日本TOPPAN控股株式会社与日本TOPPAN株式会社于7日宣布,成功开发出一款能够解读中世纪希腊语的AI-OCR引擎。未来,他们计划利用梵蒂冈教皇图书馆所藏的希腊语手稿图像及文本数据,持续积累学习数据并提升识别精度,目标实现识别准确率超过95%。
此前,日本TOPPAN一直致力于破解现代人难以辨认的“草书体”古文书。早在2015年,便开始运用AI图像识别技术研发“草书体OCR”,推出了古文书解读与利用服务“ふみのは”,以及方便用户解读古文书的手机应用“古文书相机”。
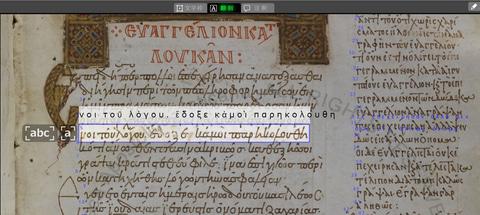
另一方面,中世纪希腊语因时代和书写者不同,字形存在差异,且部分单词会被省略,拼写方式也与现代不同,书写规范不统一。此外,句子中往往没有单词间的空格,使得没有专业知识的现代人难以阅读。
日本TOPPAN此次利用在“草书体”解读中积累的AI-OCR技术和经验,开发出能够识别中世纪希腊语的AI-OCR引擎。通过准备包含百万字级别字形和行数据的数据库,成功实现了对中世纪希腊语文字的解读。
未来,TOPPAN控股将与其运营的印刷博物馆合作,利用梵蒂冈教皇图书馆收藏的约5000件希腊语手稿中的50件(包含约400张IIIF图像)及其翻刻文本作为AI学习数据。这些手稿已附有翻刻和注释等附加信息。
通过高精度的手稿图像与翻刻文本学习,并结合专家的人工校验,TOPPAN将兼顾提升解读准确率与保证质量,加速庞大希腊语手稿收藏的文本数字化进程,力争实现AI-OCR引擎中世纪希腊语文字识别精度超过95%的目标。


