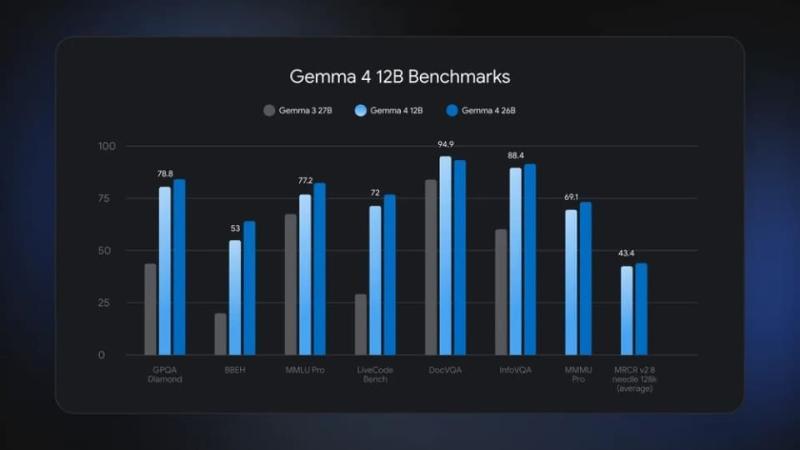
日本Google于6月3日宣布推出集成多模态模型“Gemma 4 12B”,该模型能够在配备16GB VRAM或集成内存的笔记本电脑上顺利运行。
“Gemma 4 12B”定位于支持边缘计算的“E4B”与更高阶的“26B Mixture of Experts(MoE)”之间,兼顾内存使用效率与多功能执行能力。
该模型是首个支持原生音频输入的中等规模多模态模型。以往多模态模型通常通过分别编码图像和音频,再传递给语言模型,但这种分离编码方式会导致延迟增加和内存占用上升。相比之下,“Gemma 4 12B”将图像和音频输入直接送入大型语言模型(LLM)主干,省去了多模态编码器,实现了音频与视觉输入的直接融合学习。
此外,“Gemma 4 12B”在Apache 2.0开源许可下发布,开放且易于访问,获得了开发者生态系统的广泛支持。模型还集成了多标记预测(MTP)功能,有效降低了响应延迟。
在性能测试中,“Gemma 4 12B”表现接近“26B MoE”模型,支持多阶段推理和基于代理的工作流程。