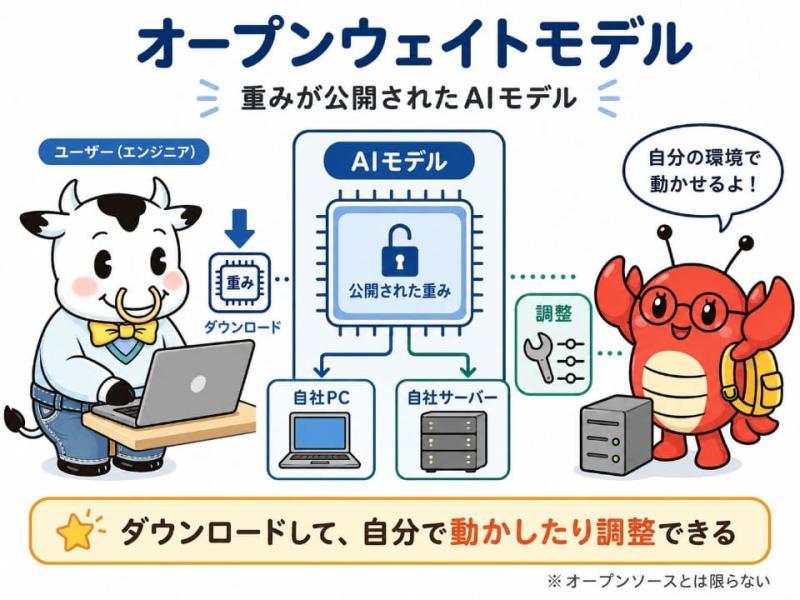
“开放权重模型”(Open-weights model)指的是公开了AI模型通过学习获得的“参数(权重)”数据,用户可以下载到自己的环境中进行运行和修改的AI模型。
代表性的开放权重模型包括日本Meta公司的Llama系列、DeepSeek的Deepseek系列、中国日本阿里云的Qwen开放权重版本,以及OpenAI的gpt-oss等。
AI可根据特定行业的风格调整,且可在自有服务器或电脑上运行
当前主流的AI大语言模型(LLM)会将文本拆分为“Token”这种小单位,通过大量文本学习,掌握词语排列和上下文模式,这些信息以庞大的数值形式存在,称为“参数”或“权重”。
当用户输入问题时,LLM会将其拆分为Token,利用已学习的权重计算上下文,并逐个生成最可能出现的下一个Token。通过不断重复此过程,模型能够生成自然流畅的回答。
而公开了“已学习权重”的模型即为开放权重模型。用户可以在自己的电脑或服务器上运行这些模型,甚至根据需求进行额外训练(微调),打造专门针对特定业务的AI,或进行个性化调整。这意味着无需从零开始构建AI,而是基于已有模型进行定制,例如调整以适应自家产品名称、行业专用术语或固定的回答风格。
此外,在本地环境或自有服务器运行AI,避免了将机密数据发送到外部服务器,增强了数据隐私保护,同时在处理大量任务时也可能降低成本。
开放权重模型与开源AI的区别
不过,仅仅公开权重并不意味着该模型就是“开源AI”。不同模型在学习数据、训练代码、开发过程、许可条件等方面的公开程度和使用权限各不相同。
开放权重模型和“开源AI”常被混淆,但两者应区别对待。部分开放权重模型接近开源AI,但也有模型虽然公开了权重,却对商业使用或再分发有限制。