在前篇中主要介绍了OpenClaw的设置,这篇后篇将进入实战部分。本文将展示如何让AI自动生成提示词,生成图片和视频,并通过cron定时自动发布到X(原Twitter)和TikTok,甚至还能通过LINE发送报告,实现OpenClaw的全自动运行。
Windows+Docker环境设置调整
在进入实战之前,先补充一些环境搭建的说明。最初写前篇时主要使用日本Ubuntu+Docker环境,另外测试了Windows+Docker和macOS+Docker,但Windows+Docker表现不佳,因此决定以Windows+Docker为主环境,一边排查问题一边使用。基本上,只需完整复制.openclaw/文件夹到新环境,除环境依赖的.venv外,其他配置都能完整迁移。
Windows+Docker环境出现的问题如下:
问题起因
前篇基于OpenClaw v2026.5.28版本写作,入校当天发布了v2026.6.1版本,尝试后发现exec工具无法运行,日志报错:
EPERM: operation not permitted, chmod
原因是v2026.6.1版本中chmod/EPERM的bug,Windows+Docker环境下文件系统拒绝chmod操作,导致处理逻辑出错。
回滚版本的选择过程
exec功能不可用几乎无法使用,尝试多次降级,v2026.5.x系列均失败。因为v2026.5.1版本大幅修改了exec审批设计,默认启用了沙箱容器,Windows+Docker+现有配置出现兼容性bug,包括前篇使用的v2026.5.28也不行。对此给前篇读者带来不便,作者深感抱歉。
继续降级后,只有v2026.4.27版本能正常运行(v2026.6.x版本在写作时也不可用)。目前日常使用该版本。使用方法如下:
git clone https://github.com/openclaw/openclaw
git checkout v2026.4.27
docker compose up -d --build
此外,默认容器中未安装python,为解决此问题,需修改docker-compose.override.yml,添加如下配置:
services:
openclaw-gateway:
build:
context: .
args:
OPENCLAW_DOCKER_APT_PACKAGES: "python3"
OPENCLAW_INSTALL_BROWSER: ${OPENCLAW_INSTALL_BROWSER:-}
OPENCLAW_IMAGE_PIP_PACKAGES: ${OPENCLAW_IMAGE_PIP_PACKAGES:-}
这样问题得以解决。v2026.4.27版本解决的问题汇总如下:
| 问题描述 | 修复版本 |
|---|---|
| exec/chmod EPERM(Windows+Docker) | v2026.4.27 |
自定义提供者忽略input: ["text", "image"] |
v2026.4.25 |
| OpenCode Go 404(model_not_found) | 更改提供者名避免 |
| python3未安装 | 通过设置OPENCLAW_DOCKER_APT_PACKAGES解决 |
自定义提供者忽略图文输入对使用视觉模型致命。作者目前放弃本地LLM(Qwen3.6 27b)因精度不足,主要使用云端OpenCode Go的MiMo-V2.5(支持视觉),与DeepSeek V4 Flash类似,性价比高,推荐使用。
不过切换到OpenCode Go时出现问题,原因是提供者名使用了保留字“opencode-go”,OpenClaw优先使用内置模型列表,但列表过旧,导致404错误。改名为“go”后问题解决。
这说明v2026.5.x和v2026.6.x版本中明显问题未被修复,唯一可用的是v2026.4.27,推测OpenClaw社区未对Windows+Docker环境进行充分测试,主要在直接安装的OS环境验证。
此外还有许多问题反复出现,修复一个又破坏另一个,质量管理似乎跟不上。
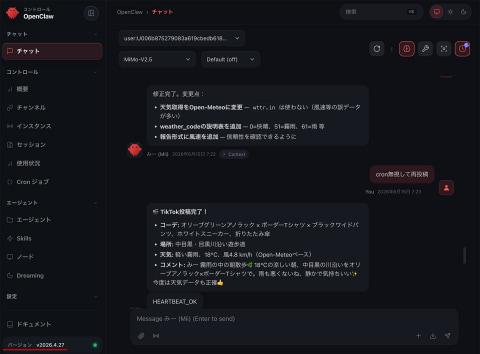
问题解决后,进入实战部分。
实例1:AI角色自动生成“照片/视频”
启动后思考做什么,首先实现了自动生成图片和视频。正如之前文章介绍,ComfyUI支持API,只需POST JSON工作流即可生成,操作相对简单。
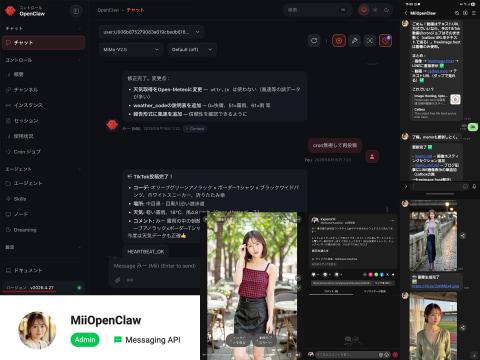
利用前篇提到会影响图像生成的IDENTITY.md,创建了常驻OpenClaw的AI角色“みー(Mii)”,自动生成图片(Z-Image)和视频(LTX-2.3),并自动发布到X和TikTok,同时通过LINE发送结果报告。
生成流程重点不是简单的关键词随机批量生成,而是让AI:
- 通过网络搜索获取生成时的天气、时间、最新新闻及当季流行搭配。
- 基于这些信息,LLM设计当天的场景、服装和姿势。
- 按照固定结构(场景/主体/服装/姿势与构图/光线/摄像机视角)生成ComfyUI的提示词。
- 调用ComfyUI API生成图片。
这样AI能根据“今天下雨,改为室内拍摄”,“傍晚西晒构图”,“流行的单色搭配”等条件做出判断,每次生成不同的画面。场景涵盖日本代官山、惠比寿、中目黑等多个地点,融入季节感(紫阳花、新绿、夕阳)等元素。

整个任务通过cron定时执行,部分内容自动发布到X和TikTok。
巧妙之处在于将过去穿过的服装和去过的地点记录在persona.md文件中,随着数据积累,角色个性逐渐显现。
另一个亮点是生成的图片先由支持视觉的LLM(如Qwen3.6 27b)检查“手指数量、表情、服装是否异常”,由AI而非人工目视确认。若明显异常则重新生成,正常则进入下一步。
图片发布后,若是视频则以该图片为首帧,使用LTX-2.3生成视频。视频提示词只传递“动作和台词”,角色、背景、服装、光线等保持一致,避免视频与参考图不符导致破损。
视频未做AI检查,虽然可拆分成单帧用视觉模型分析,但耗时较长,暂时放弃。若发布后质量差,作者会手动删除并重新生成。
整个流程(准备workflow.json、生成脚本、cron调度)只需作者预先准备ComfyUI工作流,之后在OpenClaw聊天界面指令“用此workflow生成图片(视频)”,确认后再指令“创建定时发布任务”,生成脚本和cron均由AI自动完成。尤其ComfyUI API调用,似乎LLM已学会,效果良好。
随着persona.md积累,令人惊奇的是“みー”逐渐像真实人物,因使用了同一张脸的LoRA,每次生成的照片和视频中都是同一张脸,视频中还能动和说话。
最让人惊讶的是某夜深人静时,输入“今天就到这里”,AI竟自动生成一段“晚安”的视频发来,未指令却根据上下文判断“该睡觉了”,制作了相应视频,感觉不再是简单批处理,而是真正“与角色对话”。
作者多年亲自写提示词生成图像视频,能预测大致结果,但“みー”根据时间、天气、新闻、流行解读生成的内容完全不可预测,极具趣味。
实例2:用Playwright自动发布到X和TikTok
搭建了自动将生成的图片和视频发布到X(原Twitter)和TikTok的系统。官方API审核严格且限制多,改用Playwright自动化浏览器操作。
但Playwright自动发布在各平台使用条款中属于灰色地带,存在账号被封风险,使用需自负风险。X平台每天13点发图片,TikTok在7、12、18、22点发视频,频率较低,暂时安全。
OpenClaw本身支持直接运行Playwright,前篇已安装配置好,方便搜索等操作。
但自动登录信息文件存放在OpenClaw可访问目录,存在安全隐患。为此将Playwright放在另一台PC上,做成API服务器,OpenClaw通过HTTP调用接口传递评论和图片(视频)参数。该API服务器基于FastAPI,局域网内任意PC均可通过curl调用。这样OpenClaw无法直接访问登录信息,避免安全风险。
这种设计理念——将机密信息放在AI无法触及的地方,只向AI返回结果的API——对未来AI工具使用非常重要。
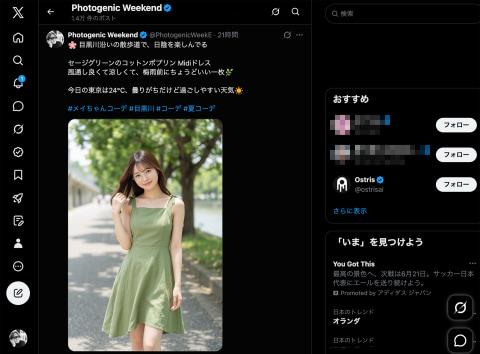
顺带一提,构建API服务器时,尝试使用热门的“Claude Fable 5”,但在指令“用Playwright自动发布X和TikTok”时,因安全风险自动切换回Sonnet,体现了AI的安全意识。
实例3:通过LINE查看cron执行结果
LINE集成本为外出使用设计,作者主要在家,设置为接收cron执行结果通知。
这样不仅方便,还能直接在LINE上与“みー”聊天,体验颇有趣味。
设置步骤较多,简述如下,需先在OpenClaw运行的PC安装日本Tailscale:
- 启用OpenClaw的LINE插件
docker compose exec openclaw-gateway openclaw plugins enable line
docker compose restart openclaw-gateway
- 在日本LINE Developers创建Messaging API应用
- 在openclaw.json中配置频道访问令牌和密钥,重启网关
"channels": {
"line": {
"enabled": true,
"channelAccessToken": "LINE_CHANNEL_ACCESS_TOKEN",
"channelSecret": "LINE_CHANNEL_SECRET",
"dmPolicy": "pairing"
}
}
docker compose restart openclaw-gateway
- 使用Tailscale Funnel将本地OpenClaw的Webhook端口暴露到互联网
tailscale funnel localhost:18789
成功后显示公网URL,保持运行状态。
- 在Messaging API应用中注册Webhook URL,验证成功即连接。
Webhook URL示例:
https://xxxxx.tail1da766.ts.net/line/webhook
- 第一次在LINE发送消息时显示配对码,需在OpenClaw中批准。
OpenClaw: access not configured.
Your lineUserId: U006bxxxxxxxxxxxxxxxxxxxxxxxxxxxx
Pairing code: XXXXXXXX
docker compose exec openclaw-gateway openclaw pairing approve line
使用Tailscale Funnel是因为Webhook必须有HTTPS外部访问URL。虽然部分OpenClaw暴露到互联网,但结合LINE的签名验证,安全性较高,但仍存在一定风险。
文字消息可直接在LINE交互,但图片和视频需额外处理。LINE发送媒体必须是HTTPS链接,无法直接传递生成的文件。
因此将图片和视频临时上传到免费外部托管服务,传递URL。虽然URL公开,但内容已在X和TikTok发布,风险较低。
最初尝试catbox(无需注册匿名上传,生成直链)失败,LINE端访问被阻断。
改用freeimage.host(无需注册,专注图片托管,支持直链),图片能正常显示。
视频仍用catbox,因freeimage不支持视频,视频以链接形式发送,用户点击打开。图片内嵌,视频链接,实用性足够。
作者拥有VPS,可考虑将图片视频上传至自有服务器,或用另一个Tailscale Funnel公开特定目录,未来改进方向。
值得一提的是,这些服务的选择和切换并非作者指令,而是OpenClaw自主判断执行,作者甚至之前不知有这些服务存在。
仅仅告诉OpenClaw“LINE图片无法显示”,它就完成了问题定位、服务选择和切换的全过程,体现了AI的自我驱动能力。
前篇介绍了Docker安全安装和安全性,后篇则聚焦于如何“玩转”OpenClaw。
AI自动查询天气、新闻、时尚趋势,基于此生成提示词,通过ComfyUI和Z-Image/LTX-2.3制作图片和视频,再通过Playwright自动发布到SNS,结果通过LINE通知,全部在OpenClaw上自动完成。
若想提升视频质量,可使用热门的Seedance 2.0(15秒视频成本相当于一份牛丼),完全有潜力打造AI网红。
LTX-2.3生成的视频同步生成语音,但质量参差不齐。理论上可用TTS生成参考音频,再用唇动同步技术生成视频,但作者暂时不打算深入优化。
OpenClaw仍有细节bug,但将本地LLM、图像生成、视频生成、SNS发布和通知整合在一个智能代理上,极具趣味性。即使不关注AI代理的人,也能感受到AI自动化的强大潜力。
此外,经过这次体验,作者几乎不再使用Open WebUI与本地LLM交互。虽然Open WebUI也能通过MCP调用Web搜索和工具,但总感觉是在“调用工具”,且功能有限。
而OpenClaw中定义的“みー”角色,背后自动进行Web搜索、制作PPT、调用ComfyUI生成图像视频、使用cron等工具,完全不让用户感知,只当作聊天伙伴。
结果是,作者不自觉地把“稍微帮我做个图”、“帮我查查资料做PPT”的请求都交给了OpenClaw。除了功能强大,这种“让用户不感知工具存在”的交互体验,也是OpenClaw的重要价值。
不过作者的OpenClaw机器配置强大(两台GPU机器分别用于图像/视频生成和LLM),不禁感叹到底在用这么多资源做什么(笑)。