产品详细介绍
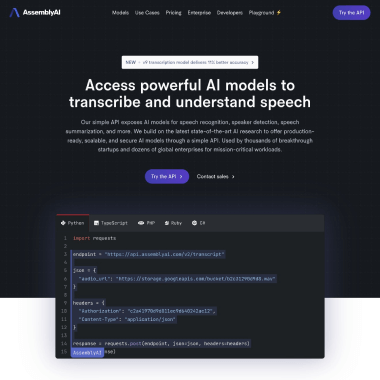
AssemblyAI 是一款面向开发者与企业的云端 Speech AI 平台,核心能力是将语音高精度转写为文本,并在此基础上进行深度语音理解与内容分析。无论是呼叫中心录音、会议记录、访谈播客,还是实时语音对话,AssemblyAI 都能帮助你快速解锁语音数据的价值。
平台提供的语音转写模型在多种真实场景中表现出色,能够识别包含姓名、日期、地址、药品名称、技术术语、代码、命令、公式以及特殊格式等复杂内容,并尽可能保留语气停顿、重复、修正等自然口语特征,适用于医疗、金融、客服、媒体、教育等对准确性要求极高的行业。
在语音理解方面,AssemblyAI 提供丰富的音频智能能力,可对转写文本进行结构化处理和深度分析,例如:
- 自动提取关键信息与实体(如人物、地点、药品、品牌等)
- 识别说话人角色(如护士/患者、客服/客户等)并进行说话人分离
- 对长语音内容进行摘要与要点提炼
- 支持多语言场景下的语音识别与理解
对于需要实时交互的语音代理、智能客服或语音助手,AssemblyAI 提供低延迟、高准确率的实时语音识别能力,并具备精确的轮次结束(end-of-turn)控制,帮助开发者构建自然流畅的对话体验。平台架构支持从初创公司到大型企业的高并发访问,能够轻松扩展到数百万用户级别。
通过标准化 API 接口,开发者可以将 AssemblyAI 的语音转写与语音理解模型快速集成到现有产品或工作流中,用于:
- 批量处理历史录音,进行内容检索与合规审查
- 自动生成会议纪要、访谈记录、字幕与文稿
- 为语音机器人、IVR 系统和智能硬件提供语音输入能力
- 对客服通话进行质量监控与情绪分析
简单使用教程
下面以典型的云端 API 使用流程为例,说明如何快速上手 AssemblyAI:
-
注册账号并获取 API Key
- 访问 AssemblyAI 官网并注册账号。
- 在个人控制台中创建并复制你的 API Key,用于后续接口调用的身份验证。
-
准备音频数据
- 支持常见音频格式(如 WAV、MP3、M4A 等),可为录音文件或实时音频流。
- 确保音频清晰、背景噪声尽量可控,以获得更高转写准确率。
- 将音频文件上传到可访问的存储(如对象存储或 AssemblyAI 支持的上传方式)。
-
调用语音转写 API
- 在后端服务中使用 HTTP 请求或官方 SDK,携带 API Key 调用 AssemblyAI 的转写接口。
- 在请求体中指定:
- 音频文件的 URL 或上传标识
- 所需功能选项(如是否启用说话人分离、实体识别、摘要等)
- 发送请求后,你会获得一个转写任务 ID。
-
轮询或回调获取结果
- 使用任务 ID 调用查询接口,轮询任务状态,直到状态为完成。
- 或在控制台/接口中配置回调 URL,让 AssemblyAI 在转写完成后主动推送结果。
- 结果中包含完整转写文本、时间戳、说话人标记以及启用的各类语音理解分析数据。
-
集成到业务流程
- 将转写文本用于生成会议纪要、字幕、搜索索引等。
- 利用实体识别、摘要、说话人信息等结构化数据,驱动客服质检、业务洞察、自动工单创建等流程。
- 对实时场景,可使用实时流式 API,将语音输入即时转为文本并驱动对话机器人或语音指令系统。
-
优化与扩展
- 根据业务场景调整模型配置(如语言、领域、是否启用高级音频智能功能)。
- 监控调用量与性能,利用平台的扩展能力支持更多用户与更大规模的语音数据处理。