现代 SaaS 产品越来越多地内嵌 AI 能力,以提升用户体验和自动化水平。将大语言模型(LLM)如 DeepSeek 集成进 Web 应用,可以让产品从“表单 + 按钮”的刚性界面,升级为自然语言驱动的智能系统。
用户不再需要死记硬背菜单和配置项,而是可以直接用自然语言描述问题或任务(例如英文或中文),由模型给出智能回复或自动执行操作。这种交互方式显著降低使用门槛、提升留存和转化,在竞争激烈的 SaaS 市场中形成差异化优势。
DeepSeek 是一款面向软件开发、自然语言处理和业务自动化场景的前沿开源大模型。它采用 Mixture-of-Experts(MoE) 架构,总参数量达 671B,但每次推理仅激活约 37B 参数,在性能与算力成本之间取得了很好的平衡。
在编码能力方面,DeepSeek 在 HumanEval 基准测试中取得了 73.78% 的 pass@1 成绩,并支持最长 128K tokens 的上下文窗口,远超多数模型,适合处理长文档、长对话或复杂业务上下文。
更重要的是,DeepSeek 完全开源并允许商业使用,企业可以在不承担高昂闭源 API 费用的前提下,引入先进的 AI 能力。
根据公开对比数据,DeepSeek 的 token 成本比 GPT-4 低 95% 以上,非常适合在 Web 平台中构建聊天机器人、自动文档分析、代码助手等高频 AI 功能。
接下来,我们将从访问方式选择(云端 API vs 自建推理)、前后端集成示例、部署与扩展、典型用例、前端 UX 设计、安全与成本优化等多个维度,梳理一条将 DeepSeek 引入 SaaS 产品的实战路线。
一、访问方式选择:托管 API vs 本地/私有化推理
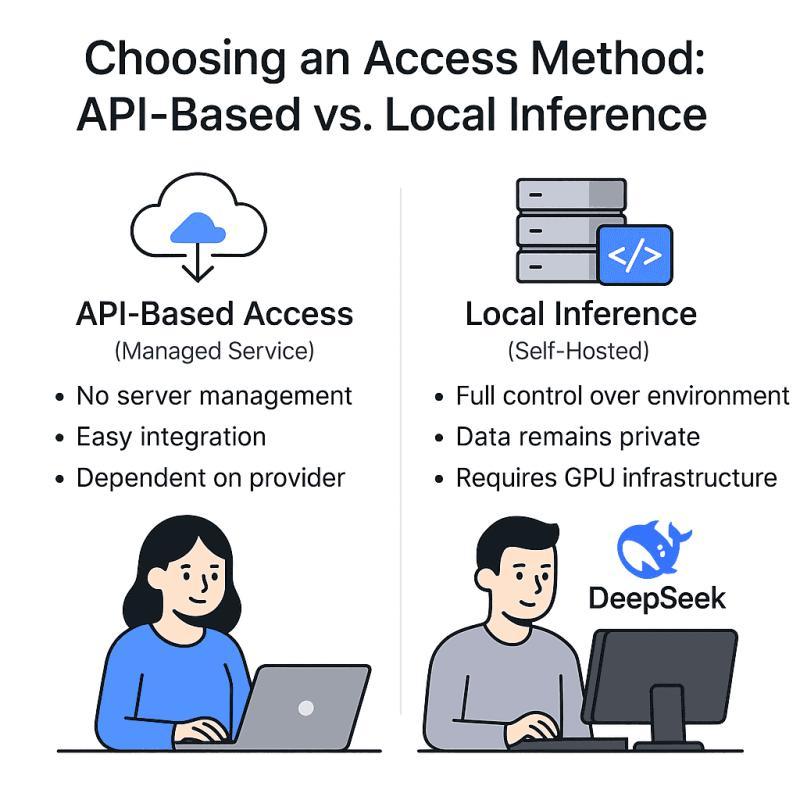
在将 DeepSeek 集成进应用之前,首先要决定:是通过云端托管 API 调用模型,还是在自有基础设施上本地部署模型进行推理?
两种方式各有优劣:
-
托管 API(Managed Service)
由第三方(如 DeepSeek 官方云服务或 Hugging Face)托管模型,并通过 HTTPS API 对外提供推理能力。开发者只需发起 HTTP 请求即可获得结果,无需管理服务器、GPU 或模型版本。
优点是接入门槛极低,模型升级、弹性扩容、运维都由服务商负责,非常适合原型验证、小规模产品或早期阶段。
但你需要接受:按量计费、请求限流、以及数据需经过第三方服务器等现实约束。对于有严格合规要求的行业,这可能是一个重要考量。 -
自建推理(本地或私有云部署)
将 DeepSeek 模型权重下载到自有服务器(本地机房或云主机)上运行。这样可以完全掌控模型环境、配置和更新,所有数据都留在自己的基础设施中,更易满足隐私与合规要求,也可以按需微调或定制模型。
对于高并发、高调用量场景,自建往往在长期成本上更具优势,因为不再按请求付费。
代价是需要投入工程和运维资源:准备高性能 GPU、搭建推理服务、监控与扩容等。
如何选择?
- 低流量、需求不稳定、快速试错阶段:优先使用托管 API,减少前期投入。
- AI 能力是产品核心、调用量大、或有严格数据隐私要求:建议规划自建推理,或至少预留从 API 迁移到自建的路径。
- 也可以采用 混合策略:先用 API 快速上线,随着业务增长再迁移到自建 DeepSeek 服务。
下面先介绍基于 API 的集成方式,再讲自建部署方案。
二、基于 API 的集成(托管推理)
如果选择云端托管方式,常见有两条路径:
- 使用 DeepSeek 官方 API(OpenAI 兼容协议)
- 使用 Hugging Face Inference API 调用 DeepSeek 模型
1. 使用 DeepSeek 官方 API
DeepSeek 官方提供了 RESTful API,并刻意设计为 兼容 OpenAI Chat/Completions 接口,这意味着如果你用过 GPT-3/4 的 API,迁移到 DeepSeek 几乎是“换个 baseURL + model 名称”这么简单。
基本步骤:
- 获取 API Key:在 DeepSeek 平台注册账号,生成一个私密的 API Key,用于请求鉴权。
- 设置 Base URL:将原本的 OpenAI 地址替换为
https://api.deepseek.com或https://api.deepseek.com/v1。 - 调用 Chat Completion 接口:向
/chat/completions发送 JSON 请求体,包含模型名和消息列表。常用模型包括:"deepseek-chat":通用对话模式"deepseek-reasoner":更偏重长链路推理的模式
示例 cURL 请求:
curl https://api.deepseek.com/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $DEEPSEEK_API_KEY" \
-d '{
"model": "deepseek-chat",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello, DeepSeek!"}
],
"stream": false
}'
返回格式与 OpenAI Chat API 完全一致:你传入带有 system、user、assistant 角色的消息数组,API 返回 choices 数组,其中包含模型回复。
DeepSeek 也支持 流式输出("stream": true),后文会结合前端 UX 说明如何使用。
你还可以直接复用 OpenAI 官方 SDK,只需改 baseURL 和 key:
Python 示例:
import openai
openai.api_base = "https://api.deepseek.com/v1"
openai.api_key = "YOUR_DEEPSEEK_API_KEY"
response = openai.ChatCompletion.create(
model="deepseek-chat",
messages=[{"role": "user", "content": "Hello, DeepSeek!"}]
)
print(response["choices"][0]["message"]["content"])
Node.js 示例:
const OpenAI = require("openai");
const openai = new OpenAI({
baseURL: "https://api.deepseek.com",
apiKey: process.env.DEEPSEEK_API_KEY,
});
const completion = await openai.chat.completions.create({
model: "deepseek-chat",
messages: [{ role: "user", content: "Hello, DeepSeek!" }],
});
console.log(completion.choices[0].message.content);
DeepSeek API 的关键特性:
- 128K 上下文窗口:远大于常见 8K/32K 模型,适合长文档总结、长对话、多轮业务流程等场景。
- 支持 函数调用(function calling) 与 JSON 格式输出,便于结构化任务(如让模型返回 JSON 对象)。
- 定价极具竞争力:以 DeepSeek-V3.2 为例,约 $0.28/百万输入 token(缓存未命中)、$0.42/百万输出 token;缓存命中时输入 token 价格可降至 $0.028/百万。相比 GPT-4 每百万 token 可能高达 $60+,成本优势非常明显。
- 提供用量监控与限流面板,可在官网查看最新价格和配额。
2. 使用 Hugging Face Inference API
如果暂时不想注册 DeepSeek 官方账号,或只是想快速试验模型,可以通过 Hugging Face 的 Inference API 调用托管在 Hub 上的 DeepSeek 模型。
调用方式与普通 REST API 类似:
POST https://api-inference.huggingface.co/models/deepseek-ai/deepseek-llm-7b-chat
Authorization: Bearer YOUR_HF_API_TOKEN
Content-Type: application/json
{ "inputs": "Your prompt here", "parameters": { ... } }
其中 repo_id 为模型在 Hub 上的名称,如 deepseek-ai/deepseek-llm-7b-chat 或 deepseek-ai/deepseek-llm-67b-chat 等。你需要在 Hugging Face 账号中生成一个 API Token,并放入请求头。
Python SDK 示例:
from huggingface_hub import InferenceApi
inference = InferenceApi(
repo_id="deepseek-ai/deepseek-llm-7b-chat",
token=HF_API_TOKEN,
)
result = inference(inputs="Hello, DeepSeek!")
print(result)
需要注意的点:
- 限流:免费层大约每小时 50 次请求,付费层可提升到每小时数百次甚至更多。高频调用场景容易触达上限。
- 冷启动:模型按需加载,首次调用可能较慢,甚至返回 503“模型加载中”。可通过请求头
x-wait-for-model: true让服务等待加载完成再返回结果。 - 免费 Inference API 不支持流式输出:通常一次性返回完整结果,如需流式推理需使用 Hugging Face Inference Endpoint 或自建服务。
如果你已经打算为 Hugging Face 的专用 Endpoint 付费,那么也可以对比 DeepSeek 官方 API 或自建推理的成本与灵活性,再做选择。
3. 前端集成示例(Next.js / React)
在现代 Web 应用中,常见的交互是:用户在聊天窗口或按钮点击后触发一次 LLM 调用。不要在浏览器端直接携带密钥调用 LLM API,而是通过后端中转,保护 API Key 安全。
以 Next.js 为例,可以创建一个 /api/ask 路由,前端通过 fetch 调用该路由:
// React 组件内部
async function handleSubmitQuestion(question) {
setLoading(true);
const res = await fetch("/api/ask", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ query: question }),
});
const data = await res.json();
setLoading(false);
setAnswer(data.answer);
}
后端(例如 Node.js + Express)中转调用 DeepSeek:
app.post("/api/ask", async (req, res) => {
const userQuery = req.body.query;
const response = await fetch("https://api.deepseek.com/chat/completions", {
method: "POST",
headers: {
Authorization: `Bearer ${process.env.DEEPSEEK_API_KEY}`,
"Content-Type": "application/json",
},
body: JSON.stringify({
model: "deepseek-chat",
messages: [{ role: "user", content: userQuery }],
}),
});
const result = await response.json();
const answerText = result.choices[0].message.content;
res.json({ answer: answerText });
});
前端拿到 data.answer 后即可渲染到界面中。如果改用 Hugging Face API,只需调整 URL、请求体和鉴权方式。
安全要点:
- API Key 必须存放在服务端环境变量中(如
process.env.DEEPSEEK_API_KEY),不要写死在前端代码里。 - 对
/api/ask等接口做基础限流,防止恶意刷接口或 Bug 导致的无限循环调用。 - 注意 LLM 调用的延迟通常在数百毫秒到数秒之间,前端应异步处理并提供加载提示(如“正在思考…”)。
4. 后端集成示例(Node / Flask / FastAPI)
后端语言不限,这里以 Node.js 和 Python 为例:
-
Node.js(TypeScript / JavaScript)
可直接使用fetch或 Axios 调用 DeepSeek,也可以使用 OpenAI 官方 Node SDK,并指定baseURL:const OpenAI = require("openai"); const openai = new OpenAI({ baseURL: "https://api.deepseek.com", apiKey: process.env.DEEPSEEK_API_KEY, }); const completion = await openai.chat.completions.create({ model: "deepseek-chat", messages: [{ role: "user", content: userQuery }], }); const answer = completion.choices[0].message.content; -
Python(Flask / FastAPI)
使用requests或 OpenAI Python SDK:import os import requests from flask import Flask, request app = Flask(__name__) @app.route("/api/ask", methods=["POST"]) def ask(): user_query = request.json["query"] headers = { "Authorization": f"Bearer {os.environ['DEEPSEEK_API_KEY']}", "Content-Type": "application/json", } payload = { "model": "deepseek-chat", "messages": [{"role": "user", "content": user_query}], } rsp = requests.post( "https://api.deepseek.com/chat/completions", json=payload, headers=headers, ) answer = rsp.json()["choices"][0]["message"]["content"] return {"answer": answer}
在生产环境中,还需要:
- 从安全存储(环境变量、密钥管理服务)读取 API Key;
- 对 4xx/5xx 错误、429 限流等情况做重试或友好降级;
- 根据业务需要开启
stream流式输出,并在后端和前端分别处理流式响应。
三、自建 DeepSeek 推理服务(部署与服务化)
对于希望掌控数据与成本的团队,自建 DeepSeek 推理服务是非常有吸引力的方案。DeepSeek 提供了 7B 与 67B 等不同规模的模型权重,可从 Hugging Face 或 S3 下载并在自有环境中运行。
1. 基础设施与硬件需求
-
云端 GPU 或裸金属服务器
可选择 AWS、GCP、Azure 等云厂商的 GPU 实例(如 AWS EC2p3、p4系列,配备 V100/A100 等 GPU),也可以使用本地机房或高端桌面 GPU(RTX 3090/4090 等)运行 7B 模型。
67B 模型体量较大,更适合部署在 A100 级别或多卡环境。 -
显存需求(粗略估算)
- DeepSeek-7B:FP16 精度下约需 14–16 GB 显存;若使用 4bit 量化,可压缩到约 4 GB 左右,12–16 GB 显存的消费级显卡即可胜任。
- DeepSeek-67B:FP16 下显存需求可达 130–140 GB,一般需要多卡切分;4bit 量化后约 38 GB,可放入单张 48 GB 显卡(如 RTX 6000 Ada),或通过多卡切分部署在多张 24 GB 显卡上。
可借助 Hugging Face Transformers 的
Accelerate、PyTorch FSDP 等工具实现多 GPU 切分。 -
CPU、内存与存储
模型加载和部分权重/缓存的 CPU 参与度较高,建议预留充足的系统内存(至少与模型大小同量级),并使用 NVMe SSD 存储模型权重,以缩短加载时间。
2. 推理框架选择:vLLM vs LMDeploy 等
单纯在 Notebook 中 from transformers import AutoModel 只能算“跑通”,要支撑多用户并发访问,需要专门的推理/服务框架。当前社区中较成熟的选择包括:

-
vLLM
高效的 LLM 推理引擎,支持动态连续批处理和 PagedAttention 等技术,大幅提升吞吐量并优化显存利用。
特点:- 与 Hugging Face 模型接口良好集成;
- 自带 OpenAI 兼容 HTTP Server,可直接暴露
/v1/chat/completions等接口; - 支持多 GPU、量化(GPTQ、INT8/4)和 FlashAttention 等优化。
对于希望“快速搭一个 OpenAI 风格服务”的团队,vLLM 是非常友好的选择。
-
LMDeploy
来自 MMSC Lab 的推理与部署工具,主打极致性能优化。官方测试中,在某些场景下吞吐量可比 vLLM 提升约 1.8 倍。
特点:- 持续批处理、阻塞 KV Cache、优化 CUDA Kernel;
- 支持多 GPU 并行和自动 4bit 量化;
- 提供 Python API 与 C++ Server,并可集成 NVIDIA TensorRT。
相比 vLLM,LMDeploy 的部署门槛略高一些,但在追求极致 QPS 的场景中非常值得考虑。
其他可选方案:
- Hugging Face Text Generation Inference(TGI):Docker 一键部署,支持多客户端批处理和 SSE 流式输出;
- Ollama / Oobabooga:更偏本地桌面和爱好者场景;
- 直接用 Transformers + FastAPI 自行封装 REST 接口(灵活但性能优化工作量更大)。
3. 部署与扩展实践
以 vLLM 为例,部署流程大致如下:
- 准备好带 GPU 的服务器,安装合适版本的 CUDA 驱动;
- 使用
git lfs或 HF Hub 下载 DeepSeek 模型权重到本地; - 安装 vLLM 并启动 OpenAI 兼容服务:
pip install vllm
python -m vllm.entrypoints.openai.api_server \
--model /path/to/deepseek-llm-7b-chat \
--port 8000
此时,服务器在 8000 端口上提供 OpenAI 风格的 REST API,你可以将应用中的请求指向:
http://your-server:8000/v1/chat/completions
并在前面加一层反向代理(如 Nginx)处理 HTTPS 与鉴权。
横向扩展与性能调优要点:
- 如果单实例无法承载流量,可部署多台 vLLM 实例,通过 Nginx/HAProxy 做负载均衡;
- 合理利用批处理:适当允许请求排队几毫秒,以便合并成批次,提高整体吞吐;
- 对于 67B 模型,需规划多 GPU 或多节点部署,并确保 GPU 间有足够带宽(NVLink/InfiniBand);
- 使用容器化(Docker/Kubernetes)管理服务,配置健康检查与自动重启,防止模型进程崩溃导致整体不可用;
- 注意冷启动时间:加载 67B 模型可能需要数十秒到数分钟,可保持少量常驻实例,峰值时再按需扩容。
4. 通过 REST / WebSocket 对外提供服务
无论使用 vLLM、LMDeploy 还是自研服务,最终都需要对 Web 应用暴露一个统一的接口:
- RESTful HTTP API:最常见的方式,接口形态类似官方 DeepSeek API;
- WebSocket / SSE 流式接口:用于实时推送生成中的内容,提升交互体验。
以 FastAPI + SSE 为例,可以这样实现一个简单的流式接口:
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
app = FastAPI()
@app.get("/stream")
async def stream(prompt: str):
async def token_generator(prompt):
for token in generate_tokens(prompt): # 伪代码:逐 token 生成
yield token + "\n"
return StreamingResponse(token_generator(prompt), media_type="text/plain")
前端使用 EventSource 接收:
const evtSource = new EventSource("/stream?prompt=" + encodeURIComponent(userPrompt));
evtSource.onmessage = (event) => {
const token = event.data;
appendToAnswer(token);
};
在实际项目中,你可能会:
- 使用 JSON 作为事件载体;
- 在流结束时发送特殊标记,告知前端“回答已完成”;
- 或改用 WebSocket,实现双向通信(例如中途打断生成)。
一旦自建模型通过 REST / WebSocket 对外提供服务,前端和业务后端就可以像调用官方 API 一样调用自建 DeepSeek 服务,只是域名和鉴权方式由你自己定义。
四、典型业务场景示例
下面通过几个具体场景,帮助你思考如何在 SaaS 产品中落地 DeepSeek:
场景 1:SaaS 后台中的 AI 助手 / 聊天机器人
假设你运营一款项目管理 SaaS,希望在控制台中加入一个“AI 助手”侧边栏,帮助用户快速获取信息、执行操作。
用户可以问:
- “帮我总结一下本周所有项目的进度。”
- “告诉我本季度销售额按地区的拆分情况。”
你的系统可以先从数据库中拉取相关数据,再将结构化数据和用户问题一起作为上下文传给 DeepSeek,由模型生成自然语言总结或解释。
在客服、知识库、企业内部系统中,DeepSeek 也可以作为 FAQ 机器人或知识助手,基于企业文档、政策、流程为员工或客户提供即时解答。
实现要点:
- 使用
deepseek-chat模式,维护多轮对话的messages历史; - 利用 128K 上下文窗口,支持较长会话和复杂业务上下文;
- 对于企业内部知识,结合向量检索(RAG),先检索相关文档片段,再连同问题一起传给模型生成答案。
场景 2:上传文档的智能摘要与问答
如果你的平台支持上传 PDF、Word、会议记录等文件,可以为用户提供 AI 摘要与文档问答 功能。
例如:
- 用户上传一份 50 页的销售报告,点击“生成 5 条要点摘要”;
- 在合同审阅场景中,用户可以问:“买方在这份合同中的主要义务有哪些?”
实现路径:
- 后端使用 PDF 解析或 OCR 工具提取文本;
- 构造提示词,例如:
- “请用 5 条要点总结以下报告内容:\n\n[全文]”;
- 将全文(或截断后的文本)作为上下文传给 DeepSeek;
- 返回摘要并在前端以列表或卡片形式展示。
由于 DeepSeek 支持 128K tokens,上百页的文档通常可以一次性处理;对于更长文本,可以分段摘要再二次汇总。
还可以利用 JSON 输出能力,让模型从文档中抽取结构化信息(如日期、金额、关键条款等),用于后续自动化处理。
场景 3:面向开发者工具的代码助手
DeepSeek 在 HumanEval 上取得 73.78% pass@1,具备非常强的代码理解与生成能力,适合作为开发者工具中的 代码助手。
典型用法包括:
-
代码生成 / 补全:
- 用户输入自然语言需求:“写一个 Python 函数,递归计算阶乘”;
- DeepSeek 返回完整函数实现;
- 或在云 IDE 中根据上下文自动补全下一段代码。
-
代码解释 / 审查 / 调试:
- 用户粘贴一段代码,询问“这段代码在做什么?”;
- 或“帮我找出这个函数可能存在的 bug”;
- DeepSeek 可以给出解释、指出潜在问题,并生成单元测试样例。
-
DevOps / 配置生成:
- 根据自然语言描述生成 CI/CD 配置、Terraform 脚本、K8s YAML 等。
集成时建议:
- 在
system提示中明确角色:“你是一个专业的代码助手,只输出代码或技术解释”; - 对输出进行语法高亮渲染,提升可读性;
- 将 AI 生成代码视为“不可信输入”,在执行前进行安全审查或限制在沙箱环境中运行。
五、前端 UX 设计要点
LLM 集成不仅是后端工作,前端体验设计同样关键。一个“聪明但卡顿”的助手,用户体验依然糟糕。
关键建议:
-
尽量使用流式输出
让回答像“打字”一样逐字出现,可以显著降低用户感知等待时间。可通过 SSE 或 WebSocket 实现,React/Vue 等框架都能轻松根据流式数据更新界面。 -
明确的加载反馈
从用户点击“发送”到第一批 token 到达之间,往往有 1–2 秒甚至更久。务必在这段时间内展示加载状态(如“正在生成回答…”、打字动画、骨架屏等),避免用户误以为系统无响应。 -
超时与失败处理
对超时、网络错误、模型错误等情况,前端要有清晰的提示和重试入口,例如:“本次生成超时,请重试”。后端可设置最大生成时长和最大输出 token 数,避免极端长回答拖垮体验。 -
输入校验与引导
对空输入、超长输入等情况进行前端校验,给出友好提示。可以在输入框中放置示例占位文案(如“试试:帮我总结这份报告的关键结论”),降低使用门槛。 -
结果展示与排版
- 代码用等宽字体和高亮展示;
- 长文本自动分段,适当增加行距;
- 表格类输出可解析为真正的表格组件;
- 对特别长的回答,可以折叠或提供“展开更多”。
-
对话上下文与控制
在聊天场景中,清晰展示历史对话,允许用户中途“停止生成”,并支持重新编辑上一次提问再发送。 -
移动端适配
确保在手机上也能流畅滚动长回答,输入框和发送按钮易于点击,流式动画不会造成明显卡顿。
六、安全与成本优化
引入强大的 LLM 能力的同时,也必须重视安全、合规与成本控制。以下是实践中非常重要的几个方面:
-
限流与配额
- 对外部接口(如
/api/ask)按用户或 IP 做 QPS/QPM 限制,防止恶意刷接口或 Bug 导致的爆量调用; - 对内部用户建立用量统计与配额机制,尤其是在按调用计费的商业模式下。
- 对外部接口(如
-
结果缓存
- 对重复度较高的问题(如 FAQ)可以做结果缓存,避免重复调用模型;
- 对耗时较长的分析任务(如长文档总结),在一定时间窗口内复用结果,提升体验并节省成本。
-
输入内容过滤
- 对用户输入进行基础过滤,拦截明显违规内容(极端暴力、仇恨、违法指令等);
- 可采用关键词过滤或接入专门的内容审核服务;
- 对被拦截的请求给出清晰提示,说明原因。
-
输出审核与防护
- 大模型可能输出不当、偏见或错误内容,建议对输出做二次检查;
- 可使用轻量级分类模型或规则检测明显违规内容;
- 提供“举报”入口,收集用户反馈以持续改进提示词和策略。
-
数据隐私与合规
- 明确告知用户哪些数据会被发送给模型;
- 使用 HTTPS 保护传输安全;
- 对日志和对话记录进行脱敏或加密存储,限制访问权限;
- 在金融、医疗等敏感行业,需结合当地法规(如 GDPR 等)进行合规评估。
-
成本监控与上限控制
- 对每个用户、每个租户统计 token 用量,设置合理上限;
- 对免费用户设置“公平使用”策略,对高用量用户引导升级付费;
- 自建推理时,监控 GPU 利用率和能耗,合理安排实例数量和运行时段。
-
效率优化
- 避免在每次请求中重复发送大量无关上下文,必要时对历史对话做摘要;
- 对简单可确定的问题(如基础算术、固定规则)优先用程序逻辑处理,而不是调用 LLM;
- 根据任务复杂度选择不同规模的模型:简单任务用小模型,复杂任务再调用大模型。
-
日志与分析
- 记录调用日志(在合规前提下),包括请求类型、耗时、错误率等;
- 分析用户最常见的问题和场景,优化提示词、缓存策略和产品功能;
- 通过日志发现异常模式(如异常高频调用),及时采取防护措施。
七、总结与落地建议
将 DeepSeek 集成到 Web 应用或 SaaS 平台,可以为产品带来:
- 更自然的对话式交互;
- 更高效的内容生成与数据分析;
- 更智能的自动化与辅助决策能力。
在实践中,可以遵循以下路线:
- 从价值场景出发:先明确在哪些功能中引入 LLM 能真正提升体验(如智能客服、文档摘要、代码助手等),避免“为用 AI 而用 AI”。
- 优先用托管 API 快速验证:利用 DeepSeek 官方 API 或 Hugging Face Inference API,先在小范围内上线功能,收集用户反馈与用量数据。
- 根据业务发展规划自建:当调用量增大、隐私要求提高或成本压力显现时,评估使用 vLLM、LMDeploy 等框架自建 DeepSeek 推理服务,并逐步迁移核心流量。
- 重视前端体验与安全合规:通过流式输出、加载反馈、输入输出审核等手段,让 AI 功能既好用又可靠;同时做好限流、缓存和成本监控,保证可持续运营。
- 持续迭代与优化:
- 跟进 DeepSeek 新版本和社区最佳实践;
- 根据日志和用户反馈调整提示词、模型参数和路由策略;
- 逐步扩展更多 AI 功能,如自动报告生成、智能推荐、个性化引导等。
DeepSeek 作为一款性能强大、成本友好且可商用的开源大模型,为 SaaS 产品提供了极具性价比的 AI 基础设施。只要在架构、体验和安全上设计得当,它可以成为你产品中长期稳定的“智能引擎”,帮助你构建真正“会思考”的 Web 应用。


