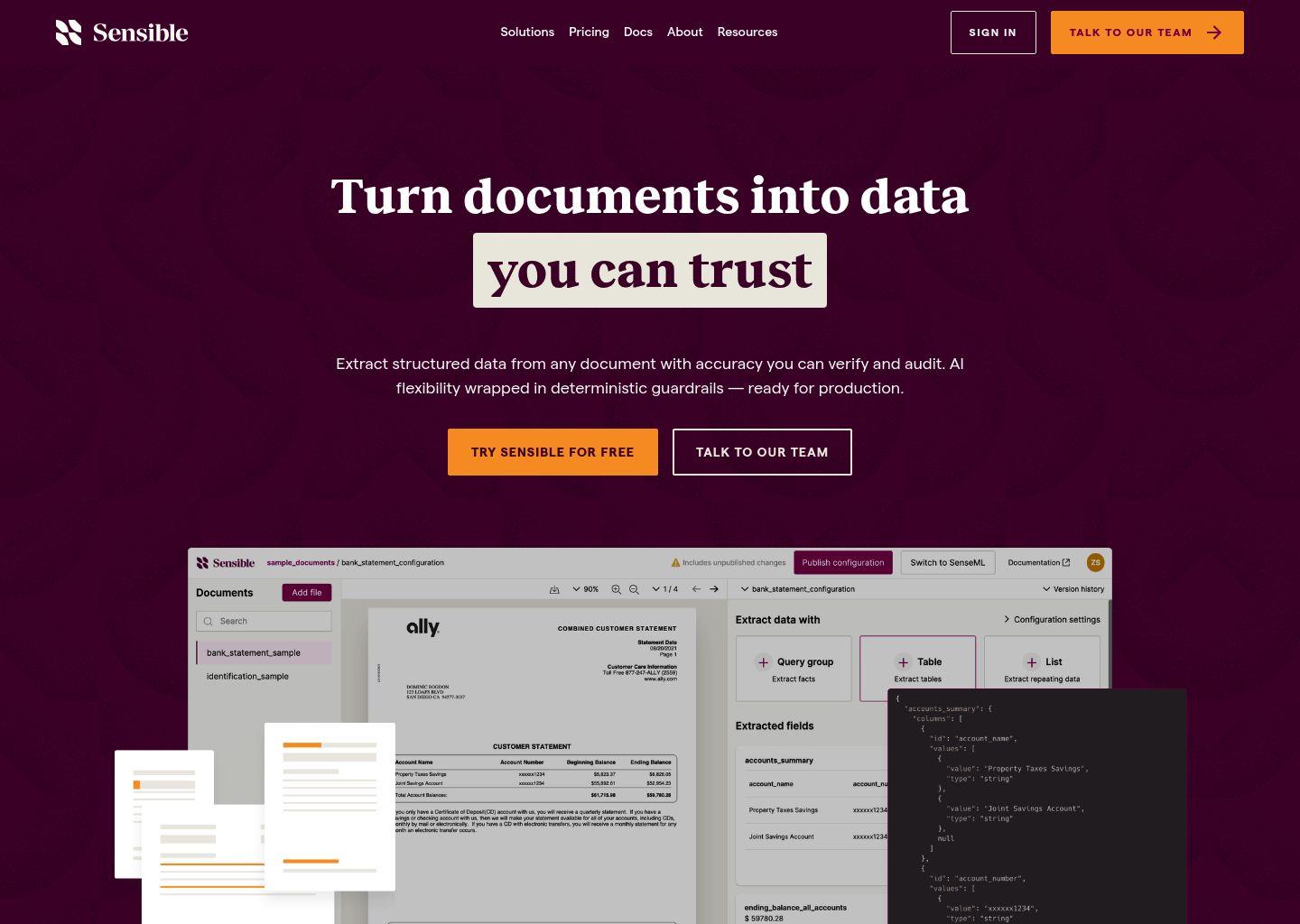
产品详细介绍
Sensible 是一款专注于“从非结构化文档中提取结构化数据”的文档抽取 API,面向需要大规模处理发票、报表、保单、金融和合规文档的企业团队。它通过将传统布局解析与大语言模型(LLM)抽取相结合的混合架构,为复杂、多变格式的文档提供生产级的数据提取能力。
核心能力与特点
-
多格式文档支持
Sensible 支持从多种常见业务文档中抽取数据,包括但不限于:- PDF 文档(扫描件与电子 PDF)
- 图片类文档(如拍照的账单、证件、票据)
- 电子表格(如 Excel、导出的对账单等)
能够处理包含复杂表格、密集字段和多栏布局的文档场景。
-
混合架构:规则 + LLM 抽取
Sensible 并非依赖单一 OCR 或模板,而是采用:- 布局驱动的确定性方法:根据文档结构、表格和字段位置进行高精度解析;
- 针对性 LLM 抽取:在规则难以覆盖或格式高度不一致的“疑难区域”使用大模型进行补充抽取;
- 文本预处理与清洗:对 OCR 结果进行强化处理,减少噪点和识别错误;
- 客户级定制配置:根据具体业务文档类型和字段需求进行配置,而非“一刀切”的通用模板。
这种混合方式在准确率、稳定性和可控性之间取得平衡,适合真正落地到生产环境。
-
结构化输出与字段级验证
Sensible 的输出是严格模式化的结构化数据,支持:- 按预定义 Schema 输出字段(如发票号、供应商信息、行项目、金额、税率等);
- 每个字段附带置信度信号,便于下游系统判断是否需要人工复核;
- 输出可直接进入财务系统、风控系统、合规系统或自建业务数据库,减少中间清洗环节。
-
适配多行业、多场景
Sensible 针对多种典型业务文档场景进行了优化,包括:- 财务与会计:发票、银行对账单、工资单、税表等;
- 保险与风险管理:loss runs、ACORD 表单、保单、理赔相关文件等;
- 房地产与金融交易:投资说明书、成交披露文件、租金清单等;
- 物流与供应链:运价确认、提单、运单、发票等;
- 医疗与支付方:EOB(权益说明)、保单、支付方确认等。
同时也支持身份证件、驾照、公共事业账单等身份与地址验证类文档的快速解析。
-
生产级可靠性与合规性
Sensible 面向生产环境设计,强调安全与合规:- 通过 SOC 2 认证,满足严苛的安全与隐私要求;
- HIPAA 合规,可安全处理医疗与健康相关敏感数据;
- 提供审计追踪能力,便于监管合规和内部审计;
- 支持在高并发场景下的实时或准实时处理,如实时银行对账单解析、即时保单页面解析等。
-
“足够好 + 人工复核”的自动化理念
Sensible 强调“混合自动化 + 必要人工复核”的实践路径:- 通过高覆盖率自动抽取,显著减少纯手工录入;
- 利用字段置信度和审计轨迹,将人工精力集中在高风险或低置信度字段;
- 相比追求“完美通用模型”或完全手工处理,这种方式更适合企业快速上线并持续优化。
-
专家团队与方案支持
Sensible 提供解决方案工程师团队,可协助:- 评估企业现有文档流程与数据结构;
- 设计字段 Schema 与抽取策略;
- 配置和调优特定文档类型的解析逻辑;
- 指导与现有系统(如 ERP、财务系统、风控平台)的集成落地。
简单使用教程
以下为基于 Sensible 文档抽取 API 的简要上手流程,帮助你从零开始构建一个文档自动化抽取流程。
步骤一:注册账号并获取 API 访问
- 访问官网 sensible.so,注册企业账号或申请试用。
- 在控制台中创建项目,获取对应的 API Key 或访问凭证。
- 根据文档类型(如发票、银行对账单、保单等)选择或创建相应的解析配置/模板(Schema)。
步骤二:准备待解析文档
- 将需要抽取的文档整理为:
- PDF 文件(扫描件或电子版);
- 图片文件(JPG、PNG 等);
- 或表格文件(如 XLSX)。
- 确保文件清晰可读,避免严重模糊、遮挡或旋转;如为批量处理,可先在本地或存储服务中统一管理文件路径或 URL。
步骤三:调用文档抽取 API
- 在后端服务中集成 Sensible 提供的 API(可使用常见语言如 Python、Node.js、Java 等)。
- 通过 HTTPS 请求将文档文件或文件 URL 发送至 Sensible 的解析端点,并指定:
- 使用的文档类型或解析配置 ID;
- 需要返回的字段集合或 Schema 名称;
- 可选的回调地址(用于异步处理)。
- 等待 API 返回结构化结果,一般为 JSON 格式,包含字段值与置信度信息。
步骤四:处理与校验抽取结果
- 在你的业务系统中接收 API 返回的 JSON 数据。
- 根据字段的 置信度分数 设置自动通过或人工复核规则,例如:
- 高置信度字段直接写入数据库或业务系统;
- 低置信度字段推送到人工审核界面进行确认或修正。
- 将最终确认的数据用于后续流程,如:记账、对账、风控评分、合规检查、报表生成等。
步骤五:持续优化与扩展场景
- 根据实际使用中遇到的文档变体和错误案例,调整:
- 字段 Schema;
- 解析配置和规则;
- 人工复核阈值。
- 与 Sensible 解决方案工程师沟通,针对复杂文档(如高度非标准化的报表、行业特定表单)进行专项优化。
- 在初始场景稳定后,将同一套能力扩展到更多文档类型,如从发票扩展到工资单、税表、保单、物流单据等,实现更大范围的文档自动化。
通过以上步骤,你可以快速搭建一个以 Sensible 为核心的文档数据抽取流程,在保证合规与可审计的前提下,大幅减少手工录入和重复性文档处理工作。