随着 SKILL.md 在各类智能体开发工具中被广泛采用,开发者对格式、YAML 写法和目录结构的关注度不断提高。当前,包括 Claude Code、Gemini CLI、Cursor 在内的三十余种工具,正逐步收敛到相似的目录规范,格式层面的差异正在缩小。
在此背景下,Skill 的核心难点开始从“写对格式”转向“设计好内容”。现有规范主要解决如何打包一个 Skill,却很少涉及如何在 SKILL.md 中组织逻辑、分配职责。实践中,一个仅封装 FastAPI 规范的 Skill,与一个包含四步文档生成流程的 Skill,从文件外观上几乎相同,但运行方式完全不同。
通过梳理 Anthropic 代码库、Vercel 与 Google 等团队的内部实践,可以看到一些共通的设计思路。基于这些案例,总结出五类在生态中反复出现的 Skill 设计模式,用于支撑更稳定、更可控的 Agent 行为:
- 工具封装(Tool Wrapper):将特定库或框架的知识打包成可按需加载的能力
- 生成器(Generator):围绕模板组织输出,保证文档结构统一
- 审查器(Reviewer):将审查标准外置,按清单执行检查
- 反转(Inversion):由 Agent 主动发问,先收集信息再行动
- 流水线(Pipeline):以多步骤工作流和检查点约束复杂任务
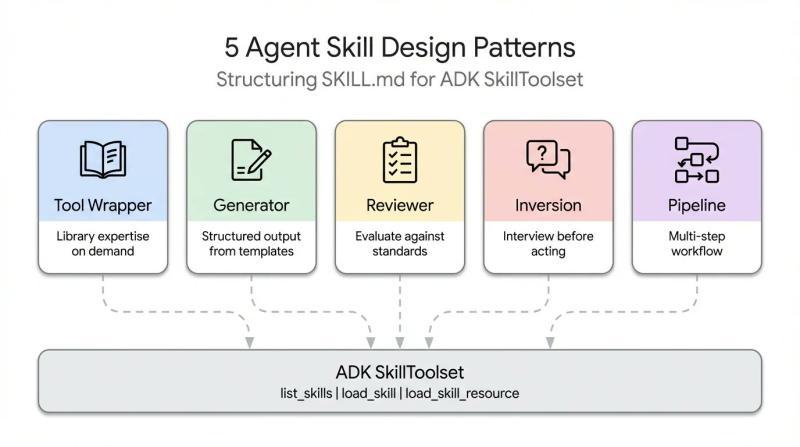
以下内容结合可运行的 ADK 示例,对五种模式逐一说明。
模式一:工具封装(Tool Wrapper)
工具封装模式的目标,是让 Agent 能够在需要时获取某个库或框架的上下文,而不是把所有规范一次性写进系统提示。相关知识被打包进一个独立 Skill,只有在任务确实涉及该技术时才被加载。
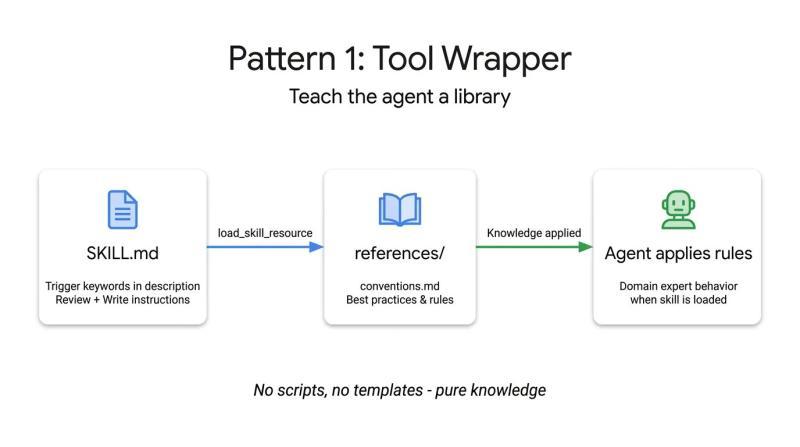
在实现上,这类 Skill 通常通过 SKILL.md 监听用户提示中的特定关键词,然后从 references/ 目录按需加载内部文档,将其中的规则视为“硬约束”。这种方式适合在团队内分发内部编码规范、框架最佳实践等,让 Agent 在合适的时机自动应用这些规则。
下面的示例展示了一个针对 FastAPI 的工具封装 Skill。它通过 conventions.md 提供完整规范,并在审查或编写代码时才加载该文件:
skills/api-expert/SKILL.md
name: api-expert description: FastAPI 开发最佳实践与规范。在构建、审查或调试 FastAPI 应用、REST API 或 Pydantic 模型时使用。 metadata: pattern: tool-wrapper domain: fastapi
你是 FastAPI 开发专家。将以下规范应用于用户的代码或问题。
核心规范
加载 'references/conventions.md' 获取完整的 FastAPI 最佳实践列表。
审查代码时
- 加载规范参考文件
- 对照每条规范检查用户代码
- 对于每处违规,引用具体规则并给出修复建议
编写代码时
- 加载规范参考文件
- 严格遵循每条规范
- 为所有函数签名添加类型注解
- 使用 Annotated 风格进行依赖注入
模式二:生成器(Generator)
生成器模式关注的是“输出长什么样”。当开发者希望 Agent 每次生成的文档在结构上保持一致时,可以通过模板和风格指南来约束输出,而不是完全依赖模型自由发挥。
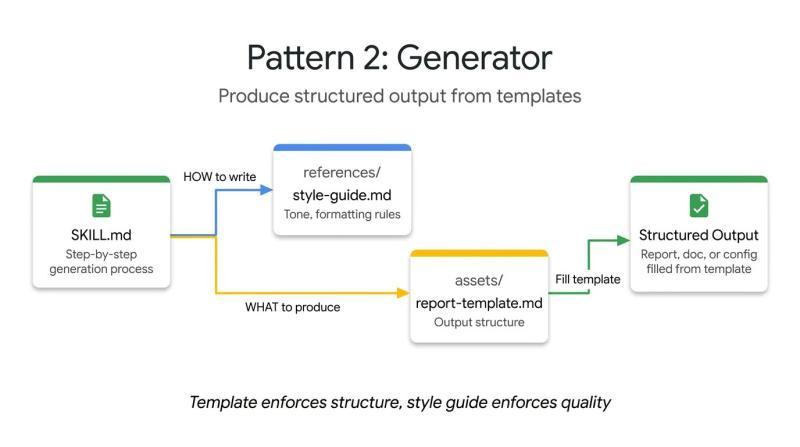
在目录结构上,生成器模式通常会使用两个可选目录:
assets/:存放输出模板,例如报告骨架、API 文档结构等references/:存放风格指南,如语气、格式规则
SKILL.md 中的指令负责协调这些资源:加载模板、读取风格指南、向用户询问缺失变量,再按步骤填充文档。这种模式适用于生成技术报告、标准化提交信息、搭建项目骨架等需要“可预期结构”的场景。
以下是一个技术报告生成器 Skill 的示例。Skill 本身不直接写死布局,而是通过步骤控制模板和风格的使用:
skills/report-generator/SKILL.md
name: report-generator description: 生成 Markdown 格式的结构化技术报告。当用户要求撰写、创建或起草报告、摘要或分析文档时使用。 metadata: pattern: generator output-format: markdown
你是一个技术报告生成器。严格按照以下步骤执行:
第一步:加载 'references/style-guide.md' 获取语气和格式规则。
第二步:加载 'assets/report-template.md' 获取所需的输出结构。
第三步:向用户询问填充模板所需的缺失信息:
- 主题或议题
- 关键发现或数据点
- 目标受众(技术人员、管理层、普通读者)
第四步:按照风格指南规则填充模板。模板中的每个章节都必须出现在输出中。
第五步:以单个 Markdown 文档的形式返回完成的报告。
模式三:审查器(Reviewer)
审查器模式将“检查流程”与“检查内容”解耦。Skill 负责规定审查步骤和输出结构,而具体要检查哪些问题,则由外部清单文件定义。
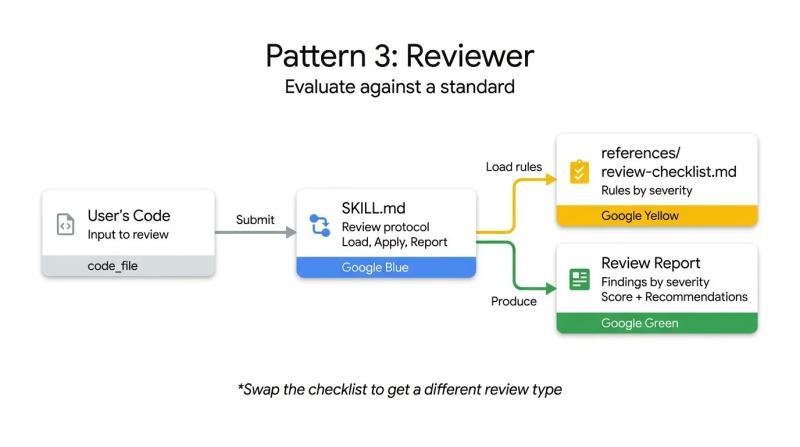
在这种模式下,诸如代码坏味道、安全风险等检查项不会直接写进系统提示,而是集中存放在 references/review-checklist.md 中。Agent 在执行审查任务时加载这份清单,逐条应用到用户提交的代码上,并按严重程度整理结果。
如果将清单内容从 Python 风格规范替换为 OWASP 安全清单,在不改动 Skill 结构的前提下,就可以得到一个安全审计工具。这种模式适合自动化 PR 审查、预先发现潜在问题等场景。
下面的代码审查 Skill 展示了这一思路。指令保持稳定,审查标准则通过外部文件动态注入:
skills/code-reviewer/SKILL.md
name: code-reviewer description: 审查 Python 代码的质量、风格和常见 Bug。当用户提交代码请求审查、寻求代码反馈或需要代码审计时使用。 metadata: pattern: reviewer severity-levels: error,warning,info
你是一名 Python 代码审查员。严格遵循以下审查流程:
第一步:加载 'references/review-checklist.md' 获取完整的审查标准。
第二步:仔细阅读用户的代码。在批评之前先理解其目的。
第三步:将清单中的每条规则应用于代码。对于发现的每处违规:
- 记录行号(或大致位置)
- 分类严重程度:error(必须修复)、warning(应该修复)、info(建议考虑)
- 解释为什么这是问题,而不仅仅是说明是什么问题
- 给出包含修正代码的具体修复建议
第四步:生成包含以下章节的结构化审查报告:
- 摘要:代码的功能描述,整体质量评估
- 发现:按严重程度分组(先列 error,再列 warning,最后列 info)
- 评分:1-10 分,附简短说明
- 三大建议:最具影响力的改进措施
模式四:反转(Inversion)
在默认交互中,用户给出任务,Agent 立即尝试生成答案。反转模式改变了这一流程:Agent 不再直接执行,而是先扮演“采访者”,通过多轮提问收集上下文,待信息完整后再进入生成阶段。
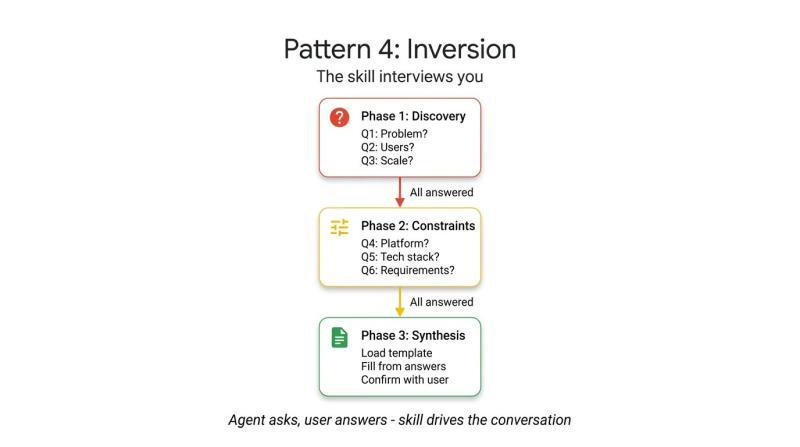
反转模式依赖明确的门控指令,例如“在所有阶段完成之前不得开始构建”,以此阻止 Agent 在需求不清晰时提前下结论。Skill 会按既定顺序提出问题,每次只问一个,等待用户回答后再继续。只有在所有问题都得到回应后,才允许进入综合输出阶段。
下面是一个项目规划 Skill 的示例。它通过阶段划分和门控提示,确保在生成方案前先完成需求访谈:
skills/project-planner/SKILL.md
name: project-planner description: 通过结构化提问收集需求,然后生成计划,从而规划新软件项目。当用户说"我想构建"、"帮我规划"、"设计一个系统"或"启动新项目"时使用。 metadata: pattern: inversion interaction: multi-turn
你正在进行一次结构化需求访谈。在所有阶段完成之前,不得开始构建或设计。
第一阶段——问题发现(每次只问一个问题,等待每个回答)
按顺序提问,不得跳过任何问题。
- Q1:"这个项目为用户解决什么问题?"
- Q2:"主要用户是谁?他们的技术水平如何?"
- Q3:"预期规模是多少?(每日用户数、数据量、请求频率)"
第二阶段——技术约束(仅在第一阶段完全回答后进行)
- Q4:"你将使用什么部署环境?"
- Q5:"你有技术栈要求或偏好吗?"
- Q6:"有哪些不可妥协的要求?(延迟、可用性、合规性、预算)"
第三阶段——综合(仅在所有问题都回答后进行)
- 加载 'assets/plan-template.md' 获取输出格式
- 使用收集到的需求填充模板的每个章节
- 向用户呈现完成的计划
- 询问:"这份计划是否准确反映了你的需求?你想修改什么?"
- 根据反馈迭代,直到用户确认
模式五:流水线(Pipeline)
当任务本身由多个环节组成,且每一步都不能被跳过时,流水线模式可以通过“硬性步骤”和“检查点”来约束 Agent 的执行顺序。
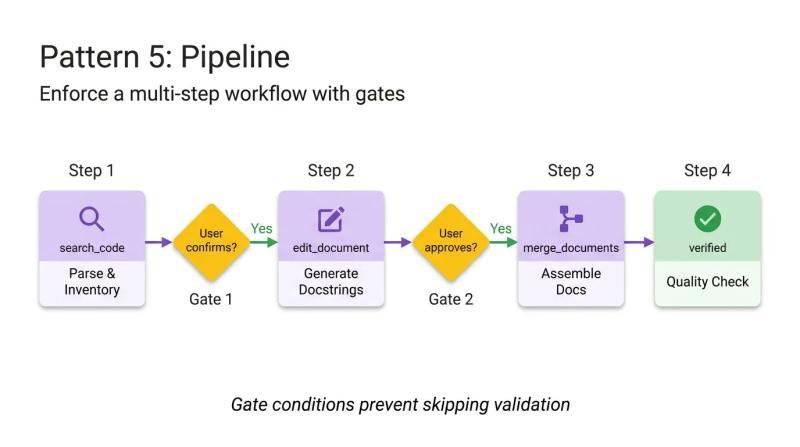
在流水线模式中,SKILL.md 同时扮演“工作流定义”的角色。每个步骤的输入、输出和门槛条件都在指令中写明,例如要求用户确认上一阶段结果后才能继续。这样可以避免 Agent 直接跳到最终答案,绕过中间的验证环节。
这一模式通常会结合多个目录:在不同步骤按需加载不同的参考文件和模板,以减少对上下文窗口的占用。
下面的示例展示了一个从 Python 源码生成 API 文档的四步流水线。关键在于第二步与第三步之间的门控条件:
skills/doc-pipeline/SKILL.md
name: doc-pipeline description: 通过多步骤流水线从 Python 源代码生成 API 文档。当用户要求为模块编写文档、生成 API 文档或从代码创建文档时使用。 metadata: pattern: pipeline steps: "4"
你正在运行一个文档生成流水线。按顺序执行每个步骤。不得跳过步骤,步骤失败时不得继续。
第一步——解析与清点
分析用户的 Python 代码,提取所有公开的类、函数和常量。以清单形式呈现清点结果。询问:"这是你想要文档化的完整公开 API 吗?"
第二步——生成文档字符串
对于每个缺少文档字符串的函数:
- 加载 'references/docstring-style.md' 获取所需格式
- 严格按照风格指南生成文档字符串
- 逐一呈现生成的文档字符串供用户确认 在用户确认之前,不得进入第三步。
第三步——组装文档
加载 'assets/api-doc-template.md' 获取输出结构。将所有类、函数和文档字符串编译成单一的 API 参考文档。
第四步——质量检查
对照 'references/quality-checklist.md' 进行审查:
- 每个公开符号都已文档化
- 每个参数都有类型和描述
- 每个函数至少有一个使用示例 报告结果。在呈现最终文档之前修复所有问题。
如何选择合适的模式
不同模式对应不同类型的问题。开发者可以根据目标,选择最贴合的设计方式:
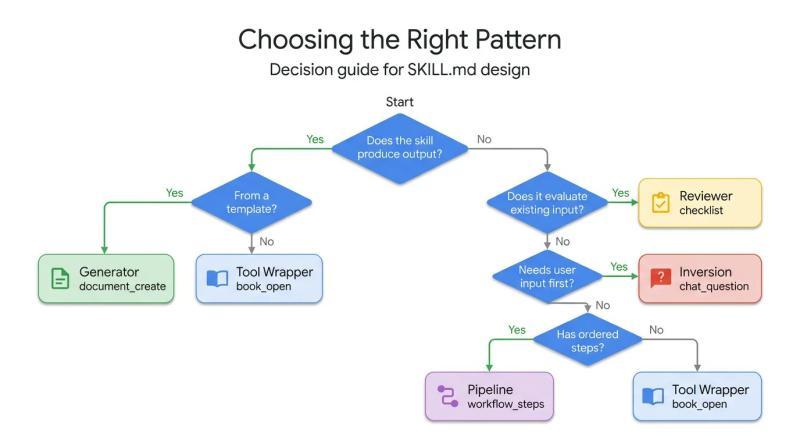
- 关注“如何让 Agent 掌握特定库或框架”:适合使用工具封装模式
- 关注“如何保证文档结构统一”:适合使用生成器模式
- 关注“如何自动化代码审查或安全审计”:适合使用审查器模式
- 关注“如何避免在需求不清晰时乱猜”:适合使用反转模式
- 关注“如何确保复杂任务的每一步都被执行”:适合使用流水线模式
模式可以组合使用
上述五种模式并非互斥,实际项目中往往会组合使用:
- 流水线可以在末尾增加一个审查器步骤,对自身输出进行质量检查
- 生成器可以在开始阶段引入反转模式,先通过多轮提问收集变量,再填充模板
借助 ADK 的 SkillToolset 与递进式披露机制,Agent 可以在运行时按需加载不同 Skill,只为当前任务真正需要的模式消耗上下文资源。
在 Skill 设计上,将复杂、易碎的长提示拆解为结构化模式,有助于构建更可靠、更易维护的 Agent 工作流。


