当 ChatGPT 在 2022 年 11 月上线、两个月就吸引了一亿用户时,我一度把它当成“被过度吹捧的聊天机器人”。事实证明,这个判断很快就过时了。如今,我和身边几乎所有同事每天都在用 AI 编码工具,2023 年那种“AI 能不能写一封像样的邮件”的争论,已经显得非常遥远。那么,AI 的下一步究竟会走向哪里?
行业已经从“AI 到底行不行”转向“AI 将如何深度介入现实系统”。Anthropic 的经常性收入已突破 70 亿美元,科技巨头在数据中心上的投入规模,是五年前难以想象的。真正的问题不再是 AI 是否有效,而是:当 AI 不再被动等待提示,而是开始自己决定下一步要做什么时,会发生什么?
本文将围绕几个核心方向展开:自主智能体(Agentic AI)、AGI 时间表之争、小型语言模型与边缘 AI、量子计算与数字孪生,以及它们对就业、编程、医疗和监管格局的影响。
一、从生成式 AI 到自主智能体
过去两年,主流 AI 工具的交互模式非常简单:人类提问,模型回答——人开车,AI 当副驾驶。现在,这种模式正在被“能自己规划和执行任务的智能体”取代。
1. 自主智能体的崛起
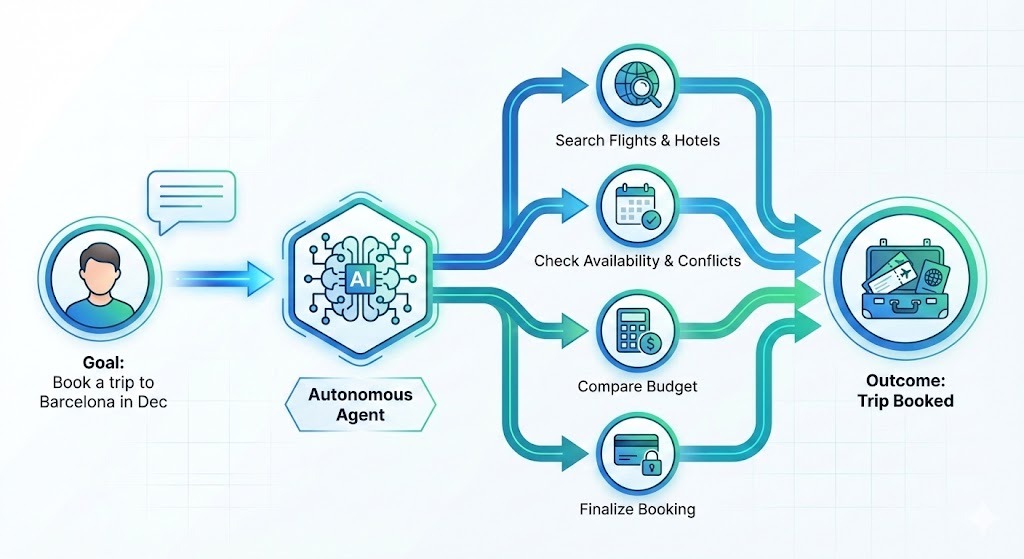
所谓 Agentic AI(自主智能体),不再只是回答问题,而是围绕目标自动拆解步骤、调用工具并执行。
例如,你不再只是问“巴塞罗那有哪些酒店”,而是直接说:“帮我预订 12 月去巴塞罗那的行程。”一个成熟的智能体会自动:
- 搜索航班与酒店选项
- 按你的偏好筛选(位置、评分、早餐、退改政策等)
- 将价格与预算交叉比对
- 检查你的日历是否冲突
- 最终完成预订并发确认信息
你只描述“想要的结果”,系统负责“如何到达那里”。
企业对这类系统的兴趣极高。Deloitte 预测,到 2026 年底,75% 的公司会在自主智能体上投入资金。但现实落地远不如愿:UiPath 在 2025 年中期的调研显示,真正成功上线到生产环境的智能体部署,仅约 30%。
2. MCP:打通智能体与企业系统的“USB-C”
最大瓶颈在于 集成。写一个能自动写代码的智能体不难,让它稳定、安全地对接 CRM、工单系统、内部 API,并且不“乱动生产环境”,才是真正的难点。46% 的企业将“与现有系统打通”视为主要阻碍。
为解决这一问题,行业开始围绕开放标准集结,例如 Anthropic 提出的 Model Context Protocol(MCP),以及 OpenAI 的 AGENTS.md 规范,它们都被贡献给了 Agentic AI Foundation,目标是构建中立、开放的智能体基础设施。
MCP 常被形容为“AI 领域的 USB-C”:统一的接口标准,让智能体可以方便地与各种工具和平台通信。目前已支持或正在对接的生态包括 Claude、Cursor、Microsoft Copilot、VS Code、Gemini、ChatGPT 等。
对于想从 Demo 走向生产的人来说,关键不再是“会不会写提示词”,而是:能否基于这类标准,把智能体安全地嵌入真实业务流程。
3. AGI 是否临近?
通用人工智能(AGI)——能在多个领域达到人类专家水平的系统——何时到来,取决于你问谁。
- 乐观派(多为大模型公司 CEO):
- Anthropic 联合创始人 Dario Amodei 曾提到,2026–2027 年 可能出现“相当于一个国家的天才集中在数据中心”的系统。
- Sam Altman、Demis Hassabis 也多次给出 3–5 年 的时间窗口。
- 谨慎派:
- Gary Marcus 认为近几个月的进展对 AGI 乐观论“极为不利”。
- 前 OpenAI 研究员 Andrej Karpathy 则倾向于 至少十年后。
- 2023 年一项对研究者的大规模调查给出的 中位数预测是 2047 年。
需要注意的是,乐观时间表对融资与估值非常有利,因此难免带有策略性。相比“哪一年到 AGI”,斯坦福 HAI 的观点更有参考价值:从“布道”走向“评估”——真正重要的问题是:
当前系统在具体任务上的表现如何?在哪些环节仍然必须有人类把关?
二、LLM 之外的新技术:小模型、量子与数字孪生
AI 的前沿并不只在“把模型做得更大”。小型语言模型(SLM)、边缘 AI、量子计算和数字孪生,正在从不同方向重塑技术版图。
1. 小型语言模型(SLM)与边缘 AI
在“更大模型”的叙事之外,小而专的模型 正在快速升温。Gartner 预测,到 2027 年,企业部署的 小型、任务专用模型数量,将是通用大模型的三倍。
原因非常现实:
- 成本:
- 运行超大模型极其昂贵,有报道指出 OpenAI 在 2025 年初的推理成本几乎是收入的两倍。
- SLM 可以大幅降低每次调用成本,做到“每次请求只是几分之一美分”。
- 隐私:
- 在医疗、金融等领域,数据不能离开本地。部署在本地设备或私有服务器上的小模型,天然更符合合规要求。
- 相关市场预计将从 2025 年的 9.3 亿美元,增长到 2032 年的 54.5 亿美元。
- 速度:
- 本地推理几乎没有网络延迟,对制造质检、银行实时风控等“毫秒级”场景至关重要。
NVIDIA 研究者提出,下一个飞跃不是“更大”,而是“更专”:邮件解析、SQL 生成这类任务并不需要百科全书式知识,更适合由一组专门模型协同完成——即所谓 模型舰队(model fleets) 架构,而不是一个“万能大脑”。
Google、Mistral、Microsoft、阿里巴巴等都在这一方向上发力。Google AI Edge 已支持十余种本地模型,包括其首个多模态端侧模型 Gemma 3n。
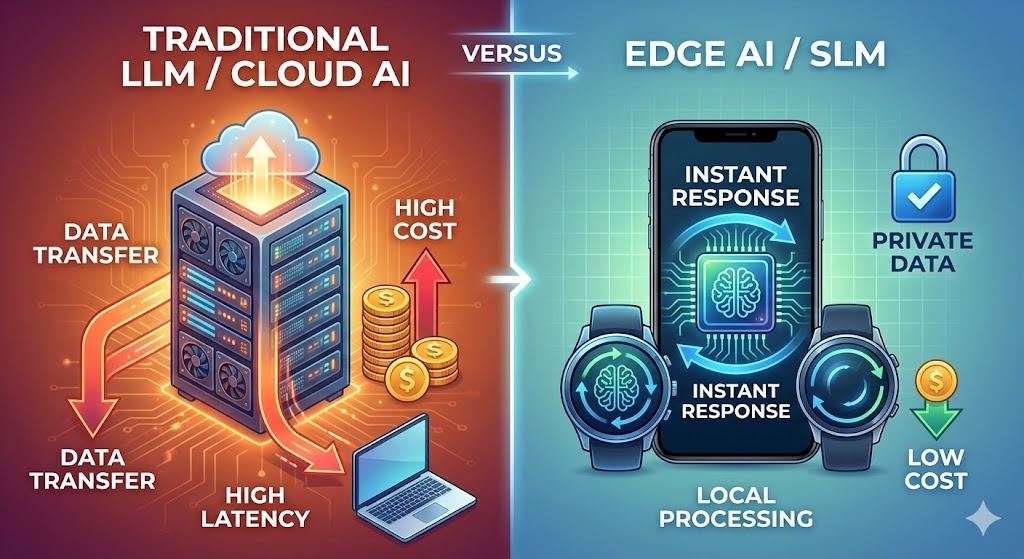
SLM 与 LLM 的对比
下表概括了两种路径的主要差异:
| 维度 | 大型语言模型(LLM) | 小型语言模型(SLM) |
|---|---|---|
| 运行位置 | 云端服务器 | 终端设备、边缘节点、本地服务器 |
| 单次成本 | 较高(约 $0.01–0.10) | 极低(往往是几分之一美分) |
| 响应时间 | 依赖网络(约 100–500ms) | 本地推理(可低于 50ms) |
| 数据流向 | 数据需上传到云端 | 数据留在本地 |
| 定制难度 | 训练与微调成本高 | 更易针对特定任务做轻量定制 |
| 最适合场景 | 复杂推理、创作、广泛知识 | 明确任务、对速度与可靠性要求极高 |
| 能源消耗 | 计算与能耗都很可观 | 相对节能 |
大模型不会因此“过时”,复杂问题仍然需要它们的能力。更现实的未来是:大模型 + 小模型并存,根据任务类型动态选择。
2. 量子计算与 AI 的交汇
“量子计算还有五年”这句话已经说了二十年,但 2025 年底之后,情况出现了实质性变化。
- Google 使用 65 个量子比特,在某些物理模拟任务上实现了对 Frontier 超级计算机 约 13000 倍的加速。
- IBM 目标在 2026 年前后实现“量子优势”。
- 研究者开始用神经网络实时预测并纠正量子比特误差。
行业里越来越多的人不再谈“遥远的理论突破”,而是把它当成一个 工程问题 来推进。
当前流行的概念是 “量子实用性(quantum utility)”:不是在所有问题上全面超越经典计算,而是在某些特定、极度复杂的优化问题上,做到更快或更省。
典型应用包括:
- 电池材料与化学反应优化
- 药物分子筛选与蛋白质建模
- 大规模投资组合风险建模
JPMorgan Chase 的研究团队近期在量子流式算法上取得突破,能以指数级空间优势处理大规模数据集,这是经过同行评审的实证成果,而非单纯的市场宣传。
预测仍然存在巨大分歧:
- 量化预测平台 Manifold Markets 上,多数参与者并不认为 2026 年前 量子计算能在密码学或复杂生物模拟上全面超越经典系统。
- 但同一群体对“十年内出现有用的容错量子计算机”则相当有信心。
实际意味着什么?
现实中不会存在“孤立的量子计算机”。行业共识是 异构计算(heterogeneous compute):量子处理器与 GPU 集群共同部署在高性能数据中心,由 AI 系统负责调度,哪些子问题交给量子,哪些留给经典计算。
对从事前沿 R&D 的数据科学家而言,这意味着:
- 不必自建量子实验室,也可以通过 IBM、Google、Amazon Braket、Azure Quantum 等 量子云 API 调用量子子程序;
- 但需要理解哪些问题适合量子、如何设计混合算法,这是一条新的技能曲线。
传统数据科学强调“大数据”,量子计算更关注“复杂优化”:变量维度极高、组合爆炸的场景,如分子模拟、全球物流、金融风险等。对这些行业来说,量子 + AI 正在从“概念”变成“工具”。
3. 数字孪生与仿真
数字孪生(Digital Twin) 正在从流行语变成基础设施。其核心思想是:
为现实中的物理系统(工厂产线、仓储网络、电网、城市片区等)构建一个“实时同步的虚拟副本”,并用它来在“虚拟世界”中先试错,再动真格。

制造业是最典型的早期落地场景。现代工厂已经在持续产生数字孪生所需的数据:
- PLC 信号与设备遥测
- 维修与保养记录
- 工单与排产信息
- 质量检测结果
- 库存与物流数据
AI 将这些数据转化为可查询、可推演的模型,不只是看报表,而是做 “如果……会怎样” 的反事实分析:
- 如果周二早上冲压机停机 6 小时,会影响哪些订单?
- 如果把某个零件从供应商 B 换成 C,且 C 的缺陷率略高,整体良率与成本会怎样变化?
- 如果把经验最丰富的操作工集中到最后两道工序,整体节拍与返工率会如何变化?
价值不在于“预测会出问题”,而在于:提前算清问题的连锁反应,并预先准备好应对方案,而不是在凌晨三点被迫临时救火。
AI 的作用在于大幅降低构建和维护孪生模型的成本:
- 现代机器学习模型可以直接从实时数据中学习系统行为;
- 自动监测“模型漂移”,在现实系统发生变化时自动调整孪生体;
- 多个小模型可以分工协作:某个模型专门做涡轮机异常检测,另一个做排产优化,再一个做需求预测,最终都接入同一个仿真环境。
三、AI 与工作的未来
关于“AI 抢工作”的标题很多,但数据呈现出的图景更复杂:既不是全面乐观,也不是灾难降临,而是 结构性、渐进式的重塑。
1. AI 会取代工作吗?
世界经济论坛在《2025 未来就业报告》中,调研了 1000 多家大型雇主,预测:
- 2025–2030 年间,将创造约 1.7 亿个新岗位;
- 同期约 9200 万个岗位被替代或消失;
- 净增 7800 万个岗位。
整体是正向的,但分布极不均衡。MIT 与波士顿大学 2025 年的一项研究估计,到 2026 年,约 200 万制造业工人 将被 AI 与自动化取代。
更准确的表述是:
AI 更常“自动化任务”,而不是“一次性消灭整个岗位”。
会计不会凭空消失,但其大量时间将不再花在录入与对账上。MIT 2025 年的研究估算,目前可被自动化的任务约占美国整体劳动活动的 11.7%,对应约 1.2 万亿美元的工资规模。这并不等于 11.7% 的人失业,而是他们工作内容中有相当一部分可以变成“软件流程”。
更易被替代的岗位特征:
- 大量标准化、可预测的文本或表单处理(客服、数据录入)
- 规则清晰、流程固定的行政工作
- 部分零售收银岗位
- 以检索和整理为主的法律助理与基础研究工作
相对安全的岗位特征:
- 需要管理和协调他人(团队管理、项目统筹)
- 依赖高度专业判断(医生、资深律师、投行合伙人等)
- 频繁处理模糊、开放性问题
- 需要在不可预测的物理环境中工作(很多一线服务与技工岗位)
这些模式在医疗、技工、创意与战略决策等领域都适用。
2. 新兴职业路径
与此同时,一批五年前几乎不存在的岗位正在出现:
- AI 系统架构师:
- 负责设计 AI 组件如何嵌入组织流程;
- 既要懂技术,又要懂业务与合规。
- 提示工程师 / AI 协作专家:
- 从“写好提示词”演化为“设计人与 AI 的协作方式”;
- 重点在于理解模型行为边界,而非单纯追求“更聪明的输入”。
- AI 伦理与合规经理:
- 负责审查模型在隐私、公平、可解释性等方面的风险;
- 需要同时理解技术细节与法律框架。
- AI 训练师与数据策展人:
- 负责标注边缘案例、维护反馈闭环、管理训练数据质量。
总体规律是:领域知识 + AI 素养 = 新价值来源。
- 懂 AI 工具的护士,能更好地利用诊断辅助系统;
- 善用 AI 做检索与草拟的律师,在不牺牲质量的前提下工作更快。
雇主调研中,最受重视的能力依然是:
- 分析性思维
- 适应力与抗压能力
- 领导力与沟通协作
四、行业视角:代码、医疗与金融
不同领域对 AI 的吸收速度与效果差异巨大。软件开发、医疗与金融,是最具代表性的三个样本。
1. 编程与数据科学
软件开发是最早、也是最彻底拥抱 AI 工具的行业之一。
- Stack Overflow 2025 年调查显示,约 85% 的开发者 经常使用 AI 工具。
- GitHub 报告称,在使用 Copilot 的项目中,约 41% 的代码由 AI 参与生成。
如今的工具已经从“智能补全”进化到:
- 理解整个代码仓库;
- 跨多个文件进行修改;
- 自动生成测试与文档。
GitHub Copilot 目前约占 42% 市场份额,用户超过 2000 万,渗透进 90% 的《财富》100 强企业。新秀 Cursor 在 18 个月内拿下约 18% 市场份额,年经常性收入据称已达 5 亿美元级别。
AI 在以下类型的编码任务上表现尤佳:
- 模板化、重复性强的样板代码
- 快速试用陌生 API
- 阅读与解释遗留代码
但“感觉快”与“实际快”并不总是一致。METR 在 2025 年 7 月的一项研究中发现:
- 使用 Cursor Pro、Claude 3.5 Sonnet 等工具的资深开发者,完成任务的实际时间比不用 AI 慢了 19%;
- 但他们主观上认为自己“快了 20%”。
结论是:生产力提升高度依赖任务类型与使用方式。当你对系统本身比 AI 更熟悉时,强行让 AI 介入,反而可能拖慢节奏。
接下来,方向正从“AI 写几行代码”走向“AI 完成一个功能”:
- GitHub 的 Project Padawan 模式是:开发者把 Issue 分配给 AI,AI 实现,开发者只做 Code Review。
- 角色从“AI 给建议”转向“AI 先干,人类审核”。
对数据科学而言,趋势是:
- SQL 查询、数据清洗等“体力活”逐步交给 AI;
- 人类更多专注于:提出好问题、设计实验、解释结果与推动决策。
2. 医疗健康
医疗是 AI 潜力巨大、但必须极度谨慎的领域。
- 在药物研发上,AlphaFold 等工具将蛋白质结构预测从“几年”压缩到“数小时”;
- 化合物筛选规模大幅提升,有研究认为,AI 有望将单个新药的研发周期缩短 4–5 年。
在诊断方面,放射科、病理科、眼科等影像密集型领域进展最快:
- 大规模训练的影像模型可以发现人眼难以察觉的细微模式;
- 但医疗机构往往采用“AI 辅助 + 人类最终决策”的模式。
McKinsey 的研究指出,自 2016 年以来,Mayo Clinic 在部署数百个 AI 模型的同时,放射科团队规模反而扩张了 50% 以上——AI 并没有“替代医生”,而是让他们能处理更多、更复杂的病例。
谨慎的原因显而易见:
- 医疗决策的错误成本远高于社交媒体推荐;
- 医生与监管机构不仅关心“准不准”,还关心“为什么这么判断”。
短期内更现实的图景是:
- AI 作为“诊断助手”,负责初筛、标注可疑区域、提示可能被忽略的风险;
- 医生负责综合病史、检查结果与患者沟通,做最终决策。
随着小型语言模型上端侧设备:
- 可穿戴设备可以在本地处理生理信号;
- 只在检测到异常时上传少量摘要数据;
- 既降低延迟,又更好地保护隐私。
3. 金融服务
金融业很早就用 AI 做高频风控与欺诈检测,如今正借助智能体能力迈向新阶段。
- 传统系统已经能高效识别异常交易、自动处理大量客服问询;
- 新一代系统开始尝试 大规模个性化财富管理:根据个人风险偏好、收入结构与目标,生成定制化投资与储蓄方案。
与此同时,监管机构对算法的审查也在加强:
- 重点关注:AI 是否在无意中放大了历史数据中的歧视与偏见(如贷款审批中的地域、性别、种族偏差);
- 要求金融机构对模型决策过程有更高的可解释性与可追溯性。
五、技术瓶颈与监管博弈
AI 的技术限制与政策空白,直接决定了“能负责任地做什么”。黑箱问题、虚假内容与碎片化监管,是当前最突出的三大挑战。
1. 技术与社会问题
黑箱问题 依然没有根本解决:
- 大模型在做出决策时,很难解释“具体是哪些特征、哪段训练数据”驱动了这个结果;
- 当决策关系到贷款、就业、医疗等高风险场景时,这种不可解释性就变得难以接受。
斯坦福 HAI 预计,2026 年会有更多研究投入到所谓的 “高性能神经网络考古学”:
- 通过稀疏自编码器等技术,尝试从模型内部结构中挖掘“可解释的概念单元”;
- 追踪哪些模式真正影响了输出行为。
另一方面,生成内容带来的问题日益严峻:
- 深度伪造(Deepfake) 与 AI 生成谣言越来越难以肉眼识别;
- 有估计认为,互联网上 AI 生成的文本数量,已经在某些领域超过人类原创内容。
这又引出了 模型塌缩(Model Collapse) 的风险:
- 当新一代模型越来越多地以“AI 生成内容”作为训练数据;
- 错误与偏差会在自循环中被放大,整体质量逐步下降。
2. 监管版图:欧盟与美国的分化
欧盟:以风险为中心的统一框架
- 《EU AI Act》是目前最全面的 AI 法规之一;
- 采用“风险分级”思路:
- 最低风险:如娱乐类应用,要求较少;
- 高风险:如招聘、信贷、教育、医疗等,需满足严格的文档、监控与人类监督要求;
- 某些用途(如社会评分)则被直接禁止。
该法案已于 2024 年 8 月 1 日正式生效,但具体义务会在之后数年分阶段落地。
在能源与算力方面:
- 通用大模型提供方可能被要求披露能耗数据,或基于计算量给出合理估算;
- 与 AI Act 配套的,还有数据中心与能效方面的更严格报告要求——这对高能耗的 AI 训练与推理尤为关键。
这在实践中推动了一个趋势:
从“追求极致性能的大模型”,转向“够用就好、强调效率”的架构。
- 更多使用小模型与边缘推理,减少昂贵云端调用的 Token 数量;
- 同时降低算力成本、电力消耗与数据传输压力。
美国:联邦立法停滞,州级碎片化
- 联邦层面的综合性 AI 法案迟迟难以通过;
- 2025 年试图以联邦立法统一各州规则的努力也告失败;
- 结果是:
- 企业在 2026 年前后面临的是 “按州合规” 的移动靶,而非统一标准;
- 对跨州运营的 AI 产品与服务来说,合规成本与不确定性显著上升。
六、如何为 AI 未来做准备
在这样一个快速演化的环境中,个人和组织该如何保持“不过时”?可以从三个层面着手:数据与 AI 素养、技术基础、领域深度 + 智能体实践。
1. 数据与 AI 素养
数据素养已经不再是“数据岗位”的专属要求,而是大多数知识工作者的基础能力:
- 理解数据从采集到决策的流转过程;
- 知道什么样的数据是“可信的”;
- 能看懂模型输出,并判断其适用边界。
对于非技术背景的人来说,一个务实的路径是:
- 先系统学习数据基础(统计思维、可视化、数据质量);
- 再了解主流 AI 概念(监督学习、生成式模型、偏差与公平等)。
2. 技术基础:Python 与 SQL 仍是“日常工具”
AI 工具确实降低了写代码的门槛,但 理解代码逻辑 依然是区分“能用 AI”与“被 AI 牵着走”的关键。
建议的学习顺序:
- 先掌握一门脚本语言(如 Python)的基本语法与数据结构;
- 再学习如何通过 API 调用大模型、如何处理结构化数据(SQL);
- 最后再叠加“如何用 AI 辅助写代码”,而不是一上来就完全依赖 AI。
这样,当 AI 给出错误或不合适的代码时,你有能力识别并修正。
3. 领域专长 + 智能体设计
真正的价值不在于“谁会写更花哨的提示词”,而在于:
谁能把 AI 智能体 嵌入具体业务流程,并让它与真实系统安全协作。
这需要两方面的结合:
- 深刻理解某个领域的业务逻辑(医疗、制造、金融、教育等);
- 理解智能体的能力边界与集成方式(工具调用、权限控制、回滚机制等)。
一个非常实用的练习是:
- 选定你所在或感兴趣的一个具体流程(例如:保险理赔、工单分派、供应链补货);
- 画出当前的人工流程图;
- 标出哪些环节可以由智能体接手,哪些必须保留人工审核;
- 再思考:需要暴露给智能体哪些 API?如何记录与审计它的行为?
4. 学会与不确定性共处
大模型的输出本质上是 概率性的,因此:
- 它们有时会自信地给出错误答案;
- 在训练数据稀缺或偏差严重的领域,错误率会显著上升。
对任何构建 AI 产品的人来说,必须熟悉:
- 常见失败模式(幻觉、过拟合、数据漂移、模型塌缩等);
- 深度伪造的生成机制与检测方法;
- 如何设计“人类在环(Human-in-the-loop)”的安全网。
与其追逐每一波宣传,不如多关注一线工程师与研究者在会议和技术博客中分享的“踩坑经验”:那里往往比营销材料更接近真实世界。
结语:从“布道”到“评估”
斯坦福学者将当下的 AI 阶段概括为:
从 Evangelism(布道) 走向 Evaluation(评估)。
我们已经基本不再争论“AI 到底重不重要”,而是开始认真讨论:
- 它 在哪些场景真正创造价值?
- 代价和风险是什么?
- 怎样以可控、可审计的方式部署?
AGI 时间表依旧扑朔迷离,监管环境也在不断变化,但几个方向已经相当清晰:
- 自主智能体会逐步进入企业核心流程;
- 小型模型与边缘推理会承担大量日常任务;
- 人与 AI 的关系更多是 “增强”而非“替代”。
最值得期待的未来,并不是“AI 什么都能做”,而是:
人类学会设计系统,让 AI 放大我们的判断力与创造力。
在这种未来里,最好的策略很朴素:
- 主动上手使用这些工具,而不是刻意回避;
- 对“神话式乐观”和“末日式悲观”都保持适度怀疑;
- 把学习当成一个持续过程,而不是一次性任务。
变化无论如何都会发生,与其被动应对,不如尽早坐到“驾驶位”上。


