引言
GPT 5.3 Codex 和 Claude Opus 4.6 两款最新发布的 AI 模型,展示了人工智能在处理更长、更实用工作流程方面的迅速进步。它们不仅仅专注于回答问题或生成简短代码片段,而是能够应对涉及规划、迭代和跨越更大上下文的真实任务。
本文将通过两个常见场景——用户界面构建和数据处理,比较 GPT 5.3 Codex 与 Claude Opus 4.6 的实际表现。
GPT 5.3 Codex 概览
GPT 5.3 Codex 是 OpenAI 最新的 Codex 模型,专注于执行导向的开发者工作流程。它不仅生成代码,还能处理涉及规划、工具使用和迭代的复杂任务。
该模型的一个关键特点是其代理式设计,能够直接操作终端、文件和构建工具,并在长时间会话中保持上下文,方便开发者引导和调整流程,适合多步骤和后续修改的工作场景。
性能方面,GPT 5.3 Codex 在 SWE Bench Pro 中得分56.8%,Terminal Bench 2.0得分77.3%,OSWorld Verified得分64.7%,体现了其在真实计算机任务执行中的能力。它的运行速度比之前版本快约25%,且在长会话中更为高效,响应更快。
实际应用中,GPT 5.3 Codex 适合全栈开发、大规模调试重构、基础设施工作等需要稳定进展和执行可靠性的场景。
Claude Opus 4.6 概览
Claude Opus 4.6 是 Anthropic 最新旗舰模型,定位于推理密集型工作、结构化输出和长上下文任务。虽然支持编码和代理式工作流程,但核心聚焦于清晰、一致和复杂信息的深度推理。
Opus 4.6 的显著更新之一是其长上下文能力,默认支持20万token,上线测试版支持100万token,长上下文检索能力显著提升。在 MRCR v2 基准测试中准确率达76%,显示出在长会话中上下文衰减较低。
此外,Opus 4.6 引入了自适应思考和可配置的努力级别,允许开发者在推理深度、速度和成本之间平衡。支持128K输出token,适合生成大型报告、分析和结构化文档。
在多项推理和知识工作基准中,Opus 4.6 领先,包括 Terminal-Bench 2.0、Humanity’s Last Exam 和 GDPval-AA,领先 GPT-5.2 约144 Elo分,特别适合分析师工作流、文档密集型研究和数据分析。
任务对比一:编码与用户界面开发
Claude Opus 4.6 UI 构建表现
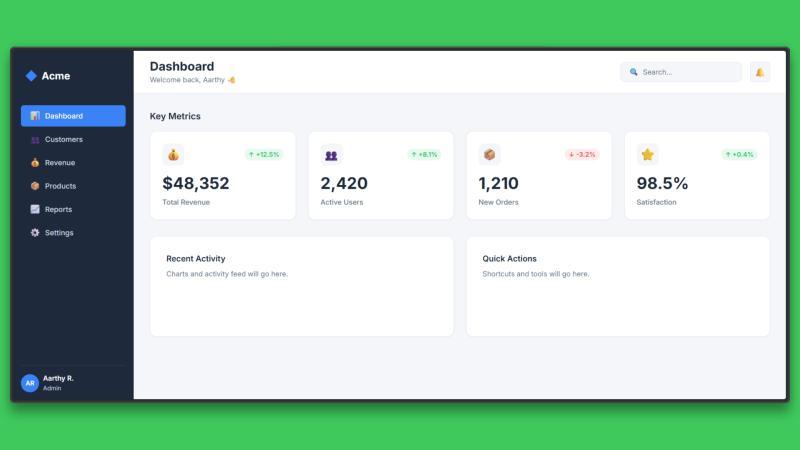
使用相同的提示,Claude Opus 4.6 生成了基于 React 的仪表盘 UI,代码结构清晰,布局合理,组件层次分明。整个过程约3分钟,模型在生成代码前花费更多时间进行组件层级和视觉平衡的推理。
生成的界面首次运行即渲染良好,设计选择显得谨慎且一致,整体优先考虑结构和一致性,奠定了坚实的 React UI 基础。
GPT 5.3 Codex UI 构建表现
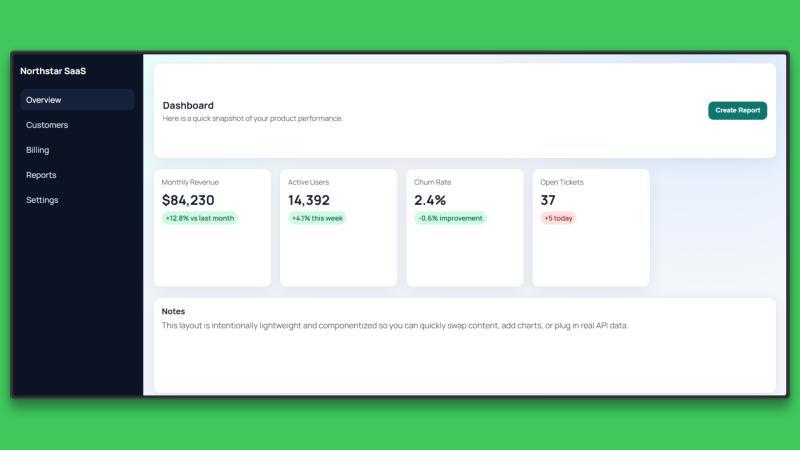
同样的提示下,GPT 5.3 Codex 生成了完整的仪表盘 UI,包括布局、样式和基础组件结构。用时约3分53秒,生成的 HTML 和 CSS 代码可直接运行,具有合理的间距、排版和响应式设计。
输出无需手动修正即可正常渲染,整体更注重快速构建功能性 UI,便于后续迭代。
任务对比二:数据处理
Claude Opus 4.6 数据分析表现
在真实应用日志数据分析任务中,Claude Opus 4.6 采用结构化且系统化的方法,先检查 Excel 文件,再构建完整的分析流程。约8分钟内,模型编写并迭代 Python 脚本,加载数据、计算指标,解决依赖缺失和列不匹配等问题。
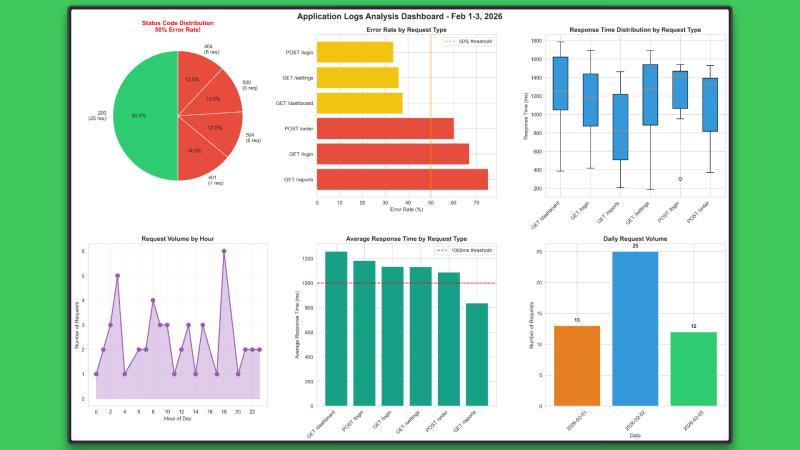
它不仅完成基础分析,还生成了书面报告、汇总表和可视化图表,体现了对端到端流程的强烈掌控力,结果清晰且完整。
GPT 5.3 Codex 数据分析表现
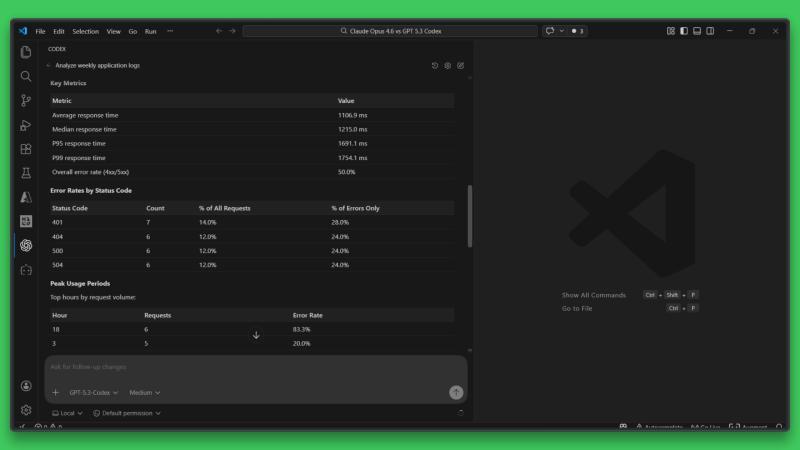
同样数据和提示下,GPT 5.3 Codex 用时约1分35秒,快速提取关键指标和总结见解。它没有构建完整脚本流程,而是直接生成清晰、结构化的摘要,包含错误分布和高峰使用期等信息。
结果即用即得,表格整洁,见解简明,适合快速分析和迭代。
GPT 5.3 Codex 与 Claude Opus 4.6 对比总结
| 方面 | GPT 5.3 Codex | Claude Opus 4.6 |
|---|---|---|
| 模型定位 | 执行优先,代理式编码,注重端到端任务完成 | 推理优先,优化清晰度、结构和长上下文理解 |
| 编码与 UI 开发 | 快速构建功能性 UI,注重速度和实用默认值 | 生成结构清晰、规划充分的 React 代码 |
| UI 任务表现 | 约3分53秒完成,代码可直接运行 | 约3分钟完成,布局和组件层次更细致 |
| 数据分析与报告 | 快速提取关键指标,简洁明了 | 构建完整分析流程,生成报告和可视化 |
| 数据任务表现 | 约1分35秒完成,直接给出总结 | 约8分钟,迭代修正,结果更全面 |
| 工具使用与执行风格 | 偏向快速直接回答,较少中间工具 | 重度使用工具、脚本和多步骤流程 |
| 迭代与指导需求 | 低指导需求,快速产出,结构需复核 | 前期需更多指导,正确性和结构较稳定 |
| 优势 | 速度快,执行力强,适合长时间代理式工作 | 推理深度强,输出结构化,长上下文处理优 |
| 局限 | 结构规划较弱,可能牺牲部分精细度 | 简单任务较慢,成本和延迟较高 |
| 适合用户 | 全栈工程师、平台团队、DevOps、快速原型 | 分析师、数据团队、研究人员、大文档处理 |
关键结论
选择哪款模型取决于你的工作流程需求。若你专注于功能开发、代码迭代和跨工具端到端工作,GPT 5.3 Codex 是理想选择。若工作涉及深度分析、大型文档或对数据的严谨推理,Claude Opus 4.6 更为合适。两者代表了执行速度与分析深度之间的不同权衡。
如果你需要构建可靠的数据摄取、文档解析和可扩展代理工作流,推荐使用 Tensorlake 这一统一解决方案。无论是处理 PDF、电子表格还是幻灯片,Tensorlake 都能帮助你搭建可扩展、生产级的管道,完美连接 AI 模型和自动化工作流。


