最后校验时间:2026 年 4 月 1 日
POST /chat/completions 是 DeepSeek 用于对话生成的核心接口。你需要提供 model 和 messages 数组,接口会返回完整的对话补全结果,或以 SSE 方式流式返回增量片段。它支持结构化 JSON 输出、工具调用、推理输出,以及无状态的多轮对话。
仅在 Beta 环境(base_url="https://api.deepseek.com/beta")下,才支持 Chat Prefix Completion 和严格模式工具调用等实验特性。本文是面向 chat-deep.ai 用户的独立使用指南,并非官方 DeepSeek 文档。更宽泛的 API 概览可参考我们的 DeepSeek API 总览文档。
快速要点:如果你已经能发起一次 DeepSeek API 调用,那么
/chat/completions将是你最常用的接口。推荐从model="deepseek-chat"和一个简短的messages数组开始;需要流式增量输出时加上stream: true;需要结构化 JSON 时设置response_format={"type":"json_object"};需要函数式工具调用时添加tools和tool_choice。如果要使用 Beta 的前缀补全或严格工具模式,请把 SDK 的 base URL 切换为https://api.deepseek.com/beta。
快速参考 / 最小请求
最小必需字段:
- 接口路径:
POST /chat/completions - 请求体必填字段:
model、messages - 常用 SDK 基础地址:
https://api.deepseek.com - OpenAI 兼容提示:
https://api.deepseek.com/v1也可作为兼容 base URL,但v1不是 模型版本号 - 推荐入门模型:
deepseek-chat
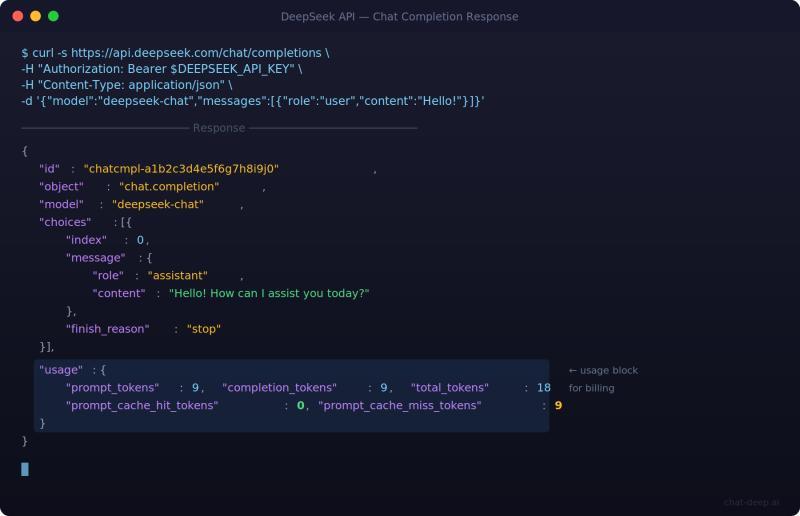
最简 cURL 示例
curl https://api.deepseek.com/chat/completions
-H "Content-Type: application/json"
-H "Authorization: Bearer $DEEPSEEK_API_KEY"
-d '{
"model": "deepseek-chat",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
],
"stream": false
}'
最简 Python 示例
from openai import OpenAI client = OpenAI( api_key="", base_url="https://api.deepseek.com", ) response = client.chat.completions.create( model="deepseek-chat", messages=[ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "Hello!"} ], ) print(response.choices[0].message.content)
Node.js 示例(可选)
import OpenAI from "openai"; const client = new OpenAI({ apiKey: process.env.DEEPSEEK_API_KEY, baseURL: "https://api.deepseek.com", });
const response = await client.chat.completions.create({ model: "deepseek-chat", messages: [ { role: "system", content: "You are a helpful assistant." }, { role: "user", content: "Hello!" } ] });
console.log(response.choices[0].message.content);
以上示例使用了 DeepSeek 当前的 OpenAI 兼容模式:base_url="https://api.deepseek.com" 与标准 /chat/completions 路径。官方也允许使用 /v1 作为兼容前缀,但该版本号与具体模型版本无关。
接口用途概览
官方对 POST /chat/completions 的描述是“为给定对话创建模型回复”。在实际开发中,它是大多数应用的主战场:
- 普通聊天对话
- 结构化 JSON 生成
- 函数式工具调用(tool calls)
- 由应用端维护历史的多轮对话
如果你在构建聊天机器人、智能代理或应用内 AI 功能,通常都会围绕这个接口扩展。更简单的落地示例可以参考我们的 DeepSeek 聊天机器人搭建指南和 Web / SaaS 集成指南。
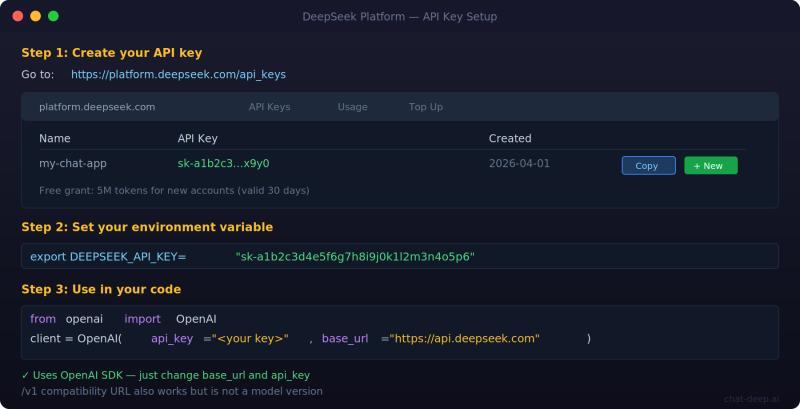
接口地址、鉴权与 base URL
原始 HTTP 路径:
POST https://api.deepseek.com/chat/completions
SDK 中常用配置:
base_url="https://api.deepseek.com"
官方快速上手文档也允许使用 https://api.deepseek.com/v1 以兼容 OpenAI 风格工具链,但明确指出 v1 与模型版本无关。鉴权方式为在请求头中携带 DeepSeek API Key,使用 Bearer Token。
DeepSeek 还提供 Anthropic 兼容接口,具体配置可参考我们关于 DeepSeek Anthropic API 的专门指南。
必填请求字段
从当前 schema 看,真正必填的只有两个字段:
modelmessages
messages 至少包含一条消息;model 目前可选值主要是 deepseek-chat 或 deepseek-reasoner。其他字段都是在此基础上的可选增强。
本文对字段的拆解基于当前的请求 schema、JSON 输出指南、函数调用指南、思维模式(Thinking Mode)指南以及 Chat Prefix Completion 指南。
消息角色说明
messages 不只是简单的文本历史,而是带角色的消息数组。DeepSeek 定义了四种角色:
systemuserassistanttool
其中:
system与user主要承载指令和提示词assistant承载模型回复、生成的工具调用,或 Beta 前缀补全的前缀内容tool则由你的应用返回工具执行结果,必须包含对应的tool_call_id
schema 还允许在 system、user、assistant 上使用 name 字段;在 Beta 的前缀补全中,最后一条 assistant 消息可以带 prefix: true。
模型选择:deepseek-chat 与 deepseek-reasoner
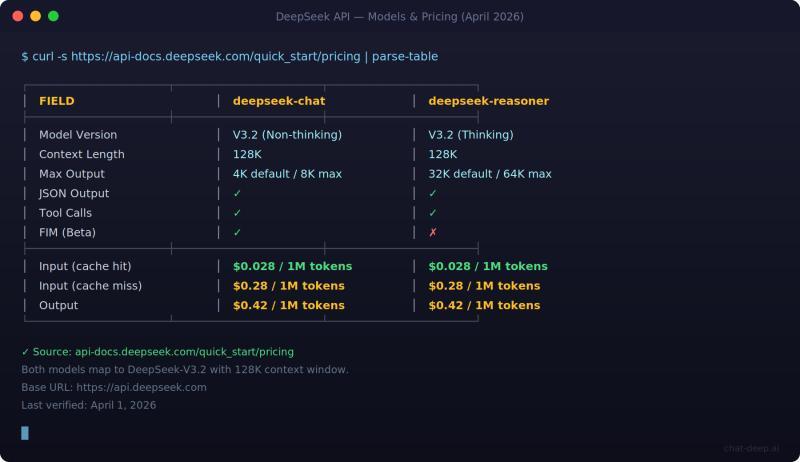
截至 2026 年 4 月 1 日,官方 Models & Pricing 页面显示:deepseek-chat 与 deepseek-reasoner 都映射到 DeepSeek-V3.2,支持 128K 上下文窗口。
deepseek-chat:普通聊天模式deepseek-reasoner:开启思维模式(Thinking Mode)的推理模型
默认 / 最大输出长度也不同:
deepseek-chat:默认 4K,最大 8Kdeepseek-reasoner:默认 32K,最大 64K
目前启用推理行为有两种方式:
- 直接使用
model="deepseek-reasoner" - 继续使用
model="deepseek-chat",并通过thinking参数开启思维模式
在 OpenAI SDK 中,官方建议将 thinking 放在 extra_body 中传递,例如:
response = client.chat.completions.create( model="deepseek-chat", messages=[{"role": "user", "content": "Solve 31 * 47"}], extra_body={"thinking": {"type": "enabled"}} )
需要注意的几个点:
- 新版 Thinking Mode 与 Models & Pricing 文档都说明 V3.2 模型支持工具调用,但旧版
deepseek-reasoner指南仍写着“不支持函数调用”。实践中建议以新版文档为准,同时在自己客户端中对deepseek-reasoner的工具调用流程做充分测试。 - 在思维模式下,
temperature、top_p、presence_penalty、frequency_penalty不再生效;logprobs与top_logprobs会直接触发错误。因此deepseek-reasoner不是简单的“更聪明的 chat”,而是控制项语义也发生了变化。
实用的可选字段
常用可选参数的实际含义:
max_tokens:限制最大生成 token 数,总输入 + 输出仍受模型上下文窗口限制temperature、top_p:都可用,但官方建议只调其中一个stop:可为字符串或字符串数组,最多 16 个停止序列logprobs=true:返回 token 级对数概率top_logprobs:每个位置最多返回 20 个备选 token 概率
对大多数生产应用,推荐默认策略:
- 明确设置
max_tokens - 除非有明确需求,不要频繁调整
temperature - 仅在需要严格边界时使用
stop - 将
logprobs留给打分或调试场景,而非普通用户体验
流式响应与 SSE 解析
当设置 stream=true 时,DeepSeek 会以 Server-Sent Events(SSE)形式发送增量片段,并以 data: [DONE] 结束流。
此时响应结构与非流式不同:
- 非流式:读取
choices[0].message - 流式:逐片读取
choices[0].delta
对于 deepseek-reasoner,流式片段中还可能先出现 delta.reasoning_content,再出现最终答案内容。
from openai import OpenAI client = OpenAI(api_key="", base_url="https://api.deepseek.com")
stream = client.chat.completions.create( model="deepseek-chat", messages=[ {"role": "system", "content": "You are a concise assistant."}, {"role": "user", "content": "Give me three deployment tips."} ], stream=True, )
for chunk in stream: delta = chunk.choices[0].delta if delta.content: print(delta.content, end="")
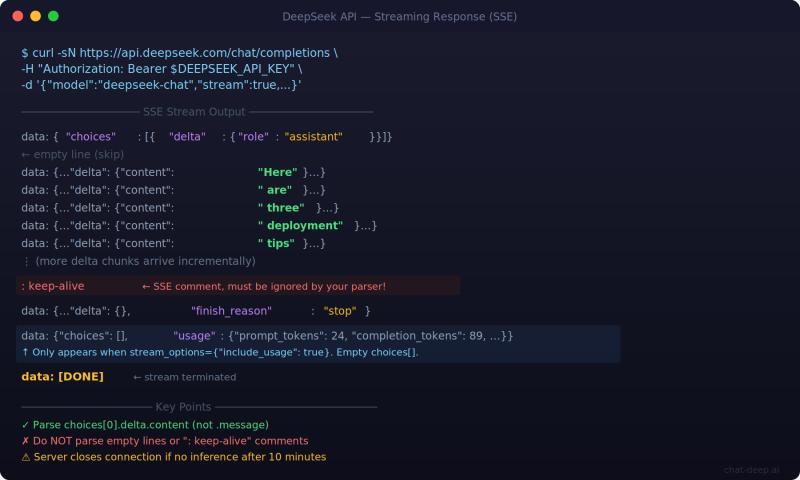
如果同时设置 stream_options={"include_usage": true},在 [DONE] 之前会多出一个仅包含 usage 的片段:
- 该片段的
choices数组为空 usage中包含完整的请求级用量信息- 其他流式片段的
usage通常为null
解析时还有一个细节:根据 Rate Limit 与 FAQ 文档,在请求排队等待调度时:
- 非流式响应可能包含空行
- 流式响应可能包含 SSE 保活注释,如
: keep-alive
OpenAI SDK 会自动忽略这些内容;如果你自己解析 HTTP 流,需要手动跳过这些空行和注释。官方还说明,如果 10 分钟内推理尚未开始,服务器会关闭连接。
JSON 输出模式
DeepSeek 的 JSON 输出模式并不是“礼貌地请求 JSON”那么简单,而是有两个硬性条件:
- 设置
response_format={"type": "json_object"} - 在提示词中明确要求模型输出 JSON
官方特别提醒:如果没有在提示中要求输出 JSON,模型可能会持续输出空白字符直到达到 token 上限,看起来像是请求“卡住”了。此外:
- 若
max_tokens设置过小,JSON 可能被截断 - 在 JSON 模式下,API 偶尔可能返回空内容
示例:
import json from openai import OpenAI
client = OpenAI(api_key="", base_url="https://api.deepseek.com")
response = client.chat.completions.create( model="deepseek-chat", messages=[ { "role": "system", "content": ( 'Return valid JSON only. ' 'Use this schema: {"question": string, "answer": string}.' ), }, { "role": "user", "content": 'Convert this into JSON: "What is the capital of Egypt? Cairo."', }, ], response_format={"type": "json_object"}, max_tokens=256, )
data = json.loads(response.choices[0].message.content) print(data)
更安全的心智模型是:
response_format只负责“容器”是 JSON- JSON 的具体结构仍需在提示词中清晰定义
如果你依赖结构化结果做自动化,建议同时关注成本:无效 JSON 或多次重试会悄悄消耗大量 token,可结合我们的价格页和成本计算器来评估。
工具调用与 tool_choice
在 DeepSeek 中,工具调用是“提案式”的:
- 你在请求中提供
tools列表 - 模型在回复中可能返回
tool_calls - 你的应用执行真实函数
- 再以
role="tool"的消息,把执行结果和对应的tool_call_id回传给模型
示例流程:
import json from openai import OpenAI
client = OpenAI(api_key="", base_url="https://api.deepseek.com")
tools = [ { "type": "function", "function": { "name": "get_weather", "description": "Get weather for a city.", "parameters": { "type": "object", "properties": { "location": {"type": "string", "description": "City name"} }, "required": ["location"] } } } ]
messages = [{"role": "user", "content": "What is the weather in Cairo?"}]
response = client.chat.completions.create( model="deepseek-chat", messages=messages, tools=tools, tool_choice="auto" )
message = response.choices[0].message messages.append(message)
tool = message.tool_calls[0] args = json.loads(tool.function.arguments)
在这里调用你自己的真实函数
tool_result = f"It is sunny in {args['location']}."
messages.append({ "role": "tool", "tool_call_id": tool.id, "content": tool_result })
follow_up = client.chat.completions.create( model="deepseek-chat", messages=messages, tools=tools )
print(follow_up.choices[0].message.content)
当前 schema 中 tool_choice 的含义:
none:绝不调用工具auto:模型自行决定是直接回复还是调用工具required:模型必须调用一个或多个工具- 也可以通过结构化对象强制调用某个指定函数
官方还说明:
- 目前仅支持
function类型工具 - 最多 128 个函数
- 函数名只能包含字母、数字、下划线、短横线,长度不超过 64 字符
生产环境中还需注意:
tool_calls[].function.arguments虽然声明为 JSON 文本,但模型仍可能生成不合法 JSON,或幻觉出 schema 之外的参数- 因此在调用真实函数前,一定要对解析后的参数做校验
严格模式 strict(Beta)
严格模式是工具调用的 Beta 版本,用来强制模型更严格地遵守你的 JSON Schema。要启用严格模式,需要:
- 将 base URL 切换为
https://api.deepseek.com/beta - 在
tools列表中,为所有函数设置strict: true - 服务器会校验 schema 是否符合 DeepSeek 支持的子集,不符合会直接报错
示例:
from openai import OpenAI
client = OpenAI(api_key="", base_url="https://api.deepseek.com/beta")
tools = [ { "type": "function", "function": { "name": "get_weather", "strict": True, "description": "Get weather for a city.", "parameters": { "type": "object", "properties": { "location": {"type": "string", "description": "City name"} }, "required": ["location"], "additionalProperties": False } } } ]
当前严格模式支持的类型包括:
objectstringnumberintegerbooleanarrayenumanyOf
同时有若干限制:
object内的每个属性都必须列在required中additionalProperties必须为false- 一些 JSON Schema 特性(如
minLength、maxLength等)暂不支持
因此严格模式非常适合稳定的函数签名约束,但并不是一个通用的 JSON Schema 校验器。
Chat Prefix Completion(Beta)
Chat Prefix Completion 是一种 Beta 变体:messages 中最后一条消息是 assistant,其内容是一个前缀,模型需要从该前缀继续生成。
使用要求:
- 最后一条消息必须
role="assistant" - 该消息需包含
prefix=true - 需要使用 Beta base URL:
https://api.deepseek.com/beta
示例:
from openai import OpenAI
client = OpenAI(api_key="", base_url="https://api.deepseek.com/beta")
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "user", "content": "Write a Python function that returns Fibonacci numbers."},
{"role": "assistant", "content": "python\n", "prefix": True}, ], stop=[""]
)
print(response.choices[0].message.content)
对于 deepseek-reasoner,在前缀补全场景下,schema 还允许在最后一条 assistant 消息中提供 reasoning_content,作为该轮推理链(CoT)的输入。这是一个相对小众但对精细控制推理续写很有价值的特性。
多轮对话与无状态上下文
DeepSeek 明确指出:/chat/completions 是无状态接口。服务器不会替你保存对话历史。
如果你希望第二轮对话“记住”第一轮内容,必须在第二次请求时,把之前的消息一并发送。这是开发者在第一次调用成功后最容易忽略的点。
示例:
from openai import OpenAI
client = OpenAI(api_key="", base_url="https://api.deepseek.com")
messages = [{"role": "user", "content": "What is the highest mountain in the world?"}] response = client.chat.completions.create(model="deepseek-chat", messages=messages)
messages.append(response.choices[0].message) messages.append({"role": "user", "content": "And what about the second highest?"})
response = client.chat.completions.create(model="deepseek-chat", messages=messages) print(response.choices[0].message.content)
在 deepseek-reasoner 中还有额外规则:
- 普通轮次之间,你需要保留之前的
content,但不要保留之前的reasoning_content - 但在同一轮推理内部、工具调用的子轮次中,Thinking Mode 指南又要求你在必要时回传
reasoning_content,以便模型继续推理
官方特别提醒:如果在“思维 + 工具调用”的路径中没有正确回传 reasoning_content,API 可能返回 400 错误。
响应对象结构
非流式响应类型为 chat.completion。开发者最常用的字段包括:
choiceschoices[0].messagefinish_reasonsystem_fingerprintusage
如果使用 deepseek-reasoner,返回的 assistant 消息中可能包含 reasoning_content;如果使用工具调用,则消息中可能包含 tool_calls。
当前文档列出的 finish_reason 取值:
stoplengthcontent_filtertool_callsinsufficient_system_resource
这些值对运维和调试很有帮助:
length:通常表示输出被max_tokens截断tool_calls:表示模型希望你执行工具insufficient_system_resource:表示推理系统中断了请求
用量、缓存与成本控制
官方响应 schema 中的 usage 字段包括:
completion_tokensprompt_tokensprompt_cache_hit_tokensprompt_cache_miss_tokenstotal_tokenscompletion_tokens_details.reasoning_tokens
文档还说明:
prompt_tokens = prompt_cache_hit_tokens + prompt_cache_miss_tokens
这使得 /chat/completions 的响应可以直接用于:
- 统计调用成本
- 评估上下文缓存(KV Cache)的命中效果
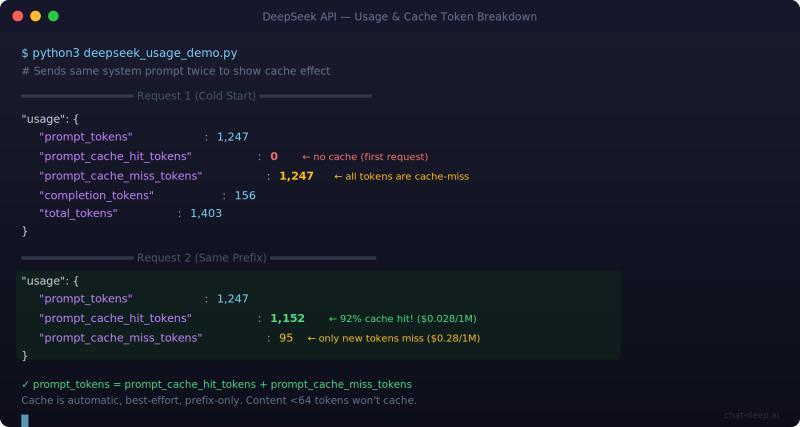
Context Caching 指南补充了关键细节:
- 上下文缓存默认开启
- 只有重复的前缀内容才可能命中缓存
- 缓存是“尽力而为”,不保证一定命中
- 少于 64 个 token 的内容不会被缓存
因此 usage 中的缓存字段是有意义的,但不要基于“100% 命中率”来设计业务逻辑。
截至 2026 年 4 月 1 日,公开价格页显示:deepseek-chat 与 deepseek-reasoner 的 token 单价相同:
- 缓存命中输入:每 100 万 token 收费 0.028 美元
- 缓存未命中输入:每 100 万 token 收费 0.28 美元
- 输出 token:每 100 万 token 收费 0.42 美元
因此 usage 不只是调试信息,而是直接对应账单的关键数据。
常见错误与排查思路
大部分 /chat/completions 相关问题,最终都可以归结为少数几类:
messages数组结构不合法- API Key 错误或缺失
- 参数组合不兼容(尤其在思维模式下)
- JSON 输出被截断或不合法
- 手写流式解析时处理不当(未忽略 keep-alive 等)
- 推理模式与多轮对话的状态管理错误
官方 Error Codes 页面给出了 HTTP 级错误分类,而 JSON 输出、Thinking Mode 与 Rate Limit 文档则解释了背后的请求结构与传输细节。我们也提供了站内的 DeepSeek 错误码对照与说明页面可供参考。
官方还指出:429 限流是动态的,目前无法按账号单独提升上限。
最佳实践清单
在你认为这个接口“已经接好”之前,建议确认客户端至少做到:
- 显式指定
model,不要依赖默认值 - 把
/chat/completions当作无状态接口,在应用侧维护完整对话历史 - 需要更好交互体验时使用
stream=true,若自行解析 HTTP 流,要正确忽略 keep-alive 行 - 仅在提示词中明确要求 JSON 时,才启用 JSON 输出模式
- 在执行真实代码前,始终校验工具调用参数
- 将
deepseek-chat作为通用集成的默认模型 - 在确有推理需求时使用
deepseek-reasoner,并正确处理其参数差异 - 持续监控
usage、prompt_cache_hit_tokens与reasoning_tokens,避免成本“隐形”增长
结语
如果只记住一件事,那就是:DeepSeek 的 /chat/completions 在“最小用法”上非常简单,但在“边缘能力”上极其丰富。
- 最小用法:
model + messages - 深度用法:流式 SSE、JSON 输出、工具调用、Beta 严格模式、前缀补全、用量统计、缓存计费,以及思维模式下的精细状态管理
这也是为什么 /chat/completions 不只是一个“快速上手”接口,而是绝大多数 DeepSeek 应用最终围绕的核心能力面。
如果你希望在此基础上获得更顺畅的落地路径,推荐继续阅读:
- DeepSeek API 总览
- DeepSeek 聊天机器人实现指南
- DeepSeek 在 Web 应用与 SaaS 中的集成指南
在遇到与本文不一致的地方时,请始终以官方 DeepSeek 文档为最终事实依据。
想在写代码前先体验 DeepSeek 的效果,可以直接在 chat-deep.ai 上试用 DeepSeek Chat,无需 API Key。

