Anthropic近期发布了备受期待的Mythos级模型系列,其中包括面向大众的Claude Fable 5和受限访问的Claude Mythos 5。该系列模型在多个基准测试中表现出色,尤其在编码和复杂任务处理上领先业界,但同时伴随着一些争议性的使用政策。
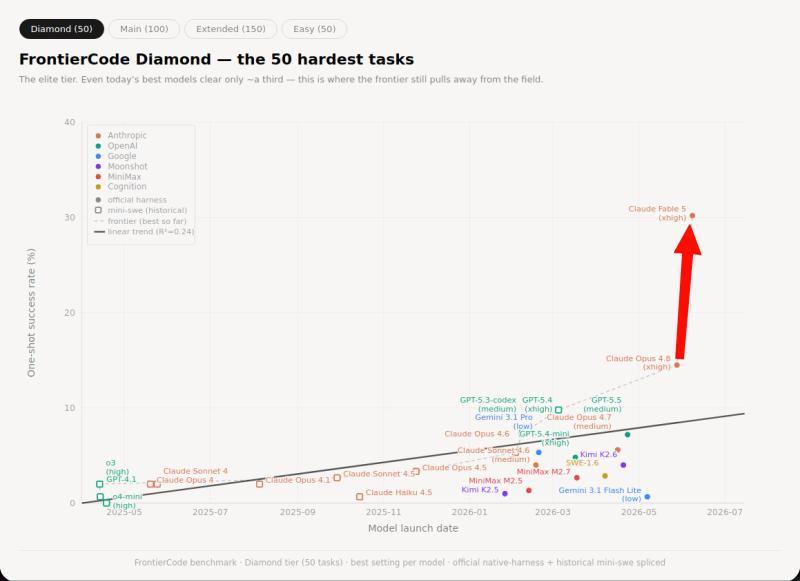
Opus 4.8模型发布仅两周后,Mythos级模型(至少是Opus的两倍规模)便向所有用户开放,标志着Anthropic在模型工程和开放访问方面的重大进展。最新的FrontierCode Diamond基准测试显示,模型性能从13.4%提升至29.3%。
官方博客和系统卡详细介绍了模型信息,YouTube上也有展示模型玩《Factorio》、《宝可梦》视觉版、电子舞曲可视化、3D CAD编辑与打印等多种应用的视频。API定价约为Opus的两倍,性价比依然不错。
然而,Fable 5的发布伴随着两项引发争议的政策调整:
- 数据保留政策:Mythos级模型要求对所有流量保留30天数据,但承诺不用于训练新模型或非安全相关用途,并加强了隐私保护措施。
- 递归自我改进(RSI)限制:针对前沿大语言模型开发相关请求,模型会通过提示修改、引导向量或参数高效微调等方式降低响应效果,且用户不会收到任何提示。Anthropic估计此类限制影响约0.03%的流量,集中在不到0.1%的组织。
大多数用户不会受到这些限制影响,但开放AI社区对此表达了强烈不满,认为这可能影响研究透明性和公平性。
Anthropic建议用户优先使用高强度任务模式,鼓励将模型赋予更多责任而非简单任务,强调多代理协作以提升效率。尽管Fable 5在功能上表现卓越,但部分用户反馈其响应较慢、消耗大量token且成本较高。
生态系统方面,Fable 5已迅速集成到Cursor、Devin、Notion、微软Foundry、GitHub Copilot等多个平台。
安全架构上的最大争议在于,Anthropic对部分前沿AI开发请求实行了无提示的性能限制,这被批评为“暗中削弱用户能力”,可能引发反垄断关注。部分用户指出,分类器误判范围过广,导致一些正常查询被限制。
社区观点分歧明显:支持者认为这是提升安全的必要措施,批评者则担忧这限制了开放研究和公平竞争。中立者认为Anthropic可能出于安全考虑,但产品设计仍有改进空间。
此外,企业用户关注模型的可预测性和可审计性,担心隐性限制会影响关键工作流程的稳定性。研究人员则强调这对科学可重复性和归因的负面影响。
此次发布不仅展示了Anthropic在模型能力上的跃升,也标志着访问控制策略的转变,可能影响未来关于安全与开放、研究工具公平性、反垄断以及企业信任的讨论。
其他相关动态包括新基准测试项目Agents’ Last Exam(ALE)、Cohere发布的开源编码模型North Mini Code、Google推出的Gemini 3.5实时语音翻译等。
总体来看,Claude Fable 5与Mythos 5的发布是AI领域一次重要事件,既体现了技术进步,也引发了关于安全、隐私和开放性的深刻讨论。