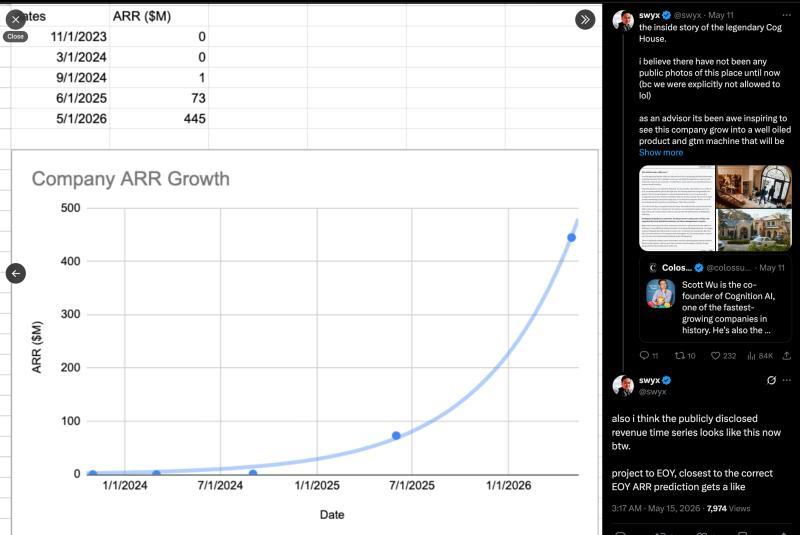
我们上次报道Cognition是在2025年9月的100亿美元C轮融资,当时Smol.ai也加入了Cognition,AINews最终迁移至Latent Space。8个月后,Cognition估值增长了2.5倍,成为目前AI领域最大的独立智能体实验室,这一趋势我们去年就已预测。官方披露的年经常性收入(ARR)预计到年底将超过10亿美元,增长轨迹与2025年发生的行业变化图表惊人相似:
在企业SaaS领域,ARR是利用率的滞后指标,客户名单中包括企业和初创生态中最严苛的用户,如Exa和Modal等。
我们将在明天发布更多关于Cognition的播客内容。
AI Twitter综述
推理效率、服务架构与成本曲线
-
推理优化正逐步转向架构层面,不仅仅是内核级别。例如,EAGLE 3.1通过稳定隐藏状态反馈和减少深层解码时的注意力漂移,提升了推测解码的鲁棒性,重点支持长上下文和实际服务可靠性。Perplexity开源了重建的Unigram分词器,CPU利用率降低5-6倍,处理514个标记仅需63微秒且无堆内存分配。阿里巴巴的Qwen3.5在TokenSpeed上实现580标记/秒,联合优化团队包括LightSeek、NVIDIA等。
-
价格下降背后是结构性KV缓存和注意力机制的改进。多条推文指出,中国实验室近期的API降价是基于每个标记的服务成本降低,而非临时补贴。DeepSeek V4-Pro采用混合注意力机制,将百万级标记KV缓存压缩至V3.2的约10%,单标记推理FLOPs降至27%。小米的MiMo通过SWA和分层缓存管理减少缓存流量,缓存容量提升5倍,缓存成本降低约80%。
智能体、执行环境、记忆与持续学习
-
技术栈重点从“模型质量”转向“模型-执行环境-记忆的匹配”。LangChain发布Deep Agents v0.6,Delta Channels功能将200轮编码会话的检查点存储从5.3GB降至129MB,同时推出了Fleet中的计算机使用功能和Context Hub,实现版本化的智能体上下文和技能管理。LangSmith Engine自动化评估、诊断和修复流程,帮助开发者将追踪反馈转化为可复用的在线/离线评估器。任务-执行环境匹配的重要性与模型质量同等,定制化垂直系统通过缩小工具、提示和上下文范围,表现优于通用执行环境。
-
持续学习逐渐成为产品类别。Trajectory推出了基于产品使用信号和智能体轨迹的持续后训练平台,获得1500万美元融资,合作伙伴包括Clay、Harvey等。Baseten支持FP8/NVFP4量化和自动扩展的H100基础设施,已实现3970亿参数模型的夜间部署。开源工具方面,基于LangChain/LangGraph的记忆中心智能体获得好评,RLM的最小训练执行环境显示小团队可在一天内用8×A100完成长上下文智能体的强化学习调优。
基准测试、扩展规律与训练方法
-
新基准测试聚焦长时段、复杂的真实工作流。DeepSWE涵盖5种语言、91个代码库的113个任务,使用简约的bash执行环境和较短提示,但代码量是SWE-Bench Pro的5.5倍,平均涉及7个文件。IBM和Artificial Analysis发布了针对Kubernetes事件响应的ITBench-AA,所有前沿模型得分均低于50%,Claude Opus 4.7以47%领先,GPT-5.5为46%,GLM-5.1 Reasoning开源权重得40%。AgingBench从寿命角度分析部署智能体的性能退化。
-
训练效率研究在理论和系统层面持续活跃。Sakana AI发布DiffusionBlocks,将前向传播重新解释为扩散去噪步骤,实现逐块训练,显著降低内存需求,性能覆盖ViTs、DiTs、掩码扩散、自回归和递归深度Transformer。Snowflake推出ZoRRo,声称长上下文强化学习速度提升3.5倍,支持3.2倍更长上下文窗口。理论方面,Tiberiu Musat提出最小神经权重范数与最小程序长度的关系,Unified Neural Scaling Law提出多变量函数形式,更准确预测神经网络扩展行为。
模型与多模态发布:生物学、视觉、OCR及嵌入式AI
-
蛋白质建模领域亮点频出。ESMFold2作为开放科学引擎发布,支持蛋白质结构预测和设计,在蛋白质相互作用和抗体方面表现优异,附带68亿蛋白质和11亿预测结构的图谱。该发布强调了实用设计成果和蛋白质表征的机制可解释性,规模超过AlphaFold数据库。
-
一系列实用的多模态和开源模型发布。Google DeepMind发布Gemini Embedding 2白皮书,支持文本、图像、音频和视频的统一多模态嵌入。NVIDIA的LocateAnything结合Qwen2.5-3B和Moon-ViT,实现密集目标检测速度提升10倍。Hugging Face集成Roboflow的RF-DETR,实时检测和分割性能优于YOLO。Surya OCR 2发布,模型参数6.5亿,在OLMOCR基准测试中准确率83.3%,91语言内部基准87%,RTX 5090上每秒处理5页。LiteParse v2用Rust重写解析,速度提升最高达100倍,支持边缘和浏览器部署。谷歌发布新Coral开发板,支持本地语音、视觉和控制演示。
开发者平台、企业控制与编码智能体产品化
-
编码智能体正整合为完整产品栈,具备企业级控制。OpenAI逐步淘汰Codex中的GPT-5.2和GPT-5.3-Codex,转向GPT-5.5,企业功能新增私有MCP连接(仅出站HTTPS)、工作负载身份联合和扩展的管理API,支持支出警报、白名单、保留策略和托管工具管理。OpenAI发布了基于Codex的自我改进税务智能体案例研究,重点在于将审阅者修正追踪回评估和修复。
-
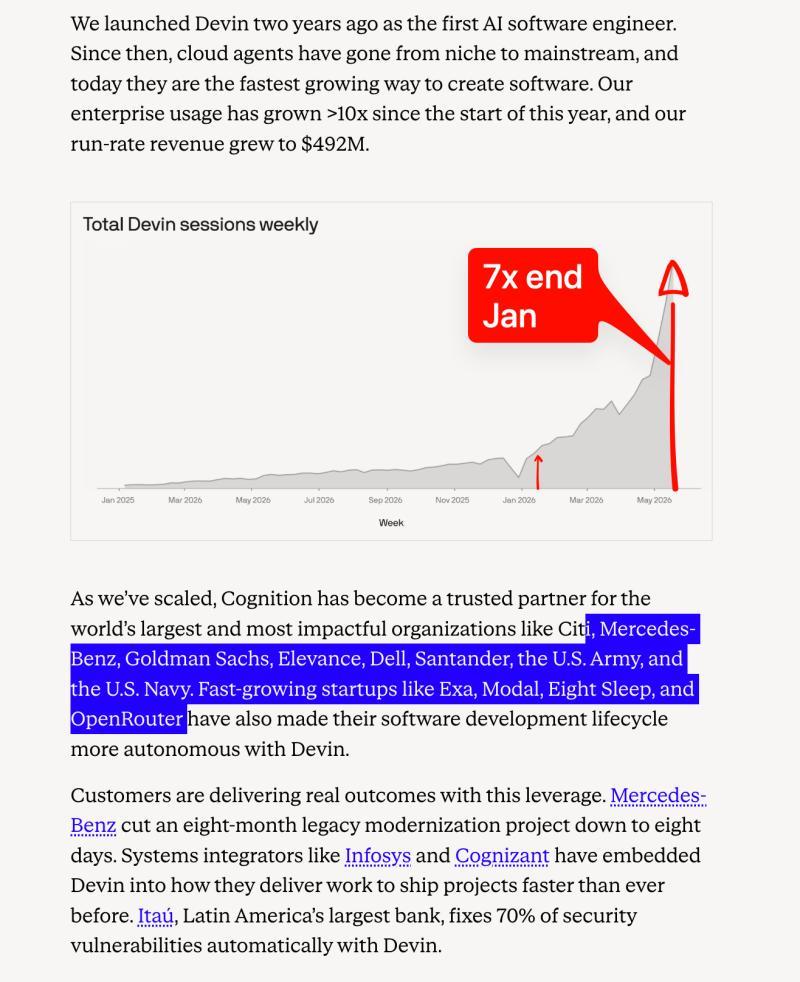
编码智能体竞争聚焦可靠性、工作流广度和企业采用。Anthropic的Claude Code发布可靠性和性能更新,简化错误报告。GitHub持续推动“智能体化IDE”方向,举办Copilot开发者日,强化MCP定位。Cognition成为最大商业亮点,完成超过10亿美元融资,估值260亿美元,企业使用量同比增长超过10倍,年收入达4.92亿美元,客户名单不断扩大,获得Exa等用户的强力支持。生态系统多元化迹象明显:Cua Driver for Windows支持后台计算机使用,Cloudflare的智能体平台因“分数计算”经济性获赞,Grok Build的工作树支持面向仓库规模的多智能体代码协作。
AI Reddit综述
/r/LocalLlama 和 /r/localLLM 回顾
- 低位宽本地AI在消费硬件上的应用
-
PrismML发布了Binary和Ternary Bonsai Image 4B,这是1位和三值文本到图像扩散Transformer变体,模型大小约3GB,采用Apache-2.0许可,支持WebGPU浏览器本地运行。该项目被认为是对FLUX.2 Klein 4B的量化和后训练版本,但存在归属争议,原模型仅在白皮书中提及,社区讨论其是否合理标注来源。
-
一位用户开发了基于Rust的自定义推理引擎Cluaiz,在RTX 3050 4GB显卡上运行1.58位量化的Bonsai-4B模型,达到66.8标记/秒,解决了OOM问题。社区对“直接硅片访问”等说法持怀疑态度,认为可能只是提前编译,并质疑缺乏可复现的基准和详细实现细节。
- Qwen 3.5/3.6本地模型发布及编码测试
-
llmfan46发布了Qwen3.5-35B-A3B-uncensored-heretic-v2,去除了部分限制,保留了全部785个MTP张量,拒绝率从92%降至14%,性能仅略微下降。模型支持多种格式,包括Safetensors、GGUF、NVFP4和GPTQ-Int4。社区认为Qwen3.6更偏向编码任务,类似“3.5 coder+”。
-
一位用户分享了使用27B Qwen模型通过Opencode一次性生成完整HTML5游戏的经历,游戏功能完善,仅需少量后续调整。该模型在64K上下文内表现最佳,超过128K后性能明显下降,建议长上下文任务定期总结和重启会话以维持质量。