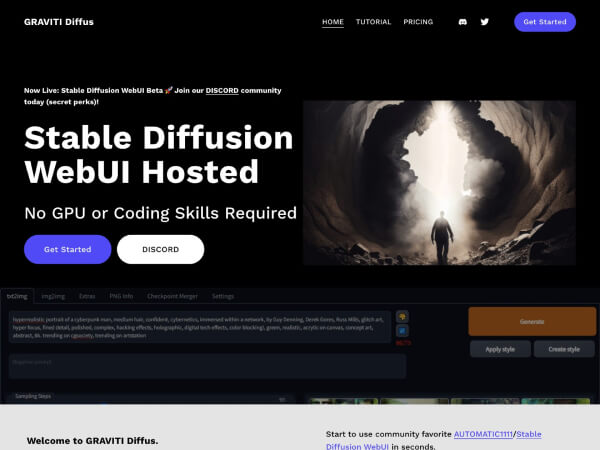
产品详细介绍
Diffus 是一款专业级 AI 图像生成平台,主打“高精度控制 + 海量模型 + 浏览器即用”。用户无需自备昂贵 GPU 硬件,只需打开浏览器,即可调用平台上的 70,000+ AI 模型(包括各类 Checkpoint 与 LoRA),快速生成高质量图片,适用于插画、概念设计、电商视觉、品牌海报、角色设定等多种创意场景。
平台的核心优势在于对“可控性”和“专业度”的强调:
-
海量模型资源(70,000+)
- 覆盖写实、二次元、插画、像素风、摄影风格等多种视觉类型。
- 支持多种 Checkpoint 与 LoRA 组合,满足细分风格与行业需求。
- 支持上传和使用你自己的模型,打造独一无二的创作风格。
-
高级图像控制工具
- ControlNet:通过草图、姿势、深度图等条件控制生成结果,更精确地还原构图与动作。
- Inpaint(局部重绘):只修改图片指定区域,适合修图、替换元素、微调细节。
- ADetailer & 人脸修复:自动优化人脸结构与表情,提升面部清晰度与自然度,适合角色立绘、肖像、写真类创作。
-
专业级创作体验
- 面向设计师、插画师、品牌与内容团队,提供专业级图像生成能力。
- 支持精细参数调节(如分辨率、步数、采样器、提示词权重等),帮助用户在“速度”和“质量”之间找到最佳平衡。
- 通过浏览器即可使用,无需本地安装复杂环境,也不需要购买或维护高性能显卡。
-
随时随地创作
- 只要有网络和浏览器,就可以在任何设备上进行图像生成与编辑。
- 适合远程团队协作、自由职业者与多地办公场景。
Diffus 致力于为创作者提供“专业但不复杂”的 AI 图像生产力工具,让更多人可以以更低门槛获得专业级视觉输出能力。
简单使用教程
以下为基于浏览器的基础使用流程示例,实际界面以官网为准:
-
访问官网并注册账号
- 打开浏览器,访问网址:
https://www.diffus.graviti.com。 - 点击页面中的“Get started”或类似按钮。
- 使用邮箱注册账号,完成验证并登录。
- 打开浏览器,访问网址:
-
选择或加载模型
- 在模型库中浏览或搜索你需要的风格模型(如写实、二次元、插画等)。
- 选择合适的 Checkpoint 或 LoRA,应用到当前会话。
- 如有自定义模型,可在“上传模型”入口上传并加载。
-
输入提示词并设置参数
- 在提示词(Prompt)输入框中,描述你想要生成的画面内容、风格和细节。
- 可在负面提示词中写入不希望出现的元素。
- 根据需要调整分辨率、步数、采样器等基础参数。
-
使用高级控制工具(可选)
- 使用 ControlNet:上传草图、姿势参考或结构图,启用 ControlNet,以更精确控制构图与姿态。
- 使用 Inpaint:上传已有图片,框选需要修改的区域,输入新的提示词,只对该区域进行重绘。
- 人脸优化:在生成或编辑人物时,启用 ADetailer 或人脸修复选项,自动提升面部细节与表情自然度。
-
生成与微调
- 点击“生成”按钮,等待系统完成图像生成。
- 若结果不满意,可调整提示词、参数或更换模型后再次生成。
- 对局部不满意的区域,可使用 Inpaint 进行局部修正,而无需整体重做。
-
导出与应用
- 在预览中确认最终图像质量与细节。
- 选择合适的格式与分辨率进行下载。
- 将生成的图片用于设计稿、社交媒体内容、电商页面、品牌物料等实际项目中。
如需更深入的功能说明或商业合作,可通过页面提供的邮箱 contact@diffus.me 与团队联系。