你以为“能调通 DeepSeek API”就算接入完成,其实那只是踩坑的开始。真正把 DeepSeek 用进企业生产环境,关键不在模型,而在你有没有一层可控、可审计、可降本的网关 / 代理架构。很多团队是上线后才发现:成本爆表、日志泄密、合规不过审,想补救已经很难。
一、什么是企业级 DeepSeek 网关 / 代理?
1. 网关 vs 代理:差在哪儿?
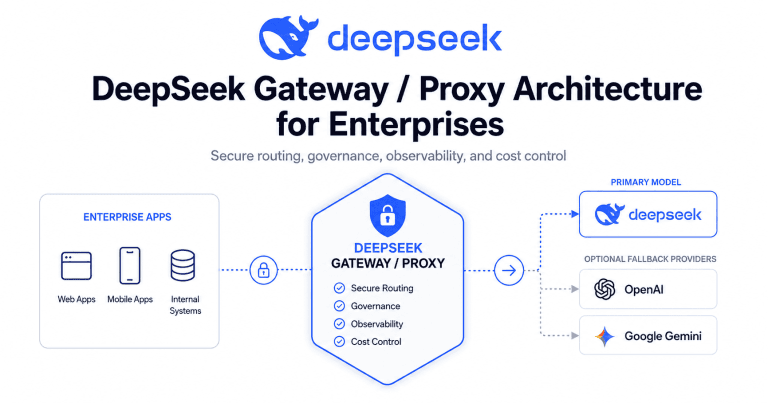
企业级 DeepSeek 网关,本质是内部应用和 DeepSeek API 之间的一层控制平面:统一接收请求、做身份校验和策略决策,再把“通过审核”的请求转发给 DeepSeek 或其他 LLM 提供方。它可以是托管 AI 网关、自建 LLM 代理、Kubernetes 原生网关,或者内部定制服务。
DeepSeek 代理架构通常更窄:主要负责转发流量、改写请求、注入凭证、做基础日志和限流。一个完整的 AI 网关则会理解 LLM 语境:Token 预算、模型路由、上下文缓存、流式响应、工具调用策略、提示词脱敏、回退策略、按团队分摊成本等。
当只有一个内部应用、一个模型、合规要求不高时,一个简单反向代理也许够用。但一旦涉及多产品、多团队、多租户、智能体、编码助手或受监管业务,就需要 企业级 LLM 网关架构 来兜底。
可以简单记:要“控连接”用反向代理,要“控行为、控风险”就必须上 AI 网关。
2. DeepSeek API 集成层的角色
DeepSeek 提供 OpenAI 兼容和 Anthropic 兼容两套 API 形式,基础 URL 分别是 https://api.deepseek.com 和 https://api.deepseek.com/anthropic。这让你可以沿用现有 SDK 和工具,但企业应用不应该直接调用这些公网地址。
更合理的做法是:应用统一调用内部地址,比如:
https://llm-gateway.company.example/v1/chat/completions
网关负责把请求映射到 DeepSeek 的 OpenAI 兼容或 Anthropic 兼容接口,同时屏蔽底层提供方细节。DeepSeek 文档会不断更新 V4 模型名、上下文长度、最大输出、功能支持和 Token 计费方式,生产团队需要在每个发布周期校验,而不是在应用里写死。
3. OpenAI 兼容调用模式示例
很多企业内部工具、Agent 框架、编码助手都已经支持 OpenAI 风格客户端,这时只要把它们指向内部网关即可:
import os
import hashlib
from openai import OpenAI
def stable_user_hash(user_email: str) -> str:
# 不要把原始邮箱或私密标识发给模型提供方
salt = os.environ["USER_HASH_SALT"]
return hashlib.sha256(
f"{salt}:{user_email}".encode()
).hexdigest()[:32]
client = OpenAI(
api_key=os.environ["INTERNAL_AI_GATEWAY_TOKEN"],
base_url="https://llm-gateway.company.example/v1"
)
response = client.chat.completions.create(
model="deepseek-v4-pro",
messages=[
{
"role": "system",
"content": (
"You are an enterprise support assistant. "
"Follow company data-handling policy."
)
},
{
"role": "user",
"content": (
"Summarize the attached customer escalation "
"without exposing private identifiers."
)
}
],
max_tokens=1200,
stream=False,
# 仅供网关使用的元数据
extra_headers={
"X-Tenant-ID": "finance-prod",
"X-Workload": "support_summarization"
},
# DeepSeek 支持的参数
extra_body={
"user_id": stable_user_hash("user@example.com")
}
)
print(response.choices[0].message.content)
在这个模式下,网关校验 INTERNAL_AI_GATEWAY_TOKEN,把调用方映射到对应团队和策略,做敏感信息脱敏,从机密管理系统注入 DeepSeek 凭证,只把经过校验的元数据转发出去。
元数据小贴士:租户 ID、工作负载、成本中心、环境等字段,应该主要被网关消费,用于策略、审计和成本归集,不要无脑转发给 DeepSeek。像
user_id这类提供方支持的字段,也要先校验再转发。
4. Anthropic 兼容调用模式
DeepSeek 的 Anthropic 兼容接口使用 https://api.deepseek.com/anthropic,支持 x-api-key、流式响应,以及 metadata.user_id 等字段,对不支持的元数据会忽略。
企业侧的建议很明确:不要把这个公网地址直接暴露给开发者,而是配置工具指向企业网关的 Anthropic 兼容路由,例如:
ANTHROPIC_BASE_URL=https://llm-gateway.company.example/anthropic
ANTHROPIC_API_KEY=
网关再统一做翻译、过滤、路由和日志记录,避免出现“每个团队一套私有接入方式”的混乱局面。
5. 模型命名与别名策略
在企业内部,推荐使用 统一的模型别名,而不是到处散落着提供方原始模型名。比如:
enterprise-fast→ DeepSeek V4-Flashenterprise-reasoning→ DeepSeek V4-Pro
DeepSeek 2026 年 4 月的更新说明中提到:V4-Pro 和 V4-Flash 可以通过 OpenAI Chat Completions 和 Anthropic 接口访问,同时 deepseek-chat 和 deepseek-reasoner 将在 2026-07-24 停用。用别名可以把这些变更隔离在网关层,应用不用频繁改代码。
6. 流式与非流式:体验与风控的权衡
网关需要同时支持流式和非流式两种调用。流式能显著改善长回答场景的体验,但会让内容审核、日志记录、响应缓冲和超时处理变复杂。
DeepSeek 文档说明:长时间推理会保持 HTTP 连接;非流式请求可能返回空行,流式请求则会返回类似 : keep-alive 的 SSE 保活注释;如果 10 分钟内推理尚未开始,服务端可能主动断开连接。
网关在设计时要考虑:
- 正确保留 SSE 事件边界
- 分别设置空闲超时和总超时
- 不要对已经部分流出的响应盲目重试
- 记录首 Token 时间和完成时间
- 决定风控是在流前、流后还是按分片执行
二、为什么企业必须在 DeepSeek 前面加一层网关?
1. 直连模式的隐性代价
应用直接连到提供方,在小规模试验阶段看起来很顺手,但一旦扩展到全公司,就会暴露出一堆问题:每个团队自己存密钥、自己写重试逻辑、自己打日志,成本和风险都不可见。
没有统一的 DeepSeek API 网关,常见现象包括:
- 密钥在代码库、CI 日志、笔记本里到处乱飞
- 有的团队无限制拉长上下文,账单暴涨
- 日志里混着原始提示词、客户数据和源代码
- 重试策略各搞各的,遇到 429 直接“风暴式重试”
据一些大型互联网企业内部 FinOps 报告,GenAI 相关成本在半年内翻了 3 倍,其中超过 40% 来自“没人管的长上下文和 Agent 循环”。这类问题,单靠开发自觉是压不住的。
2. 网关能统一落实的控制点
一个设计合理的网关,可以让平台团队在一个地方集中执行:
- 身份认证与服务鉴权(SSO、mTLS、服务账号等)
- 访问控制与路由策略(按团队、环境、数据级别)
- DLP 与敏感信息检测 / 脱敏
- Token 计量与预算控制
- 模型路由与多提供方回退
- 日志与审计(含策略版本、Trace ID 等)
现在市面上的 AI 网关产品(如 Cloudflare AI Gateway、Kong AI Gateway 等)几乎都内置缓存、限流、动态路由、DLP、Guardrails、重试和回退能力,本质上就是在帮企业搭一层 AI 流量控制平面,而不是让每个应用自己去调 SDK。
有用户反馈:在接入统一网关后,单月 LLM 成本下降了约 30%,主要来自统一的 Token 限制和缓存策略,而不是“砍需求”。
3. 用户隔离与隐私:user_id 的正确打开方式
DeepSeek 支持 user_id 参数,用于更细粒度的内容安全隔离、KVCache 隔离和调度隔离。文档要求 user_id 必须匹配 [a-zA-Z0-9\-_]+,最长 512 字符,且不应包含私密信息。
一个典型的企业模式是:
- 在内部系统保存真实用户身份
- 生成稳定的加盐哈希或不透明 ID
- 只把这个不透明 ID 作为
user_id发给 DeepSeek - 映射表只保存在内部身份系统
- 如果威胁模型变化,再谨慎轮换盐值
我见过有团队直接把邮箱当 user_id 发出去,后来做隐私评估时被安全和法务“连环追问”,补救成本远高于一开始就设计好映射方案。
三、网关策略设计:从治理到安全威胁模型
1. 策略即代码:谁来定、怎么管?
网关策略层,是 DeepSeek API 治理 真正落地的地方。这里的策略不只是“能不能调”,还包括:
- 哪些数据级别可以走哪些模型
- 哪些工作负载允许流式输出
- 哪些工具调用需要人工审批
- 哪些场景可以记录部分提示词,哪些只能记元数据
更稳妥的做法是把策略当代码管理:版本化、代码评审、自动化测试、分阶段灰度发布、可回滚。策略的所有权也不该只在平台团队手里,而是平台、安全、法务、业务共同参与。
2. 安全架构与威胁模型
一个面向 DeepSeek 的安全架构,至少要假设:
- 提示词里可能包含敏感数据
- 用户会尝试提示注入和越权
- Agent 可能错误调用工具或被诱导
- 日志一旦设计不当,本身就可能成为数据泄露源
OWASP《LLM 应用 Top 10》已经列出常见风险:提示注入、敏感信息泄露、供应链漏洞、数据与模型投毒、不当输出处理、过度代理能力、系统提示泄露、向量与嵌入弱点、错误信息、无边界资源消耗等。NIST 的 AI 风险管理框架(AI RMF)和生成式 AI Profile,则从 Govern / Map / Measure / Manage 四个维度组织风险工作。
2025 年 1 月,Wiz 披露了一起公开可访问的 DeepSeek ClickHouse 数据库事件,暴露了包含聊天记录、密钥、后端细节等在内的日志流;随后 DeepSeek 在被告知后完成了加固。事件本身不代表 DeepSeek 一定不安全,但它提醒企业:不要把任何 LLM 提供方的日志当成“可以随便放秘密”的地方。
3. 日志与审计:记录什么,不记录什么?
AI 网关可观测性要回答三件事:
- 平台是否健康可用?
- 使用是否安全合规?
- 成本是否在预期之内?
OpenTelemetry 已经发布了 GenAI 语义约定,用于描述生成式模型的请求、响应、指标、Trace、Span 和属性。尽量用兼容 OpenTelemetry 的方式打点,这样模型流量不会被锁死在某一家观测厂商里。
但在日志内容上,需要非常克制:
- 不记录原始密钥、凭证、私钥、Bearer Token
- 不记录未脱敏的 PII、受监管数据
- 在策略禁止的场景,不记录完整提示词
- 如果确实需要抓原始载荷用于排障或评估,要有临时审批、加密、严格 RBAC 和短期留存
审计事件则应写入防篡改系统,包含:
- 请求时间戳、调用服务身份
- 用户哈希或租户 ID、团队与成本中心
- 模型别名与实际提供方模型
- 策略版本、数据分级、DLP / Guardrail 动作
- Token 使用量、错误码或成功状态
- 是否触发回退、Trace ID、高风险请求的审批 ID
四、路由、回退与多模型策略:把 DeepSeek 放进“车队”里
1. 多提供方路由的思路
有了网关,DeepSeek 不再只是“一个单点集成”,而是可以放进一个 多提供方 LLM 车队 里。路由策略要写得清清楚楚、可测试:
- 哪些工作负载默认走 DeepSeek,哪些走其他提供方
- 哪些场景允许自动回退,哪些必须失败并告警
- 不同数据分级对应的模型能力和地域要求
- 不同团队的最大输入 / 输出 Token 限制
我自己的观察是:很多团队一开始只接了一个提供方,等到遇到 429 或区域合规问题,才匆忙补多提供方路由,结果改动面巨大。如果一开始就用别名 + 路由策略,后面会轻松很多。
2. 示例伪配置:思考模式与回退
思考模式说明:下面伪配置中的
mode字段是网关内部抽象。在转发给 DeepSeek 前,需要把它翻译成提供方支持的参数,比如{"thinking": {"type": "enabled"}}或{"thinking": {"type": "disabled"}},并只在合适的模型上应用reasoning_effort。
models:
enterprise-fast:
primary:
provider: deepseek
model: deepseek-v4-flash
mode: non_thinking
fallback:
- provider: approved_provider_a
model: fast-general
- provider: approved_provider_b
model: low-cost-general
enterprise-reasoning:
primary:
provider: deepseek
model: deepseek-v4-pro
mode: thinking
fallback:
- provider: approved_provider_a
model: reasoning-large
routes:
- match:
workload: support_summarization
data_classification: internal
model_alias: enterprise-fast
max_input_tokens: 120000
max_output_tokens: 2000
cache_strategy: prefix_reuse
log_policy: metadata_and_redacted_prompt
- match:
workload: legal_contract_review
data_classification: confidential
model_alias: enterprise-reasoning
require_approval: true
max_output_tokens: 4000
log_policy: metadata_only
dlp:
action_on_secret: block
action_on_pii: redact
retries:
max_attempts: 2
retry_on:
- 429
- 500
- 503
backoff:
type: exponential_jitter
initial_ms: 500
max_ms: 8000
do_not_retry_after_stream_started: true
circuit_breakers:
deepseek:
open_when:
error_rate_5m_gt: 0.10
p95_latency_ms_gt: 30000
half_open_after_seconds: 60
3. 429 与重试纪律
DeepSeek 文档中提到,当触发速率 / 并发限制时会返回 HTTP 429,并建议合理节流请求,必要时暂时切换到其他 LLM 提供方。网关如果不加控制,很容易在 429 时制造“重试风暴”。
更稳妥的做法包括:
- 使用带抖动的指数退避
- 在提供方返回重试头时予以尊重
- 对低优先级流量进行排队或丢弃
- 按工作负载设置不同的重试上限
- 对已经开始流式输出的请求不再重试
- 在重试预算耗尽时,优先对用户关键路径启用回退
五、成本控制与 Token 治理:架构问题,不只是财务问题
1. 成本失控的典型来源
LLM 成本上涨,往往不是因为“用的人多”,而是因为:
- 提示词越来越长,上下文无限堆
- 输出上限设置得极高,却很少真正用满
- RAG 场景重复塞入大量相同上下文
- Agent 死循环调用模型
- 开发者在后台跑大批量任务,却没人盯预算
DeepSeek 的定价基于输入 / 输出 Token,文档建议以模型返回的 usage 字段为准,因为不同模型的分词方式不同。这意味着:网关必须抓取并汇总 usage 数据,否则你只能在账单上“事后看结果”。
2. 成本与缓存看板要看什么
一个有用的 DeepSeek 上下文缓存 + 成本看板,至少应该包含:
- 总输入 Token
- 缓存命中输入 Token
- 缓存未命中输入 Token
- 输出 Token
- 思考 / 推理模式 Token 指标(如果有)
- 按模型别名与实际模型拆分的请求量
- 按团队、应用的成本
- 每次成功请求的平均成本
- 按产品功能拆分的成本
- 429 与回退比例
- 使用脱敏标识的高成本路由 Top N
- 预算消耗与剩余额度
有用户反馈,在引入缓存命中率监控后,通过调整系统提示词和 RAG 上下文顺序,把某些工作负载的输入 Token 成本压低了约 20%。
六、部署模式与实施蓝图:从 0 到 1 的路线
1. 部署模式选择:托管、自建还是 K8s 原生?
没有一个“万能最佳实践”,合适的 DeepSeek 企业部署模式 取决于:监管要求、团队规模、运维成熟度、延迟目标,以及你更看重托管控制平面,还是完全自建的可控数据路径。
常见选项:
- 托管网关:追求上线速度和内置控制能力,接受部分数据路径托管
- 自建 LLM 代理:需要内部控制,又想复用现成网关模式
- Kubernetes 原生网关:企业已经在用 Envoy、Kong、Gateway API 或 Service Mesh
- 完全自研:策略极其复杂、监管要求苛刻或内部集成需求特殊时才值得投入
2. 7 阶段实施蓝图
Phase 1:盘点与风险分级
梳理所有当前和计划中的 DeepSeek 用例:
- 应用名称与业务负责人
- 数据分级与用户群体
- 模型能力需求与预估 Token 量
- 是否需要流式 / 工具调用
- 合规约束、现有密钥与接入方式
产出:经过审批的用例清单与风险分级。
Phase 2:网关 MVP
搭建最小可上线的生产网关:
- 内部统一入口
- 身份认证与调用鉴权
- 提供方密钥隔离
- 基本路由到 DeepSeek
- 请求 ID 与 Token 使用采集
- 基础限流与仅元数据日志
产出:可承载低风险工作负载的 DeepSeek API 代理。
Phase 3:安全控制与日志策略
在 MVP 上叠加企业级安全能力:
- DLP 扫描与密钥检测
- 敏感字段脱敏
- Guardrails 与输出过滤
- 日志与留存策略
- 与 SIEM 集成
- 策略即代码的评审流程
产出:可承载内部 / 机密数据的安全审查通过网关。
Phase 4:路由与回退
增强弹性与可用性:
- 模型别名与 DeepSeek 优先路由
- 多提供方回退
- 熔断器与退避策略
- 429 处理与金丝雀路由
产出:可靠的多提供方 LLM 网关。
Phase 5:成本看板
引入 FinOps 能力:
- 按团队 / 应用的成本视图
- Token 预算与预警
- 缓存命中 / 未命中统计
- 异常成本峰值告警
- 分摊 / 展示报表
产出:可运营的 DeepSeek 成本治理体系。
Phase 6:生产加固
把平台打磨到“敢放心托管关键业务”的程度:
- 压测与流式场景专项测试
- 混沌测试与依赖扫描
- 网关高可用与备份恢复
- 事故预案与策略回滚机制
产出:通过生产就绪评审的 AI 平台。
Phase 7:治理与持续评估
进入长期运营阶段:
- 定期策略评审与模型迁移计划
- 提示词与响应质量评估
- 安全测试与供应商风险更新
- 审计证据导出与开发者赋能
产出:可持续演进的 DeepSeek API 治理计划。
七、常见踩坑:别在这些地方翻车
1. 典型错误清单
构建 DeepSeek API 代理 时,尤其要避开这些模式:
- 应用直接用共享密钥连 DeepSeek
密钥泛滥,无法统一治理,也很难做事后追责。 - 默认记录完整提示词
提示词里往往有密钥、客户记录、合同、源代码和受监管数据。 - 忽略流式与长连接行为
SSE 保活、部分响应和超时行为都需要专门测试。 - 把 OpenAI 兼容当成“企业就绪”
兼容只解决接入问题,不解决身份、策略、审计、成本和风险。 - 没有租户隔离
多租户产品需要独立的元数据、缓存策略、审计轨迹和策略边界。 - 没有回退方案
提供方可能返回 429、500、503 或延迟飙升,关键业务需要优雅降级。 - 没有模型版本策略
DeepSeek 文档会给出旧模型的下线日期,用网关别名可以降低迁移风险。 - 缺乏成本预算控制
长上下文和 Agent 循环很容易制造“惊喜账单”。 - 对 429 进行激进重试
会放大提供方压力,让故障更难恢复。 - 允许开发者用个人 API Key
直接绕过企业日志、DLP、预算和供应商审查。
八、把这一套方法留在手边
如果你只记住一件事,那就是:DeepSeek 网关 / 代理架构不是“可有可无的中间层”,而是企业能不能安全、可控、可审计地用好 LLM 的关键基础设施。很多团队是踩完坑才回头补网关,不如一开始就按网关思路设计。
这套判断和实施步骤,在不同云厂商、不同 LLM 提供方之间都能复用。等你下次要评估“要不要上新模型、要不要多接一个提供方”时,翻回来看这份架构和清单,会比随口问几个人靠谱得多。
常见问题
Q:企业在什么阶段必须上 DeepSeek 网关,而不是继续直连?
A:一旦 DeepSeek 从“小范围试验”进入“多团队、多应用的生产使用”,就应该上网关。原因是直连模式下,密钥管理、成本控制、日志合规和多租户隔离几乎无法统一治理,风险会随规模指数级放大。建议的做法是:在第一个跨团队或面向外部用户的用例上线前,就搭好最小可用网关(统一入口、鉴权、Token 统计和基础限流),后续再逐步叠加 DLP、回退和成本看板。
Q:DeepSeek 的 OpenAI 兼容接口,直接给应用用可以吗?
A:不推荐直接暴露给应用,尤其是在企业环境。虽然 DeepSeek 的 OpenAI 兼容接口可以让现有 SDK 直接可用,但如果应用直连,你就失去了统一的策略控制和审计能力。更好的做法是:让应用指向内部网关的 OpenAI 兼容地址,由网关注入 DeepSeek 密钥、执行 DLP 和限流,并记录必要的审计元数据。这样既保留了兼容性,又能满足安全和合规要求。
Q:如何判断一条 DeepSeek 调用是否“成本合理”?
A:可以从三个维度判断:Token 使用量、业务价值和是否命中缓存。比如,一条内部知识问答请求,如果输入 Token 超过几万、输出上限也设得很高,却只是回答一个简单问题,那就明显不合理。建议在网关层设置每条路由的最大输入 / 输出 Token,记录缓存命中率,并在成本看板中按功能和团队展示“平均每次调用成本”。当某个功能的单次成本远高于同类场景时,就该触发优化或评审。
Q:流式输出会不会让安全和合规变得更难?
A:会更复杂,但不是不能管。流式输出意味着内容是分片返回的,传统“拿到完整响应再做审核”的模式不再适用。原因在于:用户可能在前几个分片就看到敏感内容,或者连接在中途被中断。可操作的建议是:在网关层对高风险场景默认关闭流式;对必须流式的场景,采用分片级别的关键字 / 规则检测,并在模型侧通过系统提示减少敏感内容生成,同时设置合理的超时和重试策略,避免长连接拖垮网关。
Q:什么时候应该自建 DeepSeek 代理,而不是用托管 AI 网关?
A:当你对数据路径、策略逻辑和内部集成有很强的定制需求时,就该考虑自建。比如,需要所有流量都走内网、必须与现有 Service Mesh、内部身份系统和 SIEM 深度集成,或者监管要求你完全掌控日志和策略执行环境。判断标准是:如果托管网关已经能满足 80% 以上需求,且合规允许托管数据路径,可以先用托管方案;当剩下的 20% 差距直接影响关键业务或审计通过率时,再投入资源自建,并复用现有的网关模式和策略设计。


