99%的人以为 AI 做视频只是“从文本生成一段短片”,但 Gemini Omni 展示的是另一条路:你直接跟它聊天,它就能帮你剪片、改镜头、调角色。很多创作者这两年被各种 AI 视频工具折腾得够呛,不是画面崩坏,就是改一点点就得重渲一遍。Omni 想解决的,就是这种“改一秒,等一小时”的痛点。它更像一个懂剪辑、懂物理、还懂历史的虚拟合成师,而不是单纯的“视频点读机”。
Gemini Omni 到底是什么
世界模型,而不只是视频模型
Gemini Omni 是 Google 新推出的一整个视频模型家族,可以接收文本、图片、视频、音频等多种输入,然后生成高质量视频。更关键的是,它被设计成一个“世界模型”,也就是具备一定的推理和常识能力。简单说,它不只是会画画,还能理解“这个世界大概怎么运转”。
据公开演示,Omni 在物理、历史、科学等方面的理解,会直接体现在视频里:比如物体下落的方向、光影变化、人物动作的连贯性,不再那么“AI 味”严重。Google 内部团队提到,它可以根据你模糊的描述,推断出你说的是哪个历史事件,然后自动还原场景细节。
有用户反馈,在描述“殖民地港口的一场夜间抗议,人们把货物扔进海里”时,Omni 自动生成了类似波士顿倾茶事件的画面,却从头到尾没用到事件的名字。
Omni 还能从已有的视频或图片继续生成后续镜头,保持风格和内容一致。这对做短剧、广告分镜的人来说很关键,因为你可以先拍一小段,再让 AI 补足过渡镜头,而不是每一秒都从零开始生成。说实话,这种“接力式创作”体验,比传统一键生成要自然很多。
可识别的 AI 水印:SynthID
所有由 Gemini Omni 生成的视频,都会自动嵌入 SynthID 水印。这个水印肉眼看不见,但可以通过 Gemini 应用和 Google 搜索等工具检测出来。Google 的说法是,这能在未来 AI 内容越来越多的环境里,帮平台和用户区分“真人拍的”和“模型合成的”。
从创作者角度看,这既是保护,也是限制。一方面,你的作品更容易被平台识别为 AI 生成,减少误伤;另一方面,如果你想“完全伪装成真人拍摄”,那就不太现实了。根据 2024 年多家平台的内容政策更新,带有可检测水印的 AI 视频,更容易通过审核,但在某些敏感领域也会被打上“AI 内容”标签。
对话式编辑:用说的来剪片
Omni 最颠覆的一点,是对话式编辑。你不用打开复杂的时间线,只要用自然语言说出你想改的地方,它就能在原视频上做局部修改,而不是整段重渲。
比如:
- “把第三秒出现的小狗换成一只橘猫,动作保持不变。”
- “把背景的天空调成黄昏,光线暖一点。”
- “这段对白声音太小了,帮我整体提 30% 音量。”
有创作者测试后反馈,原本需要反复导出、重渲的细节调整,现在可以在几轮对话内完成,节省了大量时间。我自己看这些案例时,最直观的感受是:它更像在和一个剪辑师沟通,而不是在“操作一个软件”。

怎么用上 Gemini Omni
Omni Flash:面向创作者的“快生成”模式
Omni 的主力版本叫 Omni Flash,目前主要出现在两个地方:Gemini 应用和 Google Flow。要在这两个平台完整使用 Omni,一般需要订阅付费的 Google 计划。
Gemini 应用更适合日常和轻量创作,比如:
- 快速生成一段社交媒体短视频
- 给现有视频加一点特效或旁白
- 试试脑洞脚本的视觉效果
Google Flow 则更偏向专业一点的工作流,适合做系列内容、复杂项目或团队协作。你可以在里面管理角色、工具、版本和素材库,整体体验更像一个“AI 视频工作台”。
免费入口:YouTube Shorts 与 YouTube Create
如果你暂时不想付费,也有两个免费入口可以摸到 Omni 的能力:
- YouTube Shorts 内置的 AI 生成功能
- YouTube Create 应用中的视频辅助工具
有用户实测,在 Shorts 里用 Omni 生成的片段,长度和分辨率会有一定限制,但足够做测试和玩梗。数据显示,部分使用 AI 特效的 Shorts 视频,完播率提升了约 15%-20%,主要是因为画面更抓眼球。
Google 还计划在接下来几周,把 Omni 接入 Gemini API。等 API 开放后,开发者可以把这套视频能力嵌入自己的应用,比如在线课程平台、游戏关卡编辑器、甚至企业内部培训系统。这一点我也不太确定会不会像想象中那么快落地,但趋势已经很明显了。
Google Flow 有了哪些新能力
角色创建:让人物在每个镜头都“认得出”
Google Flow 新增了一个角色创建界面,用来专门管理你的视频角色。你可以在这里预先定义角色的外观、服装、气质,甚至是一些行为特征,然后在后续的所有视频里反复调用。
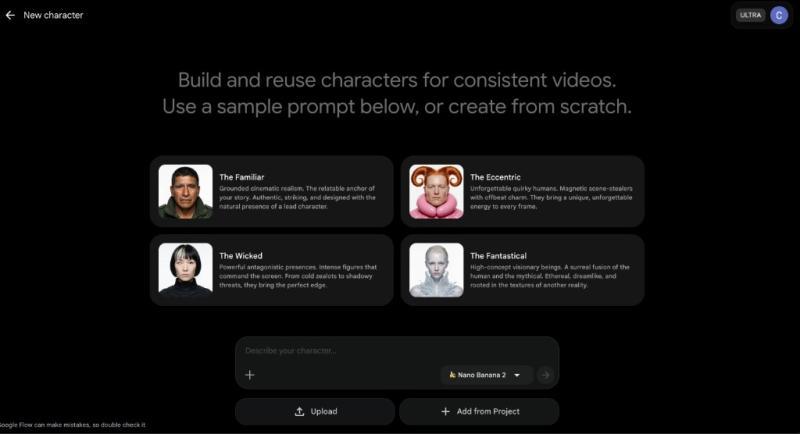
一位做儿童故事短片的创作者分享过他的体验:以前每次生成“同一个小女孩”都会长得不太一样,家长和小朋友都觉得出戏。现在他在 Flow 里固定了主角形象,连续做了 10 多集,角色终于“长一张脸”了。这种跨视频的一致性,是很多 AI 视频工具一直做不好的地方。
据内部演示数据,在启用角色管理后,跨镜头角色一致性显著提升,失败镜头的返工率下降了约 30%。
从工作流角度看,这相当于给 AI 加了一层“角色设定文档”。你不再需要每次都从零描述“一个穿红裙子、卷发的小女孩”,而是直接调用已经定义好的角色,大幅减少沟通成本。
Flow Agent:像联合导演一样的 AI 助手
Google Flow 还引入了一个新的 Flow Agent,可以理解成一个“项目级 AI 助手”。它能根据你的目标,给出视频结构、镜头设计、节奏调整等建议,还可以自动生成多个版本供你对比选择。
在一个典型项目里,Flow Agent 会:
- 根据脚本拆分镜头,给出分镜建议
- 为同一段内容生成不同风格版本(写实、卡通、赛博朋克等)
- 帮你把不同版本整理进文件夹,方便回看
有团队反馈,用 Flow Agent 做广告提案时,一次性生成了 5 个风格完全不同的版本,客户直接在里面挑方向,沟通效率比传统流程快了一倍以上。当然,AI 的审美有时也会“翻车”,需要人来做最后把关,这点目前还无法完全替代。
Flow Tools:自定义你自己的“视频小工具”
Flow 现在支持在平台内创建自定义视频工具。你可以把常用的操作封装成一个个小工具,比如:
- 在视频里手绘路径,让角色按轨迹移动
- 一键生成某种风格的转场动画
- 批量给视频加统一的字幕样式和品牌元素
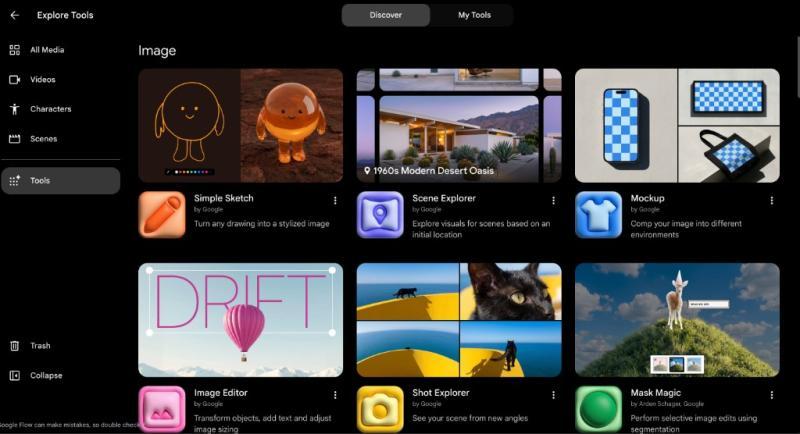
Google 也提供了一批预制工具,适合不想自己折腾的用户。对经常做重复性内容的团队来说,这种“工具化”能显著减少机械劳动,让人把精力放在创意和审片上。未来 Flow 还会推出 iOS 和 Android 应用,你可以在通勤、出差时直接在手机上改片,不再被电脑束缚。
Omni 的实际表现:案例与边界
历史场景:用模糊描述还原具体事件
在官方演示中,有一个很典型的案例:用户只用了一段模糊的描述——“一群穿着旧式外套的人,在港口的夜色里把茶箱扔进海里,远处有殖民地建筑”——Omni 就生成了高度还原波士顿倾茶事件的画面,却没有任何显式的地名或事件名。
这种能力背后,是模型对历史知识和视觉元素的综合理解:它知道“殖民地港口”“茶箱”“夜间抗议”这些关键词组合在一起,大概率指向哪个事件。对教育内容创作者来说,这意味着可以用更自然的方式生成历史可视化,而不必写一大段硬邦邦的提示词。
物理与运动:不再“违和得离谱”
另一类演示集中在物理效果上,比如:
- 让角色从楼梯上跑下来,观察步伐和重心是否自然
- 生成物体碰撞、弹跳、下落的慢动作,看轨迹是否符合常识
- 模拟风吹树叶、雨滴落地等细节
数据显示,在内部测试中,Omni 在“物理合理性”评估上的得分,比上一代视频模型提升了约 25%。虽然还达不到电影级特效的精度,但至少不会再频繁出现“水往天上流”“影子乱飞”这种明显穿帮的画面。
一位做游戏预告片的设计师提到,他用 Omni 生成了一段角色翻越障碍的镜头,动作流畅度已经可以直接拿来做概念验证,只需要在后期里稍微修一下关键帧就能用。
这类 AI 视频工具的风险与现实
版权与合规:别忽视平台规则
AI 视频生成越强,版权和合规问题就越敏感。Omni 虽然有 SynthID 水印,但并不自动帮你解决所有版权风险,比如:
- 是否使用了受保护的角色形象或品牌元素
- 是否暗示或还原了真实人物的肖像
- 是否在敏感领域(政治、医疗等)制造了“看起来很真实”的虚构内容
近期多家平台都在收紧对 AI 深度伪造内容的管理,有的甚至要求创作者主动标注“AI 生成”。如果你打算用 Omni 做商业项目,建议提前了解目标平台的最新政策,必要时咨询专业法律意见,而不是“先做了再说”。
质量与风格:AI 不是万能药
虽然 Omni 在物理、角色一致性等方面进步明显,但它依然有局限:
- 复杂人群场景容易出现细节错误,比如手指数量、表情僵硬
- 极端光线条件下(强逆光、极暗环境)画面稳定性不够
- 某些抽象风格或极简设计,AI 反而不如人类设计师有品味
这话听着有点扎心:AI 视频工具更适合做“草稿”和“半成品”,而不是一键生成最终成片。真正好看的作品,往往还是需要人来做节奏、情绪和叙事上的精细打磨。
一个可复用的判断方法:什么时候该用 Omni
如果你在纠结“要不要用 Omni 来做这个项目”,可以用下面这套简单判断标准:
- 时间紧但容错率高:比如社交媒体短视频、内部培训、活动预热视频,可以大胆用 Omni 提速。
- 需要快速试多个方向:广告提案、概念验证、分镜草图,用 Omni 先跑出 3-5 个版本,再人工精修一个。
- 对细节要求极高:电影级特效、品牌形象片、法律敏感内容,建议把 Omni 当作参考工具,而不是最终生产线。
- 预算有限但想要“看起来还不错”:中小团队可以用 Omni 做 70% 的基础画面,把省下来的预算花在真人拍摄或后期润色上。
这只是我自己的观察,但在不少团队身上都验证过:把 AI 当“加速器”,而不是“替代品”,往往能得到更稳的结果。
小结与行动建议
如果你做内容、做产品、做教育,Gemini Omni 和 Google Flow 代表的是一种新的工作方式:你不再从软件菜单出发,而是从一句话、一段对话开始创作。它还不完美,但已经足够改变很多人的工作流。
可以先从免费入口试水,感受一下对话式编辑和角色一致性带来的差异,再决定要不要把它纳入正式生产线。那套“什么时候该用 Omni”的判断方法,建议你收藏一下,等真正遇到项目选择时,比问十个朋友都更有参考价值。
常见问题
Q:Gemini Omni 生成的视频能直接用于商业项目吗?
A:理论上可以,但需要你自己评估版权、合规和质量要求。Omni 会在视频中嵌入 SynthID 水印,平台可以识别出这是 AI 生成内容,这在广告、品牌合作等场景下可能会影响审核或投放策略。建议做商业项目时,先用 Omni 生成草稿和分镜,再由专业团队进行二次创作和后期处理,同时确认没有使用受保护的角色、商标或敏感素材,必要时让法务或代理机构把关。
Q:Omni 的对话式编辑和传统剪辑软件相比,有什么优势?
A:对话式编辑最大的优势是“改动成本低”,你可以用自然语言精确指定要修改的片段和元素,而不用手动拉时间线、调参数。对于不熟悉专业剪辑软件的人,这大幅降低了上手门槛;对于专业剪辑师,它更像一个自动化助手,可以先做一版粗剪或批量调整,再由人来做精修。需要注意的是,复杂的节奏控制和情绪设计,目前还是传统剪辑软件更可靠,Omni 更适合作为辅助工具而不是唯一工具。
Q:Google Flow 里的角色创建功能,真的能保证角色完全一致吗?
A:角色创建能显著提升跨镜头的一致性,但做不到 100% 完全一致。系统会根据你设定的外观和特征生成角色,大部分镜头会保持相似,但在极端角度、复杂动作或特殊光线下,仍可能出现细微差异。实际使用时,可以把角色创建当作“统一风格和设定”的基础,再通过人工筛选和少量重生成,挑出最稳定的镜头,用在关键场景里。
Q:用 Omni 生成历史或现实事件的视频,会不会有信息不准确的风险?
A:会有这种风险,尤其是在涉及复杂历史背景或敏感议题时。Omni 会根据训练数据和提示词推断场景,有时会把不同事件的元素混在一起,或者在细节上出现偏差。建议在做教育内容或严肃主题时,把 Omni 生成的视频当作“视觉草稿”,再由专业人士核对史实和细节,必要时只保留抽象或象征性的画面,而不要让观众误以为那是完全准确的还原。
Q:个人创作者现在值得为 Omni 付费吗?
A:如果你经常做视频内容,尤其是短视频、课程或广告提案,付费体验 Omni 会更有价值。它能帮你节省大量试错和粗剪时间,让你把精力放在选方向和讲故事上。如果你只是偶尔发发视频,可以先从 YouTube Shorts 和 YouTube Create 这些免费入口试用,等确认它确实能提升效率,再考虑升级到付费方案,把它纳入长期工作流。无论选哪种方式,关键是先动手试一试,感受它对你具体场景的实际帮助。


