你以为“模型越大越慢”是天经地义,其实很多时候,大模型是在浪费算力生成那些小模型也能轻松猜中的词。推测解码做的事很简单:把这些无聊又昂贵的步骤外包给一个更便宜的“草稿工人”,再让大模型做最后审核。结果就是,在不牺牲输出质量的前提下,延迟直接砍半,吞吐翻倍。
Google 已经在 AI 概览中大规模使用推测解码,为超过十亿搜索用户提供服务。
Anthropic、Meta 以及大多数主流推理服务商,也都在生产环境里用类似方案,把每秒令牌处理速度提升到原来的 2-3 倍,而且输出在数学意义上与只跑大模型完全一致。
有用户反馈:在接入推测解码后,同一台 GPU 上的 QPS 提升了约 1.8 倍,用户主观感受是“回答突然变得跟本地应用一样快”,而模型版本和参数量完全没变。
我们在 LLMOps 课程中系统讲过预填充、解码、KV 缓存、推测解码和批处理等推理机制 →
这个思路其实来自 CPU 架构里的“分支预测”:一个小型草稿模型提前生成一串候选令牌,大模型再用一次前向传播统一验证。经验上,60%-80% 的草稿令牌会被接受,而成本只相当于大模型的一小部分推理开销。
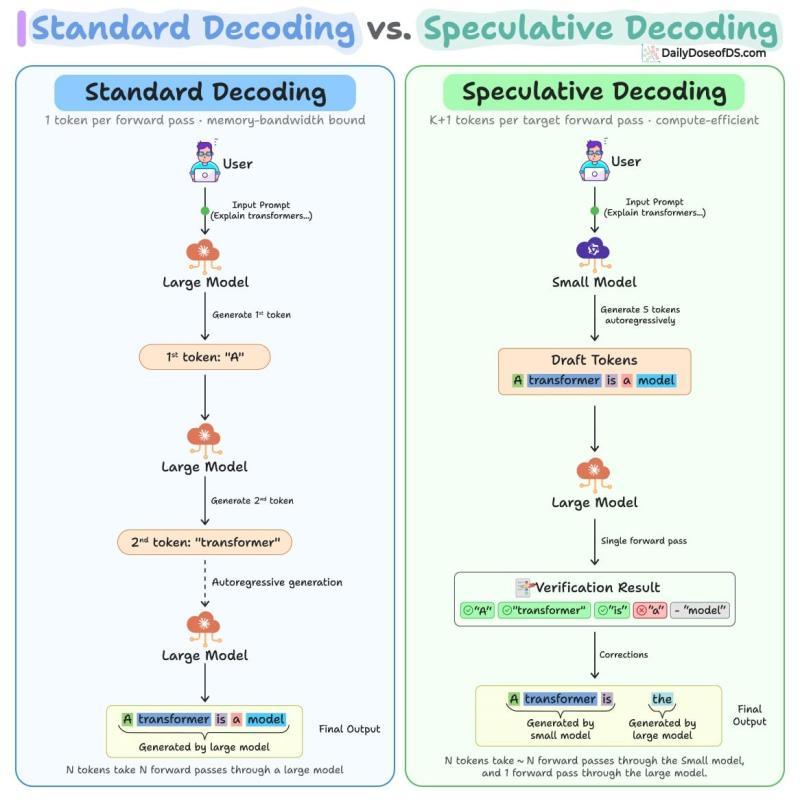
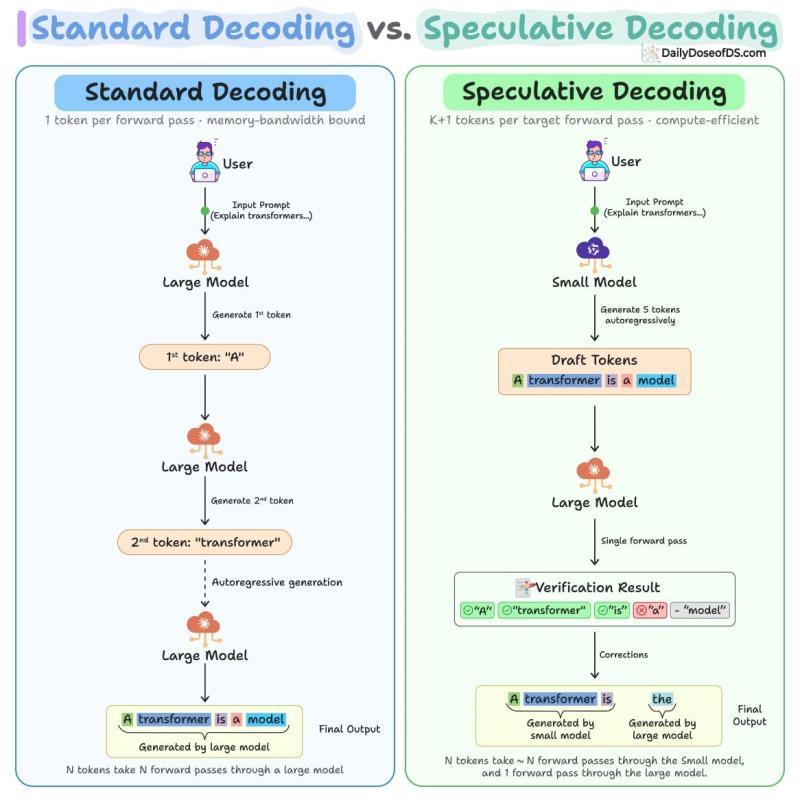
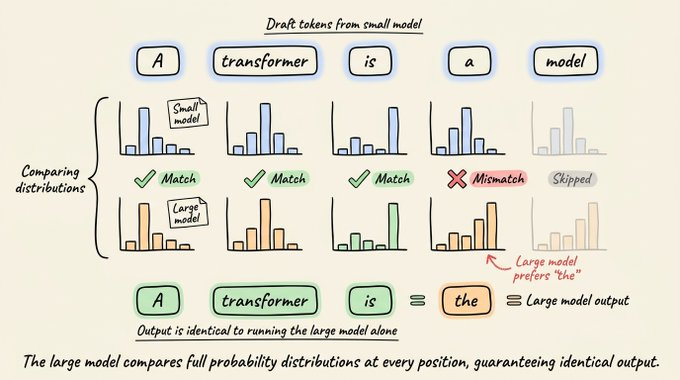
下图直观展示了推测解码与标准解码的差异:
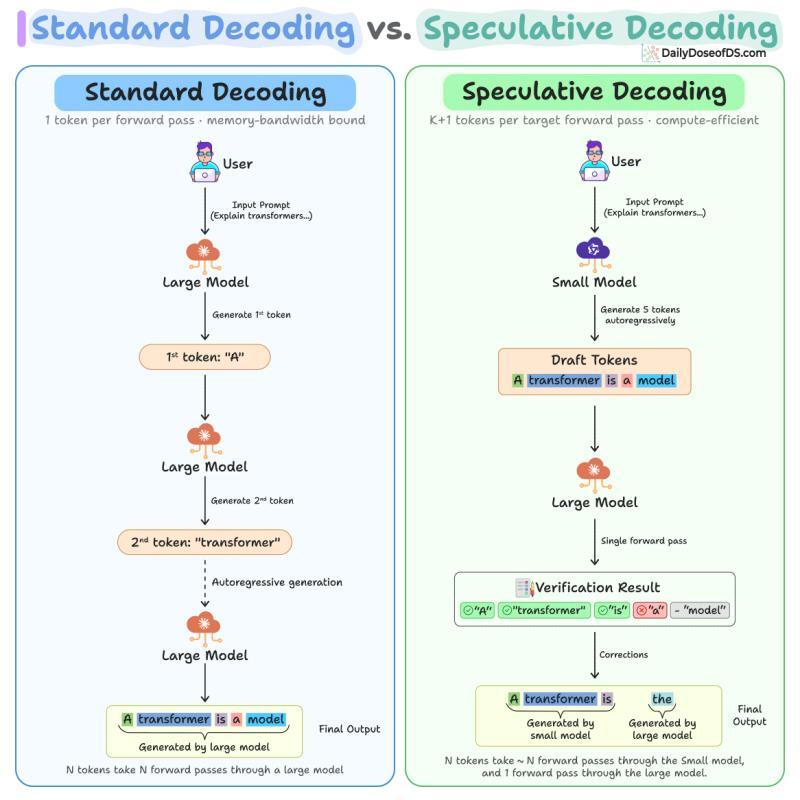
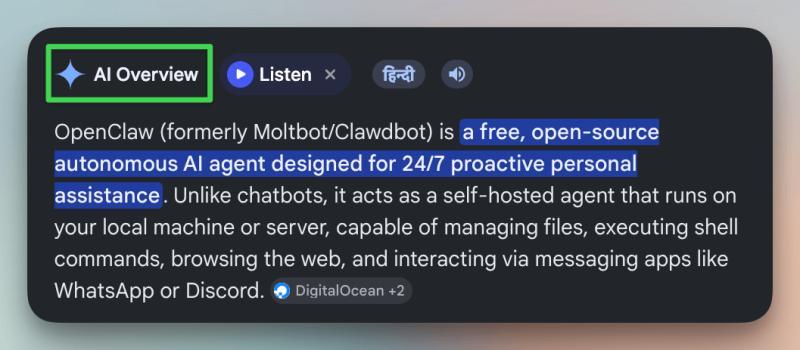
接下来,把它拆开讲清楚:它到底解决了什么瓶颈,内部怎么运转,代码层面如何落地,以及在真实生产环境里有哪些坑和权衡。
问题所在:大模型在“搬砖”,不是在“思考”
一个 700 亿参数的模型,如果用 FP16 存储,大约需要 140GB GPU 显存。单看这个数字就知道,它的主要成本根本不在算,而在“搬数据”。
在解码阶段,每生成一个新令牌,都要做一次完整的自回归前向传播:把这 700 亿参数从显存里读出来,再跑一遍计算图。也就是说,每个令牌都要把整座“参数大山”搬一次。
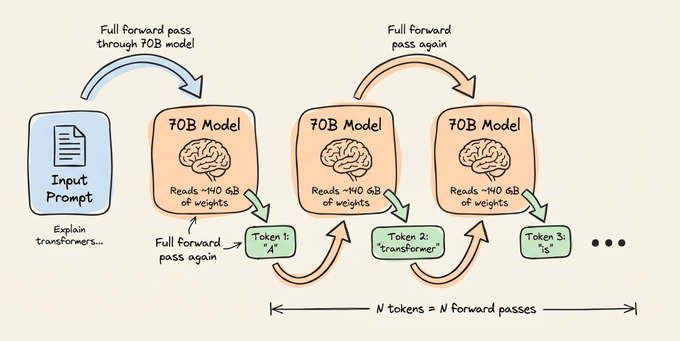
以 H100 为例,它的显存带宽大约是 3.35 TB/s。单纯把 140GB 权重搬一遍,就要大约 42 毫秒,这还没算上其他开销。数据显示,在很多在线服务场景里,延迟瓶颈更多卡在内存带宽,而不是算力本身。
更扎心的是,大模型每步生成的很多令牌,其实是非常常见、非常可预测的词,比如 “the”、“is”、“of” 这类高频词。哪怕是 5 亿参数的小模型,也能在绝大多数上下文里把它们猜对。
可现实是,你仍然要为这些“简单词”付出读取 140GB 权重的全部成本,而一个 100 倍更小的模型,可能几毫秒就能搞定同样的预测。这种算力浪费,在高并发场景下会被放大得非常夸张。
推测解码,就是抓住了这个“简单令牌不该用大炮打”的观察,把大模型从重复劳动里解放出来。
推测解码的工作原理:小模型写草稿,大模型做审稿
本质上,推测解码就是:让小模型负责大部分生成,大模型只做“审核 + 兜底”。
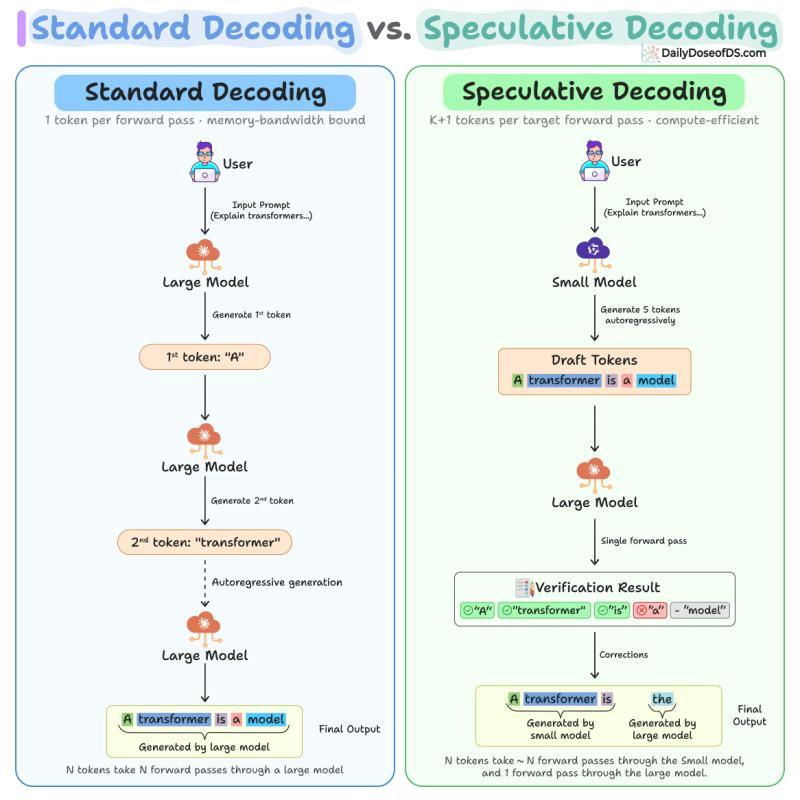
小模型先写一段,大模型一次性验收
流程可以拆成三步:
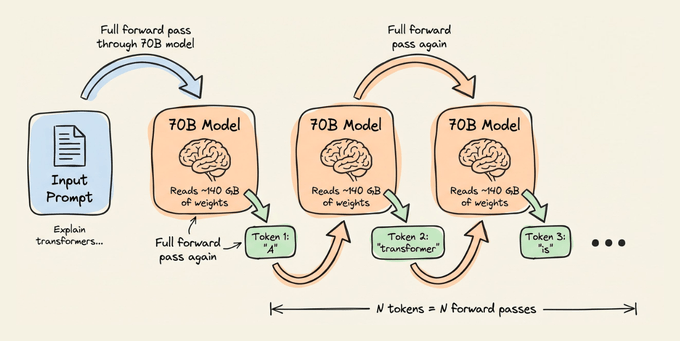
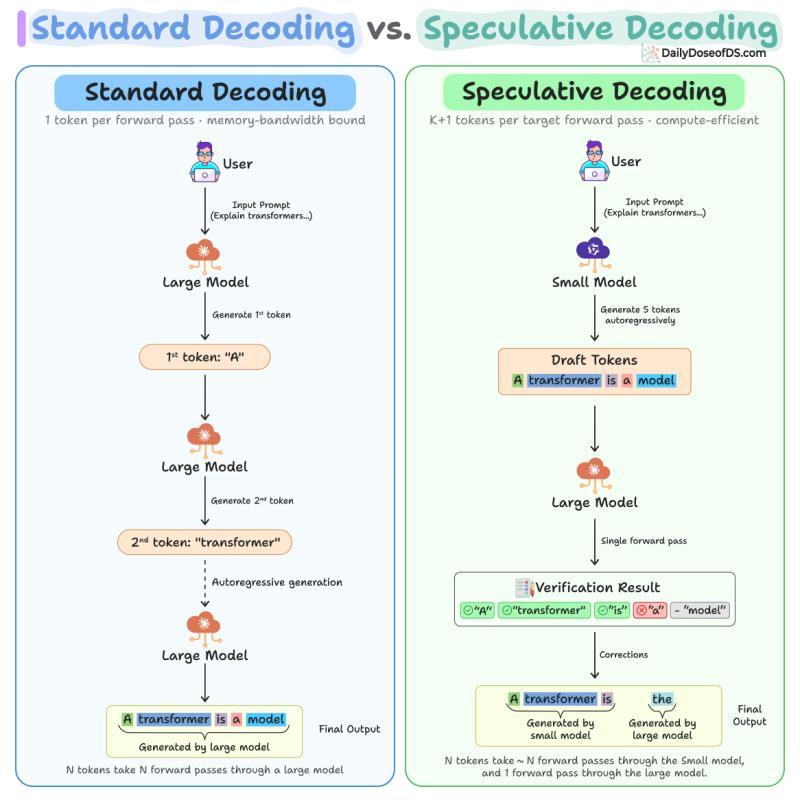
- 小模型(例如 Qwen2.5 0.5B)自回归生成一小段草稿,比如 5 个候选令牌。因为它比目标模型小 100 倍,生成这 5 个令牌的成本,大约只相当于大模型一次前向传播的 1%-2%。
- 大模型(例如 Qwen2.5 7B)随后在一次前向传播中处理这 5 个草稿令牌,对每个位置都算出完整的概率分布。草稿模型在生成时也会算自己的分布,两者可以一一对比。
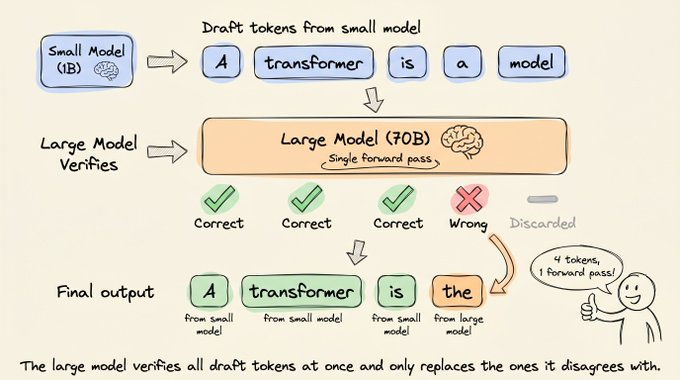
- 验证时按顺序检查草稿:如果大模型同意令牌 1、2、3,但在令牌 4 上给出不同预测,那么 1-3 直接接受,令牌 4 用大模型的预测替换,令牌 5 被丢弃,不再继续评估。
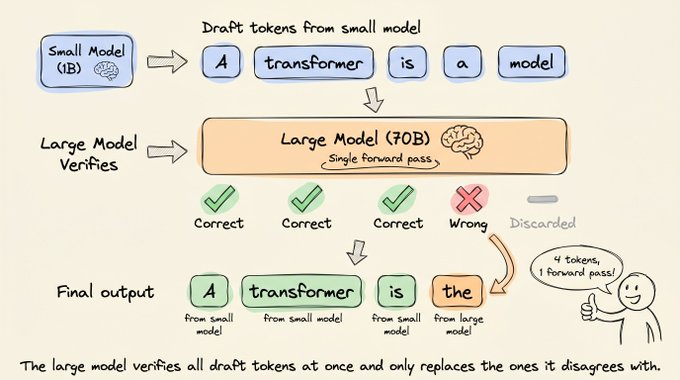
理想情况下,5 个草稿令牌全部被接受,再加上大模型在这次前向传播中额外预测的 1 个新令牌,一次大模型前向传播就能产出 6 个令牌。极端坏情况是 5 个草稿全被拒,只留下大模型自己的 1 个令牌,等价于标准解码。
坏情况的成本会略高于直接用大模型,因为你还多跑了一次小模型,但据公开实验数据,这种情况出现频率很低,整体收益仍然明显偏正向。
为什么输出“数学上完全一致”?
很多人会担心:既然小模型参与了生成,会不会改变大模型原本的输出?
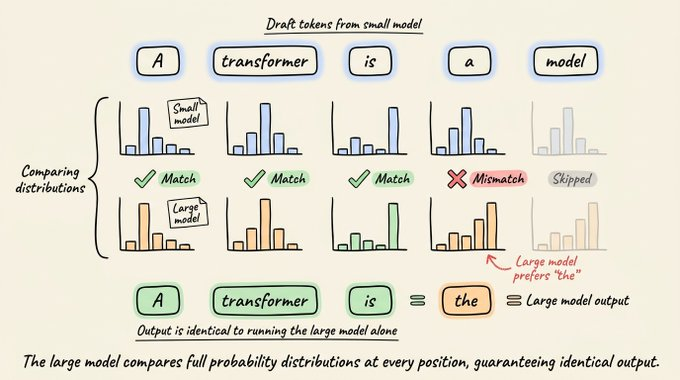
关键点在于:
- 大模型在验证阶段,并不是只检查“草稿令牌看起来像不像话”,而是对每个位置都计算完整的概率分布。
- 只有当大模型在某个位置上,给出的最高概率令牌与小模型一致时,这个草稿令牌才会被接受。
- 一旦大模型在某个位置给出不同的最高概率令牌,就立刻用大模型的结果替换,并停止继续接受后续草稿。
所以,最终输出的每一个令牌,要么是大模型亲自生成,要么是大模型在“我也会选这个”的前提下批准的。只要采样策略(比如温度、top-k、top-p)一致,输出分布就与只跑大模型完全一致。
这个“输出分布不变”的特性,是推测解码能在大厂生产环境落地的关键门槛之一。
代码实现:在 Transformers 和 vLLM 里开箱即用
Hugging Face Transformers 已经在 generate() 中原生支持推测解码,只需要多传一个 assistant_model 参数。
1) 加载目标模型和草稿模型
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch, time
target_id = "facebook/opt-6.7b"
draft_id = "facebook/opt-125m"
tokenizer = AutoTokenizer.from_pretrained(target_id)
target = AutoModelForCausalLM.from_pretrained(target_id, torch_dtype=torch.float16, device_map="auto")
draft = AutoModelForCausalLM.from_pretrained(draft_id, torch_dtype=torch.float16, device_map="auto")
目标模型(6.7B)是你真正关心输出质量的那一个。草稿模型(125M)则是快速又便宜的候选生成器。两者都来自 OPT 系列,分词器完全一致,这样验证时可以直接在令牌 ID 级别对齐,不需要额外转换。
2) 设置流式输出和输入提示
from transformers import TextStreamer
streamer = TextStreamer(tokenizer, skip_special_tokens=True)
prompt = "Explain how a transformer model processes input tokens step by step."
inputs = tokenizer(prompt, return_tensors="pt").to(target.device)
TextStreamer 会在生成过程中逐令牌打印到控制台。用标准解码时,你会看到令牌一个一个往外蹦;启用推测解码后,往往会看到一小段一小段地“成批”出现,那就是一批草稿被整体接受的效果。
3) 基线:只用大模型的标准解码
t0 = time.perf_counter()
base_out = target.generate(**inputs, max_new_tokens=200, do_sample=False, streamer=streamer)
base_time = time.perf_counter() - t0
print(f"\n⏱ Without Speculative Decoding:")
print(f" Runtime: {base_time:.2f}s")
print(f" Token speed: {len(base_out[0]) / base_time:.1f} tok/s")
这里跑的是最常见的贪婪解码,每生成一个新令牌,都要做一次完整前向传播。对 6.7B 这种体量的模型来说,GPU 每步都要搬运十几 GB 的权重。
4) 启用推测解码(6.7B + 125M)
t0 = time.perf_counter()
spec_out = target.generate(
**inputs, max_new_tokens=200, do_sample=False,
assistant_model=draft,
streamer=streamer,
)
spec_time = time.perf_counter() - t0
print(f"\n⏱ With Speculative Decoding:")
print(f" Runtime: {spec_time:.2f}s")
print(f" Token speed: {len(spec_out[0]) / spec_time:.1f} tok/s")
print(f" Speedup over standard decoding: {base_time / spec_time:.2f}x")
唯一的变化就是加上 assistant_model=draft。背后发生的事是:125M 模型自回归生成大约 5 个草稿令牌,6.7B 模型一次前向传播验证这 5 个令牌,接受的直接输出,第一个被拒的用 6.7B 的预测替换,然后继续循环,直到生成 200 个新令牌。
下方视频演示了这个过程的直观效果:
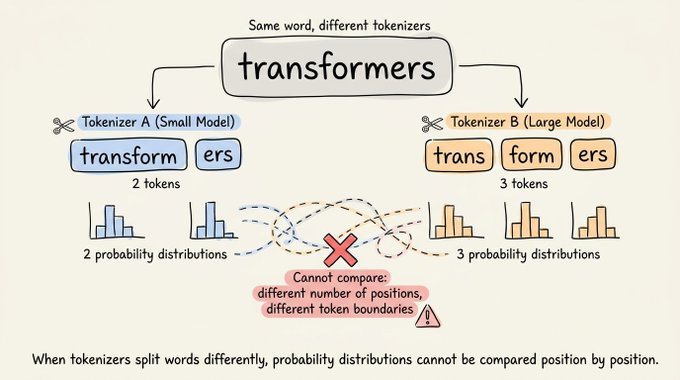

- 左侧是标准解码(每步一个令牌),右侧是推测解码,两边用的都是同一个 6.7B 目标模型。
- 推测解码那一侧会一块一块地吐出文本,整体完成时间大约是标准解码的一半,实测速度提升约 1.9 倍。
在生产环境中,很多团队会直接用 vLLM 这类高性能推理引擎,它已经支持草稿模型、EAGLE、n-gram 和 MTP 等多种推测解码方案:
from vllm import LLM, SamplingParams
llm = LLM(
model="Qwen/Qwen2.5-72B-Instruct",
speculative_model="Qwen/Qwen2.5-0.5B-Instruct",
num_speculative_tokens=5,
tensor_parallel_size=4,
)
outputs = llm.generate(["Explain speculative decoding."],
SamplingParams(temperature=0, max_tokens=256))
我自己在本地 2×A100 上试过类似配置,交互式问答场景下的首 token 延迟和整体响应时间,都能肉眼可见地缩短,体验差异非常直观。
分词器限制与 UAG:不同家族模型也能“搭伙”
为什么传统上必须共享分词器?
传统推测解码有一个隐性前提:目标模型和草稿模型要共享同一个分词器。
原因很直接:
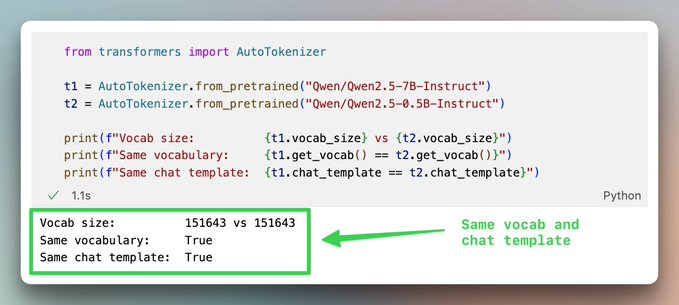
- 验证步骤需要比较两个模型在“同一位置、同一令牌”上的概率分布。
- 如果分词器不同,同一个词可能被拆成不同数量的令牌,甚至边界完全不一样。
- 这会导致概率分布落在不同的令牌空间和位置上,没法一一对齐,自然也就没法直接比较。
这就把推测解码锁死在“同系列模型”内部,比如 Llama 3.2 1B 搭 Llama 3.1 70B,或者 Qwen2.5 0.5B 搭 Qwen2.5 72B。
更微妙的是,即便是同系列模型,有时也会因为聊天模板等配置差异,被框架判定为“分词器不兼容”。比如 Qwen2.5-7B-Instruct 和 Qwen2.5-0.5B-Instruct 虽然词表一样,但聊天模板不同,Transformers 会直接报 tokenizer mismatch。
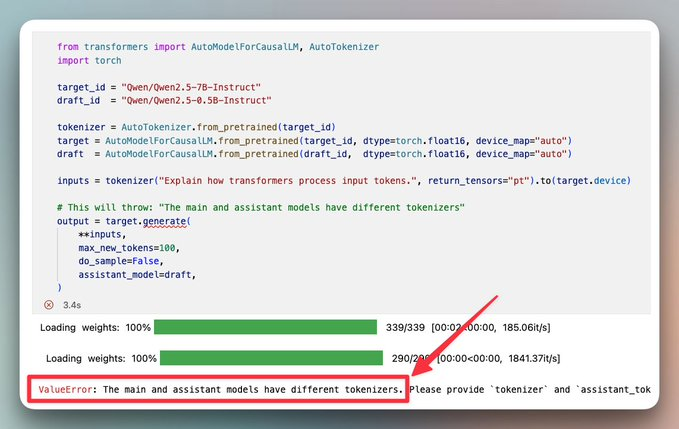
UAG:通用辅助生成打破“同家族”限制
2024 年 10 月,Hugging Face 在 Transformers 4.46 中发布了通用辅助生成(Universal Assisted Generation,UAG),把这个限制基本打碎了。
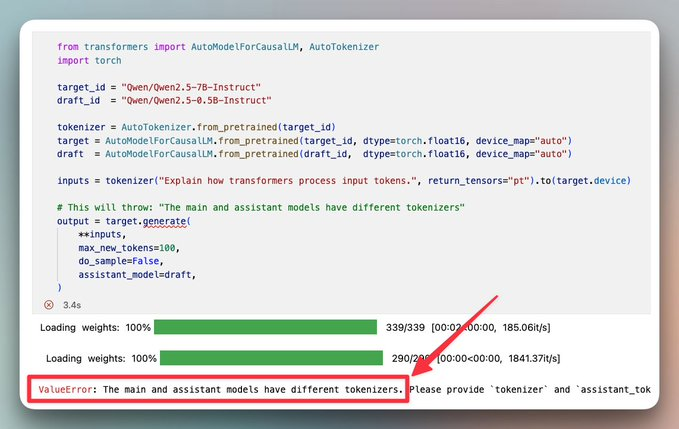
UAG 在底层做了几件事:
- 先把小模型生成的令牌解码回文本字符串。
- 再用大模型自己的分词器重新编码这段文本。
- 然后通过最长公共子序列(LCS)之类的算法,对齐两个分词结果中的“可比部分”。
这样一来,几乎可以任意配对两个模型,不管分词器是不是同一套。比如可以用 Qwen 的小模型给 Gemma 的大模型打草稿,这在以前是很难做到的。
代价也很现实:
- 对于分词器完全一致的模型对,速度提升通常在 1.5-3 倍之间。
- 对于跨分词器的模型对,因为要多做一次解码 + 重新编码,实际加速一般在 1.5-1.9 倍之间。
我注意到一个小细节:即便是同系列的 Instruct 变体(比如 Qwen2.5-7B-Instruct 和 Qwen2.5-0.5B-Instruct),Transformers 也会因为聊天模板不同而走 UAG 路径。用基础模型替代 Instruct 版本,往往能回到更快的“原生路径”。这只是我自己的观察,不排除后续版本会优化这个行为。
生产中的关键权衡:草稿模型多大合适?温度开多高?
推测解码听起来很香,但一落地就会遇到两个现实问题:草稿模型选多大,采样温度设多高。
草稿模型越大越好吗?
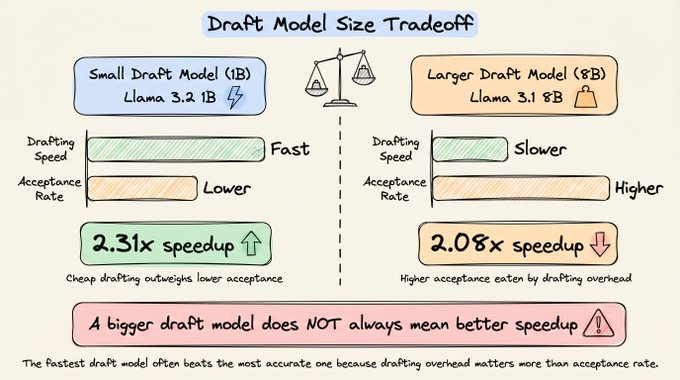
直觉上,草稿模型越大,预测就越接近目标模型,草稿令牌的接受率也会更高。但有一组公开数据挺有意思:
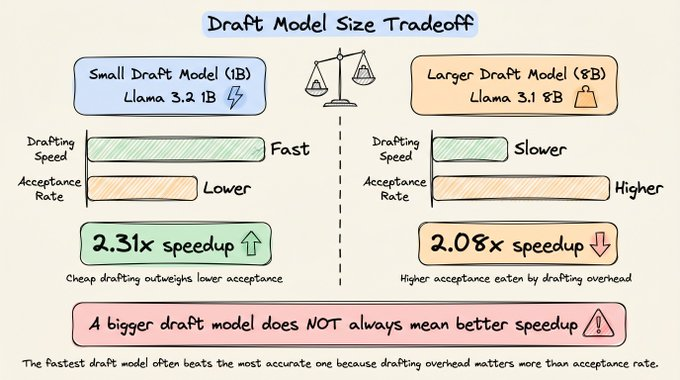
- 用 Llama 3.2 1B 作为 Llama 3.1 70B 的草稿模型,整体速度提升约 2.31 倍。
- 换成 Llama 3.2 8B 做草稿,接受率确实更高,但整体速度反而只有 2.08 倍。
原因很直接:
- 草稿模型越大,自身的前向传播越慢,草稿阶段的延迟变重。
- 接受率的提升并不足以抵消草稿阶段新增的开销。
所以在生产里,常见做法是:
- 目标模型 70B 左右时,草稿模型多在 0.5B-2B 之间。
- 更大的草稿模型,更多是为了极致质量或特殊场景,而不是单纯追求速度。
温度对速度的影响:创意越强,收益越低
采样温度也会明显影响推测解码的收益:
- 当温度接近 0(贪婪解码)时,两边模型的预测更集中在最高概率令牌上,更容易达成一致,草稿接受率最高。
- 温度升高后,概率分布变平,模型更愿意“冒险”选次优令牌,两边分歧增多,草稿被拒的比例上升。
结果就是:
- 在搜索、问答、代码补全这类偏确定性的任务上,推测解码的加速效果通常非常可观。
- 在高温度、强调创造性的写作场景里,速度提升会明显打折扣,有时甚至不如直接用大模型来得稳定。
关于温度如何影响 LLM 行为,我们在另一篇文章里做了更细的拆解 →
有一位做 AI 写作工具的朋友跟我说,他们在高温度(0.9 左右)下尝试推测解码,发现用户主观体验的“创意度”没变,但延迟提升远低于预期,最后只在低温度的改写、纠错等功能里启用了这项优化。
无需小模型的推测解码:把草稿能力“焊死”在大模型里
两模型方案虽然简单,但也有两个明显痛点:
- 需要一套同系列的小模型,才能拿到更好的加速比。
- 小模型本身也要占用额外的 GPU 显存和部署复杂度。
于是,研究界和工业界开始探索:能不能只用一个大模型,就把“草稿能力”内嵌进去?下面几种方案,都是围绕这个问题的不同解法。
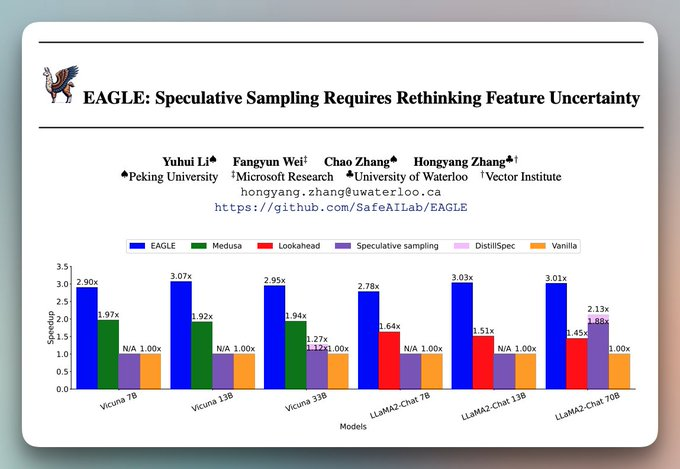
1) EAGLE:在大模型上挂一个轻量“捷径头”
EAGLE 的思路是:不再单独训练一个小模型,而是在大模型顶部挂一个轻量级头部(通常小于 1B 参数),专门用来预测后续令牌。
大致流程是:
- 大模型在生成令牌时,每一层 Transformer 都会产出该位置的隐藏状态向量。
- EAGLE 取倒数第二层的隐藏状态作为输入,这一层通常已经包含了比较丰富的语义信息。
- EAGLE 头部是一个小神经网络,只基于这层隐藏状态就预测下一个令牌,不需要再跑完整个大模型。
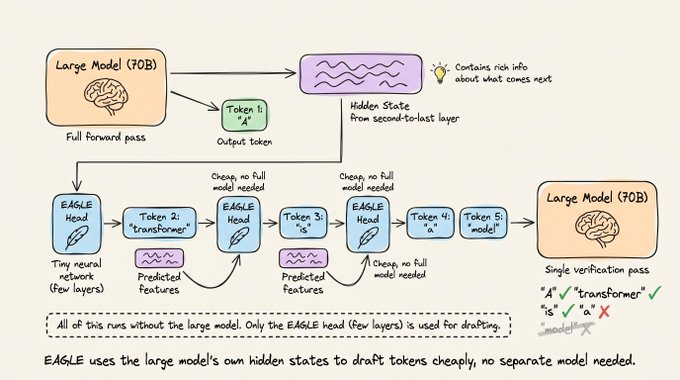
可以把它理解成一条“捷径”:
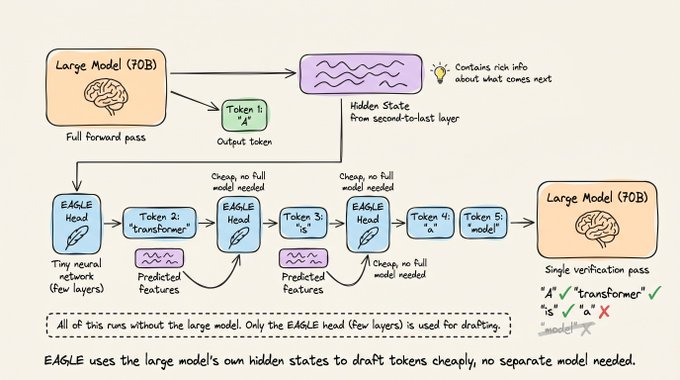
- 大模型先正常生成第一个令牌。
- 然后用 EAGLE 头部预测接下来的 K 个令牌,作为草稿。
- 接着,大模型做一次完整前向传播,对这 K 个令牌进行验证,流程与标准推测解码类似。
优势在于:
- 草稿预测直接基于大模型内部表示,不需要额外训练一个完全独立的小模型。
- 分词器天然一致,不存在 tokenizer 不匹配的问题。
风险点也要说清楚:EAGLE 头部本身需要额外训练和维护,对模型版本管理和部署流程会带来一定复杂度。
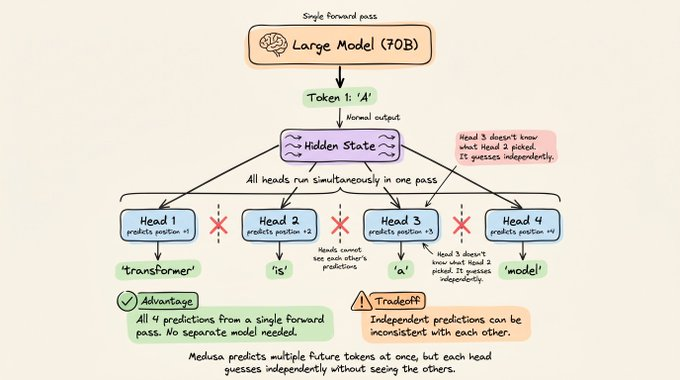
2) Medusa:一次性预测多个未来位置
Medusa 走的是另一条路:它不按顺序生成令牌,而是一次性预测多个未来位置的令牌。

做法是:

- 在大模型顶部附加多个小预测头,每个头负责不同的未来位置。
- 比如:头 1 预测下一个令牌,头 2 预测下下一个,头 3 预测第三个,以此类推。
- 所有头在一次大模型前向传播中并行运行,一次就拿到多个位置的预测结果。
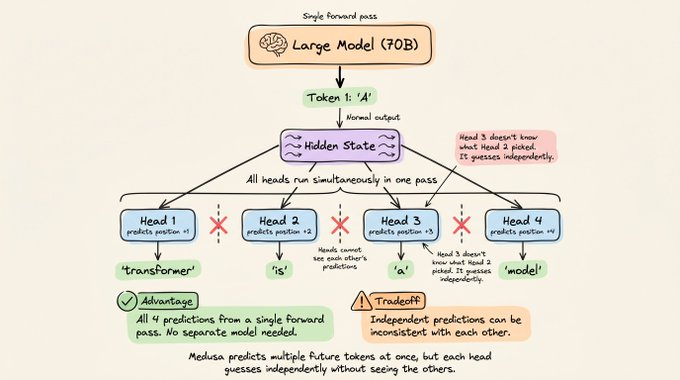
问题在于:
- 各个头是独立预测的,头 2 并不知道头 1 实际会选哪个令牌。
- 这会导致不同位置之间的预测不够一致,草稿接受率会被拉低。
好处是:
- 不需要额外模型和显存,多个头本身非常小,前向开销几乎可以忽略。
- 对已有大模型的改动相对局部,适合在一些自研模型体系里做深度优化。
3) 自推测解码:只跑前几层当“小模型”
自推测解码(Self-speculative decoding)更“抠门”一点:既不加头,也不加小模型,完全复用大模型本身。

利用的是一个简单事实:
- 一个 70B 模型可能有 80 层 Transformer。
- 对很多简单令牌来说,前 10-12 层就已经足够做出正确预测。
- 后面的层更多是在细化和确认结果。
于是流程变成:
- 草稿阶段只运行前 N 层(比如 12 层),提前退出并预测令牌。
- 重复 K 次,生成 K 个草稿令牌。
- 验证阶段再跑完整的 80 层,对这 K 个令牌做一次前向传播,检查哪些早期预测是对的。
简单、可预测的令牌往往会被早期层正确预测并接受,复杂令牌则会被拒绝,改用完整模型输出。
速度提升通常在 1.3-1.8 倍之间,确实不如双模型方案那么夸张,但好处是:
- 完全不需要额外模型、头部或显存。
- 工程改动相对可控,适合对延迟有要求但资源紧张的场景。
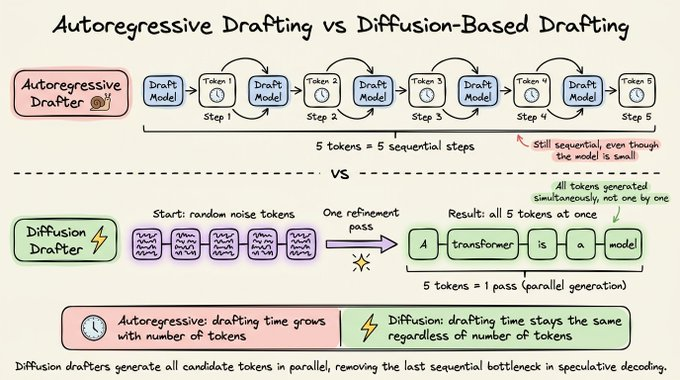
4) 基于扩散的草稿生成:草稿不再“逐字敲”
前面几种方案有一个共同点:草稿阶段仍然是自回归的,一次生成一个令牌。哪怕草稿模型再小,生成 8 个令牌也要 8 步。

扩散模型提供了一个完全不同的视角:
- 从一块随机噪声令牌开始,迭代并行地细化所有位置的令牌。
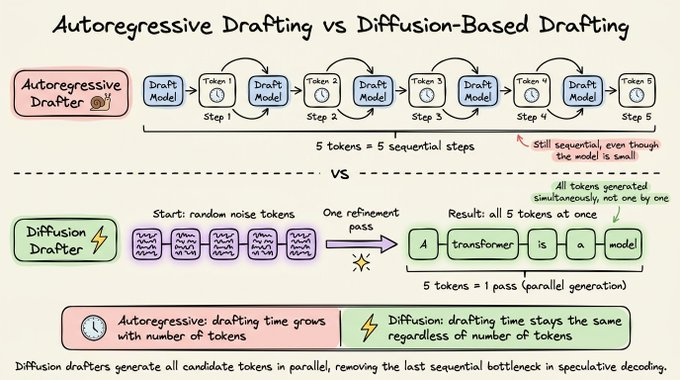
几步迭代之后,整块令牌会收敛成连贯的文本。这样一来:
- 生成 8 个令牌的自回归草稿需要 8 步。
- 扩散式草稿只需要 1 步(或固定少数几步),与令牌数量几乎无关。
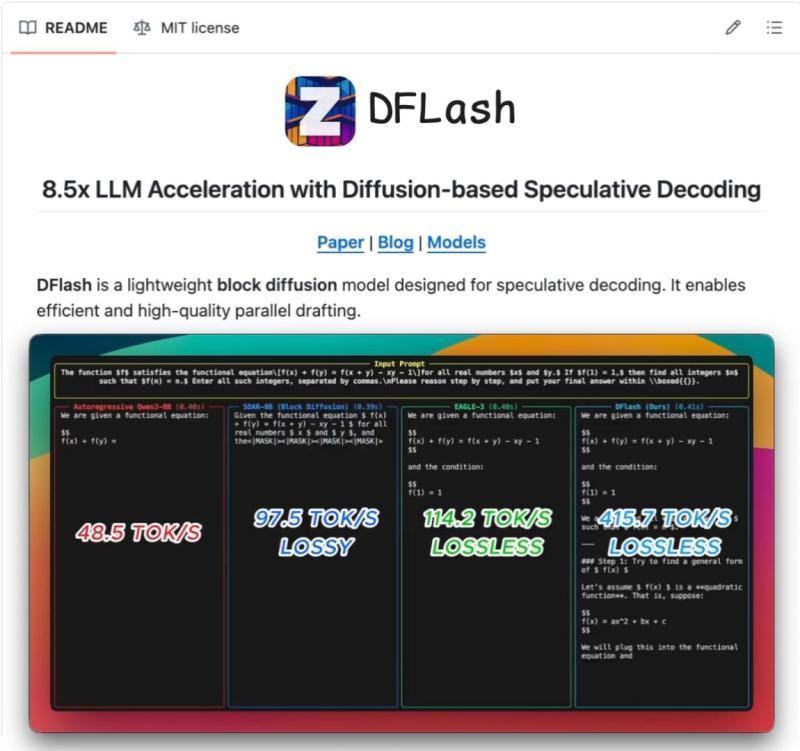
DFlash 就是把这个思路做成了一个实用方案:
- 它不是训练一个完全独立的扩散模型,而是在大模型上训练一个小扩散头,输入仍然是目标模型的隐藏状态,有点像 EAGLE 的扩散版。
- 扩散头一次性并行生成整块草稿令牌,草稿成本不会随着令牌数线性增长。
- 验证步骤仍然是标准推测解码那一套:大模型一次前向传播检查所有草稿令牌,决定接受还是拒绝。
区别只在于草稿生成方式:扩散是并行的,自回归是顺序的。

下方视频可以看到 DFlash 在实际生成过程中的表现:
推测解码与 KV 缓存:一个省次数,一个省每次的成本
从趋势上看,推测解码正在从“双模型方案”向“单模型内嵌草稿能力”演进。但在今天,大多数生产系统里,仍然是同系列双模型方案占主流,因为:
- 实现简单,生态成熟(Transformers、vLLM 等都支持)。
- 在合理配置下,速度提升稳定在 2-3 倍之间。
无论哪种变体,有一个共同的基础设施:KV 缓存。
- 草稿模型会维护自己的 KV 缓存,让自回归生成的每一步都尽量便宜。
- 目标模型在验证时,会在自己的 KV 缓存上继续扩展,避免对历史上下文重复计算。
如果没有 KV 缓存,草稿和验证阶段的每一步都要从头算起,推测解码的速度优势几乎会被吃光。
可以这么理解:推测解码负责“减少前向传播的次数”,KV 缓存负责“让每次前向传播更划算”。两者叠加,才是今天大厂在线推理能扛住海量请求的关键组合拳。
更多延伸阅读:

如果你在做在线推理、Agent 平台或内部知识助手,这套推测解码 + KV 缓存的组合,基本是绕不过去的“基础设施级”能力。很多团队是先上简单的双模型推测解码,跑通业务,再慢慢尝试 EAGLE、Medusa 或自推测这类更激进的方案。
说实话,这些方法的细节一时半会记不住也没关系,更重要的是:你知道什么时候该用它、该怎么选参数、该警惕哪些坑。等真要上线时,把这篇翻出来当 checklist,会比问十个朋友都来得靠谱。
常见问题
Q:推测解码会不会降低大模型的输出质量?
A:在严格实现的前提下,不会降低质量。原因是:推测解码只在大模型“同意”的情况下接受草稿令牌,一旦大模型在某个位置给出不同预测,就会用大模型的结果替换,并停止继续接受后续草稿。这样最终每个输出令牌,要么是大模型直接生成,要么是大模型在概率分布上与草稿一致时批准的结果。只要采样策略(温度、top-k、top-p 等)保持一致,整体输出分布与只跑大模型是数学上等价的。工程上需要注意的是,避免在草稿模型上做额外的采样或截断操作,否则会破坏这种等价性。
Q:在什么场景下不适合使用推测解码?
A:高温度、强创造性的生成任务往往不太适合。原因在于:温度升高后,模型的概率分布会变平,更倾向于选择次优甚至低概率令牌,目标模型和草稿模型之间的一致性会明显下降,草稿令牌被拒的比例上升。这样一来,推测解码的加速效果会被大幅削弱,甚至可能因为多了一层草稿开销而得不偿失。实操建议是:在问答、搜索摘要、代码补全等偏确定性任务上优先启用推测解码,在高温度写作、脑暴等场景中先做小规模 A/B 测试,再决定是否长期开启。
Q:如何选择合适的草稿模型大小,才能在速度和显存之间取得平衡?
A:经验上,草稿模型通常选为目标模型参数量的 1/10 到 1/50 比较合适。原因是:草稿模型越大,预测越接近目标模型,草稿接受率更高,但自身前向传播也更慢,会拉高整体延迟;草稿模型太小,则接受率偏低,大模型验证阶段要频繁“推翻重来”,加速效果有限。可以按这样的步骤操作:先选一个 0.5B-1B 级别的草稿模型做基线,测量端到端延迟和 token/s;再尝试更大一档(比如 2B)和更小一档(比如 0.3B),对比三者的加速比和显存占用,最终选“加速比/显存”性价比最高的那一档。
Q:UAG 会不会让所有模型组合都一样快?跨分词器搭配有什么隐形成本?
A:UAG 解决的是“能不能搭”的问题,不是“搭在一起都一样快”。跨分词器搭配时,框架需要把草稿模型的输出先解码成文本,再用目标模型的分词器重新编码,并做序列对齐,这一套流程本身就有额外开销。实测中,同分词器模型对的加速比通常能达到 1.5-3 倍,而跨分词器对往往在 1.5-1.9 倍之间。建议是:如果你能在同系列模型里找到合适的草稿模型,优先用原生路径;只有在确实需要跨家族组合(比如业务上强依赖某个大模型,但手头只有别家小模型)时,再考虑 UAG 方案,并预留一些性能裕度。
Q:推测解码和 KV 缓存是什么关系?只开一个还有效果吗?
A:两者是互补关系,单独开启也有收益,但叠加效果最好。KV 缓存的作用是:在自回归生成时,避免对历史令牌重复计算,让每一步前向传播更便宜;推测解码的作用是:减少需要完整前向传播的步数,让大模型“少出手”。如果只开 KV 缓存,你仍然要为每个新令牌跑一次前向传播;如果只开推测解码但不用 KV 缓存,草稿和验证阶段都会反复重算历史上下文,速度优势会被严重削弱。实战建议是:在任何对延迟敏感的场景里,把 KV 缓存视为必选项,再在此基础上评估是否引入推测解码。


