生产环境中的AI代理:可观测性与评估

随着AI代理从实验原型走向实际应用,理解其行为、监控性能并系统地评估输出变得尤为重要。
学习目标
完成本课后,您将掌握:
- 代理可观测性和评估的核心概念
- 提升代理性能、降低成本和提高效率的技术
- 系统化评估AI代理的方法和内容
- 控制AI代理上线部署成本的策略
- 如何为基于微软代理框架构建的代理添加监控工具
本课旨在帮助您将“黑盒”代理转变为透明、可管理且可靠的系统。
注意: 部署安全可信的AI代理至关重要,建议参考构建可信AI代理课程。
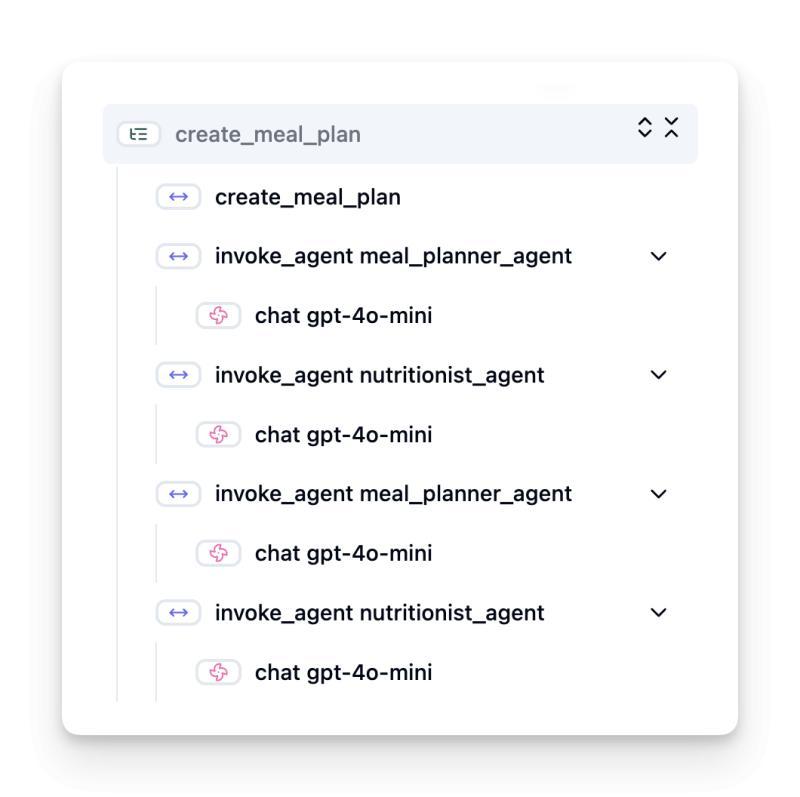
跟踪与跨度
可观测性工具如Langfuse和微软Foundry通常将代理运行表示为“跟踪”和“跨度”。
- 跟踪(Trace):表示从开始到结束的完整代理任务(例如处理用户查询)。
- 跨度(Span):跟踪中的单个步骤(例如调用语言模型或检索数据)。
没有可观测性,AI代理就像“黑盒”,其内部状态和推理过程不透明,难以诊断问题或优化性能。具备可观测性后,代理变成“玻璃盒”,透明度提升,有助于建立信任并确保其按预期运行。
生产环境中可观测性的重要性
AI代理进入生产环境后,面临新的挑战和需求。可观测性不再是“可有可无”,而是关键能力:
- 调试与根因分析:当代理失败或输出异常时,可观测性工具提供必要的跟踪,帮助定位错误源头,尤其是在涉及多个大型语言模型调用、工具交互和条件逻辑的复杂代理中。
- 延迟与成本管理:代理依赖按调用或按token计费的模型和API。可观测性帮助精确追踪调用,识别过慢或过贵的操作,从而优化提示词、选择更高效模型或重设计流程,控制成本并提升用户体验。
- 信任、安全与合规:确保代理行为安全、合规至关重要。可观测性提供代理行为和决策的审计轨迹,有助于检测和防范提示注入、有害内容生成或个人信息处理不当等问题。
- 持续改进循环:可观测性数据是迭代开发的基础。通过监控实际表现,团队能发现改进点,收集微调数据,验证变更效果,形成线上评估与线下实验相结合的反馈闭环,持续提升代理性能。
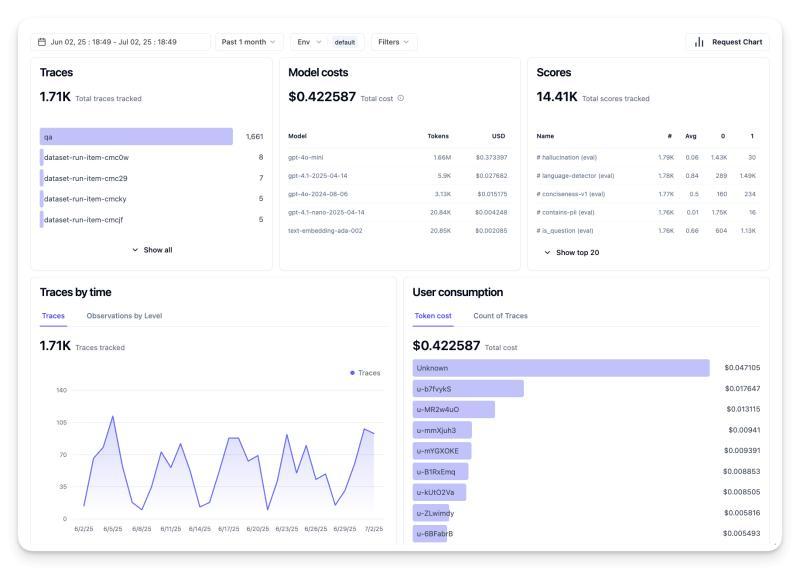
关键监控指标
监控和理解代理行为需要跟踪多种指标,具体指标依代理目标不同而异,但以下指标普遍重要:
- 延迟:代理响应速度,长时间等待影响用户体验。应测量整体任务和各步骤延迟,找出瓶颈并优化。
- 成本:每次代理运行的费用,频繁调用模型或工具会迅速增加成本。实时监控有助发现异常费用峰值。
- 请求错误率:失败请求数量,包括API错误或工具调用失败。可设置重试或备用方案提升鲁棒性。
- 用户反馈:直接评价(评分、评论)提供宝贵信息,持续负面反馈需警惕代理表现异常。
- 隐式用户反馈:用户行为如重复提问、重试等也反映代理效果。
- 准确率:代理输出正确或符合预期的频率,需定义成功标准并通过自动检测或人工标注评估。
- 自动化评估指标:可利用大型语言模型或开源库自动评分,如RAGAS、LLM Guard等。
结合多种指标能全面反映代理健康状况。详见本章示例笔记本。
为代理添加监控
收集跟踪数据需对代码进行监控埋点,目的是生成可被可观测平台捕获、处理和展示的跟踪和指标。
- OpenTelemetry(OTel):业界标准的可观测性框架,提供API、SDK和工具支持数据生成与导出。
微软代理框架原生支持OpenTelemetry,示例代码:
from agent_framework.observability import get_tracer, get_meter tracer = get_tracer() meter = get_meter() with tracer.start_as_current_span("agent_run"): # 代理执行自动被跟踪 pass
本章示例笔记本展示了如何为MAF代理添加监控。
- 手动创建跨度:在自动监控基础上,可手动创建跨度并添加自定义属性(如user_id、session_id、model_version等),丰富调试和分析信息。
Langfuse Python SDK示例:
from langfuse import get_client langfuse = get_client() span = langfuse.start_span(name="my-span") span.end()
代理评估
可观测性提供指标,评估则是分析这些数据和测试结果,判断代理表现并指导改进。由于AI代理非确定性且可能随时间演变,定期评估尤为重要。
评估分为两类:离线评估和在线评估,两者互补,通常先进行离线评估。
离线评估
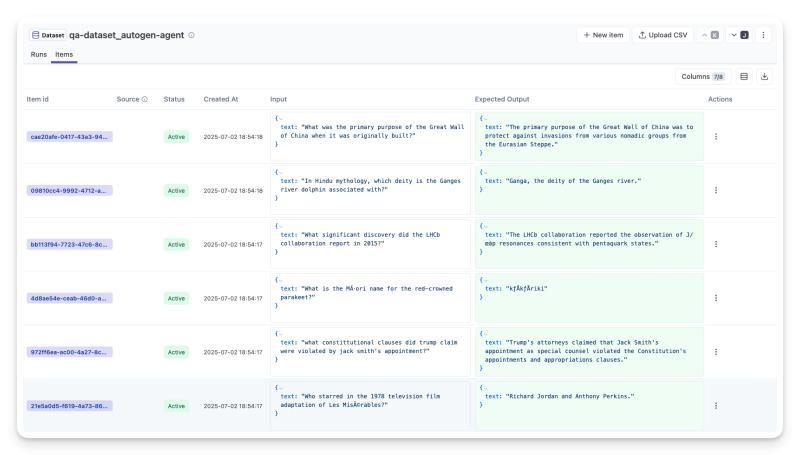
在受控环境下使用测试数据集评估代理,数据集包含已知正确答案。适合开发阶段和CI/CD流程,优点是可重复且有明确准确率指标。
例如,数学题代理可用包含100道题的测试集进行评估。需确保测试集全面且持续更新,覆盖真实场景中的边缘案例。
在线评估
在生产环境中实时监控代理表现,分析真实用户交互数据。优势是捕捉实验室环境难以预见的情况,如模型漂移和异常查询。
通常结合显式和隐式用户反馈,可能采用影子测试或A/B测试。挑战在于获取可靠的实时标签或评分。
两者结合
离线和在线评估相辅相成,在线发现的新问题可用于丰富离线测试集,离线表现良好则可更放心上线并在线监控。常见流程为:
离线评估 -> 部署 -> 在线监控 -> 收集失败案例 -> 更新离线数据集 -> 优化代理 -> 重复循环
常见问题及解决方案
| 问题 | 解决方案 |
|---|---|
| 代理任务执行不稳定 | - 优化提示词,明确目标。 - 任务拆分为子任务,由多个代理协同完成。 |
| 代理陷入无限循环 | - 设定明确终止条件。 - 复杂推理任务使用更强大的推理专用模型。 |
| 工具调用表现不佳 | - 独立测试工具输出。 - 优化工具参数、提示词和命名。 |
| 多代理系统表现不一致 | - 优化各代理提示词,确保差异化。 - 建立路由或控制代理,决定任务分配。 |
可观测性帮助快速定位问题环节,提高调试和优化效率。
成本管理策略
- 使用小型模型:小型语言模型(SLM)适合部分任务,显著降低成本。通过评估系统比较性能,合理分配任务。
- 路由模型:根据任务复杂度路由请求,简单任务用小模型,复杂任务用大模型,兼顾成本和性能。
- 缓存响应:识别常见请求,提前缓存答案,减少重复调用,降低费用。
实践示例
本节示例笔记本演示如何使用可观测性工具监控和评估代理。
更多问题?
欢迎加入微软Foundry Discord,与其他学习者交流,参加答疑时段,解决您的AI代理疑问。


