日本理光公司完成了具备高精度推理能力的多模态大规模语言模型(Reasoning LMM)基础模型“Qwen3-VL-Ricoh-32B-20260227”的开发。该模型能够通过多阶段推理,准确理解包含图表的复杂文档。
该模型基于阿里巴巴云的“Qwen 3.0-VL”,并在日本经济产业省和新能源产业技术综合开发机构(NEDO)推动的国内生成式AI开发力强化项目“GENIAC”第三阶段中开发完成。理光已于2月30日免费公开了“Qwen3-VL-Ricoh-8B-20260227”,并计划随后发布专门用于评估推理性能的理光自研基准测试工具。
多模态大规模模型(LMM)是指能够同时处理文本、图像、音频、视频等多种数据类型的AI技术,支持从截图中提取文本摘要、回答包含图表的问题等多样化数据处理需求。
企业内部文档不仅包含文本,还包括图表、表格和图片,传统的文本搜索难以满足准确检索需求,且仅靠搜索功能难以充分利用文档内容,因此多模态处理技术成为必然选择。

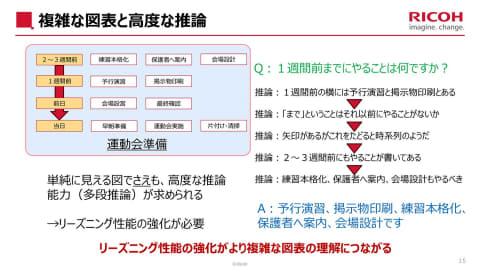
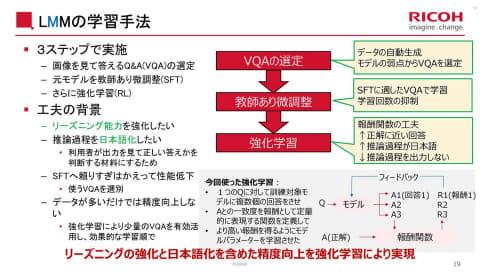
本次开发的“Qwen3-VL-Ricoh-32B-20260227”基于“Qwen3-VL-32B-Instruct”,通过多阶段推理实现对跨页图表的关联理解,能够对高难度阅读理解问题生成高精度回答。强化学习过程中,理光设定了独特的奖励函数,提升学习效率的同时有效抑制过拟合。
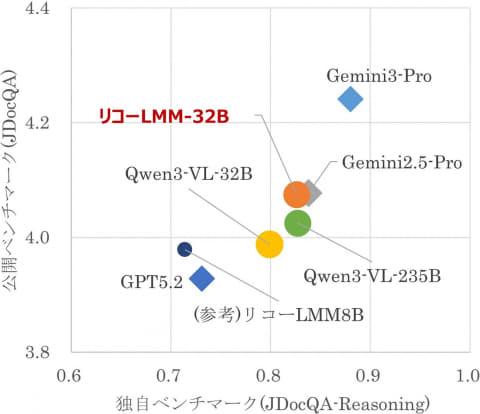
截至2026年2月17日,该模型在基准测试中的表现已达到与大型商业模型如“Gemini2.5-Pro”相当的水平。
此外,针对日本企业的实际应用,理光还致力于将模型的思考过程本地化为日语,这不仅提升了日语文档的读取精度,也使得回答的判断依据和前提条件能够用日语确认,增强了实际业务使用的可信度。
该模型在保持高精度的同时,减少了参数规模,支持部署在企业内部服务器,实现本地化文档的高效利用。模型支持微调,并可提供私有化版本以满足企业需求。
将隐性知识转化为AI可用数据
理光正在强化基于AI的业务信息利用解决方案。企业内部存在大量非“AI-Ready”的信息,如图表中的数据,传统的检索增强生成(RAG)和文本搜索难以找到所需答案。

理光认为,将这些隐性知识转化为人类和AI都能理解的数据,是解决问题的关键。通过开发擅长处理图表的多模态大模型,推动企业私有化应用。
例如,模型能够正确追踪复杂的科学材料流程图,理解提问意图并用日语进行推理回答,也支持跨多页的多个图表读取。
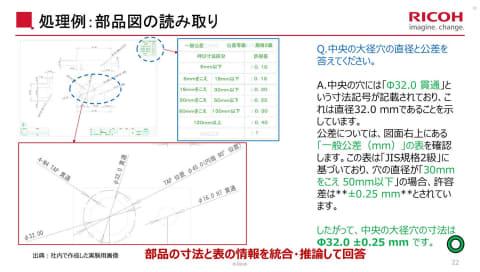
具体应用案例包括读取零件图纸,整合零件尺寸与表格信息进行推理回答。例如,当被问及“中央大径孔的直径和公差是多少?”时,模型能识别图纸中标注的“Φ32.0贯通”尺寸符号,并结合右上角“通用公差(mm)”表中的±0.25mm公差,回答“中央大径孔尺寸为Φ32.0 ±0.25mm”。
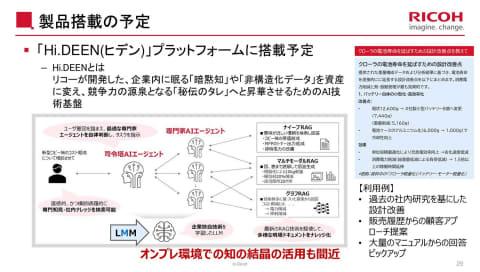
理光计划将该新模型集成到“On-Prem LLM Starter Kit”和“Hi.DEEN(ヒデン)”平台,面向企业市场推广应用。