正如我们今年早些时候探讨过的《世界模型》,接下来几周我们将在播客中推出一系列关于CPU计算和沙箱产业的短期专题,正是时候解释背后的原因。
近期有几条重要动态:
- Noam Brown指出:“推理计算是一种战略资源,目前被低估。”
- Sam Altman表示:“在很大程度上,我们现在必须成为一家AI推理公司。”
单独看这些言论似乎是对GPT 5.5模型成功发布的正常反应,但结合背景来看,这标志着一个值得高度关注的转折点,读者们若尚未重视,应当引起警觉。
此次观点的直接触发点是英特尔CEO谭立布在第一季度财报电话会议中公布的CPU计算需求数据(非GPU):
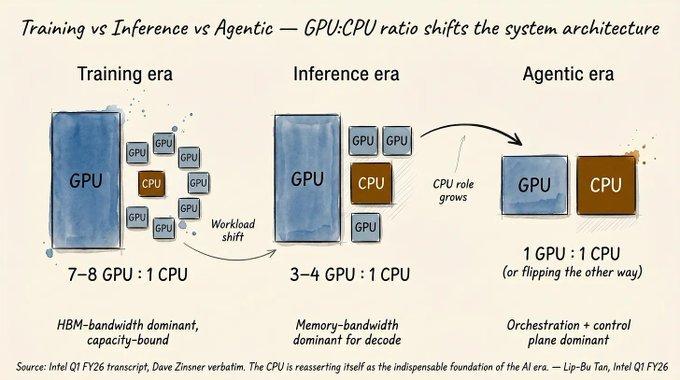
虽然英特尔CEO有激励推动CPU需求增长的动机,但数据并非无据:

我们在《SemiAnalysis》播客中也讨论过这一趋势(经编辑整理):
Doug:我们正处于COVID五到六年刷新周期的尾声。2020-2021年间,CPU采购高达千亿美元级别。通常会有一次大规模芯片更新,但这次大家几乎把所有预算都投入到了GPU上,极力投资AI,而CPU仅做维护性资本支出。讽刺的是,所有Claude Code相关软件都运行在CPU上,预计CPU利用率将持续上升,强化学习等应用也大量依赖CPU模拟软件。虽然规模不及GPU,但趋势明显,我们可能会因刷新周期出现CPU短缺。
swyx:是的,生产代理也需要计算资源,强化学习模型和OpenClaw等都消耗更多计算,虽然增长曲线不同,但方向一致。
Doug:这是一条上升曲线,过去两年在这方面的投资严重不足。
此外,在英伟达GTC大会上,黄仁勋的主题演讲也强调了推理的转折点:
AI现在必须思考、行动、阅读和推理,而这一切都依赖推理计算。推理时代已经到来,所需计算量增长了约一万倍。过去两年,计算需求增长了百万倍,使用量增长了百倍。我们正处于一个正向的良性循环,推理转折点已经到来。
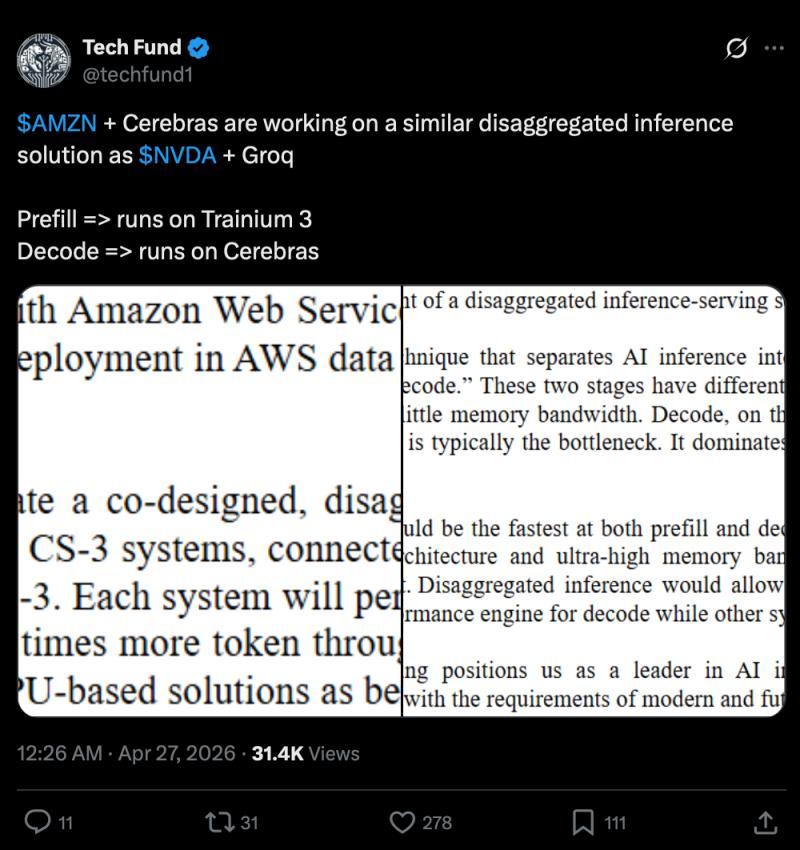
推理转折不仅推动了CPU需求,也重塑了GPU工作负载。预填充/解码分离已成常态,英伟达收购Groq,英特尔与Sambanova合作,亚马逊也加入了类似Cerebras的阵营,OpenAI和Cognition此前已布局此类技术:
以下为2026年4月28日至29日的AI新闻摘要,我们监测了12个子版块、544个Twitter账号,无新增Discord频道。更多内容可访问AINews官网。
AI Twitter综述
编码代理转型为平台:Codex、Cursor SDK与VS Code的升级
- OpenAI正将Codex从编码工具转变为通用工作平台,扩展了持久上下文、工具集成和团队部署,支持研究综合、电子表格和决策跟踪等知识工作。针对企业客户推出了免座位费的Codex专用席位,并新增Supabase和Figma插件集成。
- 性能优化从模型延迟转向代理循环系统工程,OpenAI通过WebSocket模式提升代理工作流速度达40%。VS Code也推出了跨工作区语义索引、跨仓库搜索、聊天会话洞察等功能,强调内存、检索和工具编排的重要性。
- Cursor推出SDK,开放运行时和模型供CI/CD、自动化及产品内嵌代理使用,标志着从基于席位的IDE产品向可编程代理基础设施转变。
代理框架工程、LangGraph/Deep Agents与生产级AgentOps
- 代理框架成为关键优化层,研究显示框架演进可显著提升性能,如Agentic Harness Engineering在十次迭代中将Terminal-Bench 2的pass@1从69.7%提升至77.0%,超越人类设计的Codex-CLI基线。
- LangChain推出Deep Agents产品线,支持模型特定的框架调优和低代码部署,强调开放框架、开放评估和开源模型组合的重要性。
- Cloudflare推进“代理即软件”理念,使代理能够成为Cloudflare客户,自动创建账户、注册域名和启动付费计划,体现供应商开始将业务流程直接暴露给代理。
模型发布与基准测试:Mistral Medium 3.5、Granite 4.1、Ling-2.6及开源模型价格压力
- Mistral Medium 3.5引发热议,被视为128B密集模型,支持本地64GB内存运行,主打企业级可靠性和指令遵循。
- IBM Granite 4.1发布30B、8B、3B三款开源模型,强调开放性和令牌效率,适合企业和边缘部署。
- 开源模型竞争加剧,Ant OSS的Ling-2.6-flash为107B MoE模型,MIT许可,表现优异。腾讯混元发布Hy-MT1.5-1.8B翻译模型,支持33种语言和1056种翻译方向,采用1.25位量化技术。
- 市场价格快速下降,如Qwen 3.5 Plus每百万输出令牌3美元,MiMo-V2.5 Pro在Code Arena表现出色。
推理、内核与MoE系统:FlashQLA、Blackwell上的vLLM、torch.compile及GLM-5服务
- 阿里巴巴推出FlashQLA高性能线性注意力内核,针对小模型、长上下文和张量并行优化,定位于个人设备上的代理AI。
- vLLM与Blackwell协同设计实现显著吞吐量提升,DeepSeek V3.2达到230令牌/秒,支持NVIDIA HGX B300无服务器推理。
- 工程师分享模型与GPU之间的“中间层”细节,torch.compile解析了推理优化路径。John Carmack提醒GPU库性能高度依赖路径,存在显著性能波动。
- Zhipu AI发布GLM-5服务后分析,解决KV缓存竞争和同步问题,预填充吞吐量提升132%。
研究信号:知识探测、Web代理基准、多模态与科学基础设施
- 不可压缩知识探测(IKP)研究显示,基于1400个问题、188个模型和27个厂商的事实知识准确率与模型规模呈强对数线性关系,表明事实知识容量不会随时间压缩,黑盒评估仍能泄露架构规模信息。