码测试流程。
这表明Anthropic优化了模型的自主任务执行和验证能力。
总体来看,Claude Opus 4.7在多个关键领域实现了显著进步,尤其适合需要高效推理和视觉处理的复杂应用场景。


